Los métodos tradicionales de monitorización, por su falta de granularidad en los datos de telemetría, suelen pasar por alto los problemas más difíciles de detectar, como el impacto de un rendimiento intermitente. Esta falta de visibilidad total dificulta la resolución de problemas y hace que éstos duren más tiempo de lo que los usuarios consideran razonable.
Para ayudar a los equipos de TI a resolver problemas que afectan a los servicios fundamentales de red y a sus rutas de extremo a extremo, presentamos la monitorización continua de ThousandEyes para pruebas en intervalos de un minuto. La monitorización continua proporciona al equipo de TI datos frecuentes con detalles sobre sus redes, de forma que podrán detectar errores y problemas de rendimiento intermitente e informar a los equipos más rápidamente.
Monitorización granular para el rendimiento de la red
Con los modos de prueba predeterminados, ThousandEyes envía una ráfaga de paquetes al principio del intervalo de pruebas. Aunque esta metodología es adecuada y cumple con una amplia gama de acuerdos de nivel de servicio y monitorización (SLA), a veces es necesario aplicar una mayor frecuencia de pruebas en algunos servicios y rutas fundamentales para encontrar irregularidades en la red que puedan pasar desapercibidas y para captar e identificar problemas transitorios más rápidamente.
ThousandEyes presenta el poder de la monitorización granular con la función de monitorización continua para las pruebas en intervalos de un minuto. Esta función forma parte de nuestra plataforma y ofrece detección en un segundo para identificar fallos rápidamente, de forma que los clientes pueden monitorizar cualquier SLA sin importar su dificultad. También proporciona análisis de pérdida de paquetes con visualización en intervalos de un segundo a los equipos de TI para una resolución de problemas más rápida.
El modo de monitorización continua está disponible para las pruebas de agentes a servidores y envía el tráfico sintético cada segundo del intervalo de un minuto de la prueba. Las dos ventajas principales de la monitorización continua son: (1) detección rápida de fallos para una respuesta más inmediata de los equipos de operaciones de TI y (2) validación continua de la calidad de la ruta de la red para detectar problemas de rendimiento intermitente que son difíciles de encontrar.
La monitorización continua mejora el rendimiento de los equipos operativos de varias formas:
- Respuesta más rápida: la mayor granularidad de datos capta inmediatamente si el rendimiento empeora y permite que los equipos reaccionen para identificarlo y responder rápidamente.
- Menor resolución de problemas: las pruebas de rendimiento al segundo detectan picos intermitentes de pérdida de red en las rutas de extremo a extremo, de forma que se reducen las dificultades operativas que se generan para identificar los problemas transitorios que afectan a los SLA.
- SLA mejorados: pruebas continuas cada segundo de las rutas de red fundamentales que contribuyen a garantizar el funcionamiento continuo de la red
Configuración simplificada
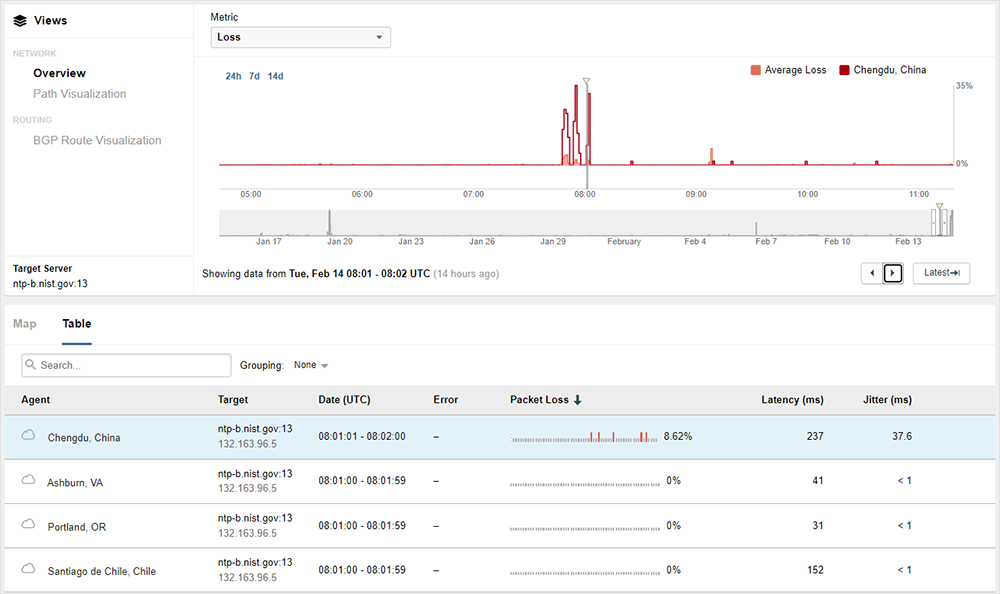
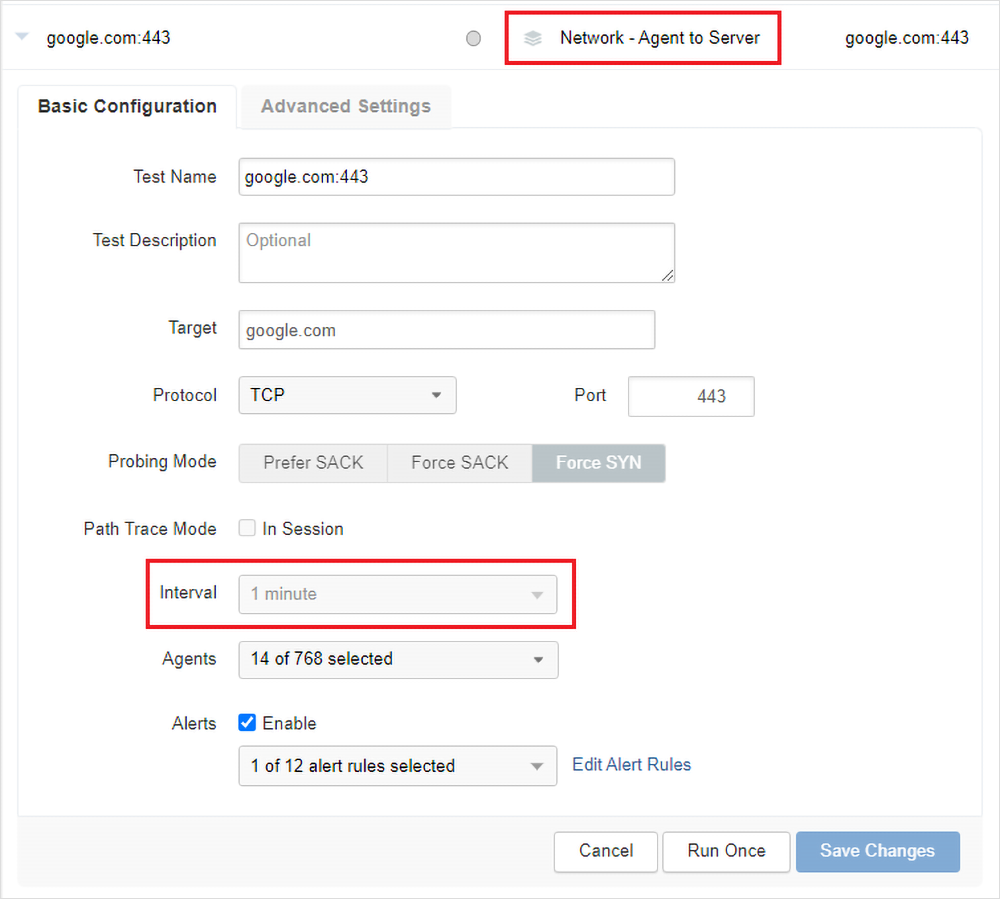
Como se ha mencionado antes, la monitorización continua está disponible para pruebas de red en intervalos de un minuto de agente a servidor de ThousandEyes. La figura 2 a continuación muestra dónde pueden comprobar los clientes que se haya seleccionado la prueba y el intervalo adecuados.
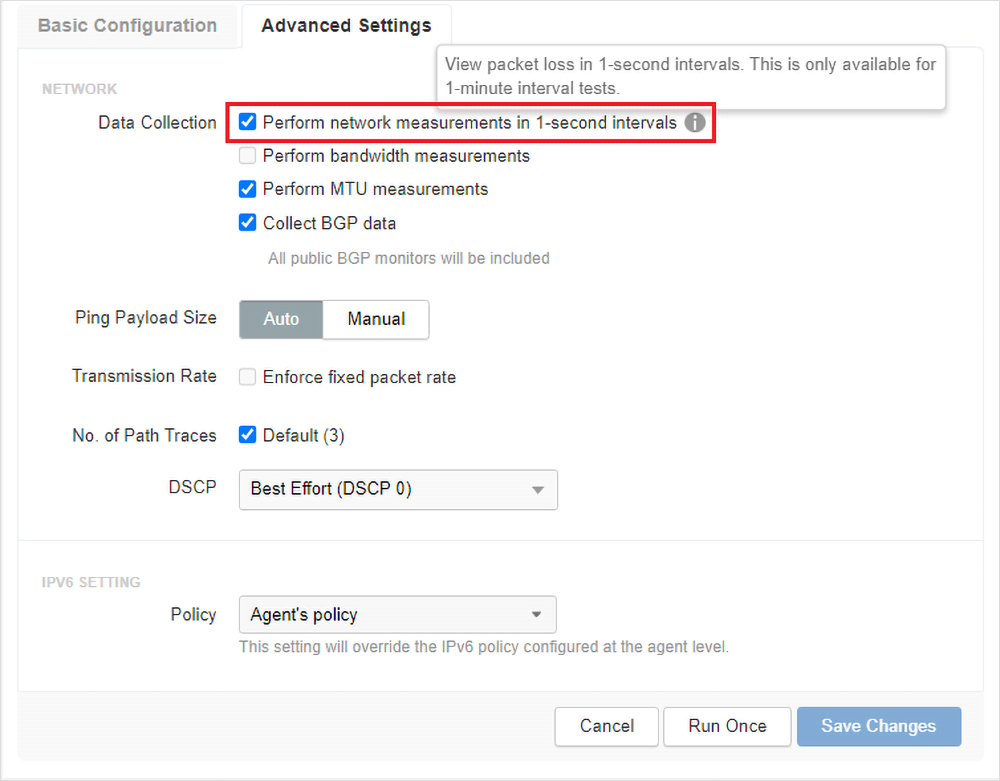
La configuración de monitorización continua se ha simplificado y se activa para cada prueba con solo marcar una casilla en la pestaña Configuración avanzada, como se muestra en la figura 3.
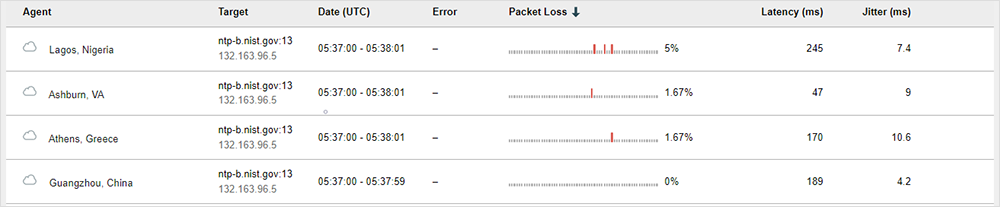
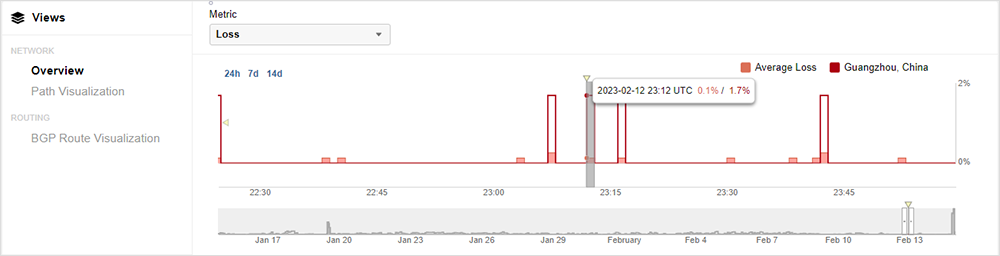
Los clientes pueden ver métricas de pérdidas con un micrográfico disponible para las pruebas de monitorización continua, donde se identifica el lugar de la pérdida de paquetes con el intervalo de 1 minuto de la prueba.
Cómo funciona la monitorización continua
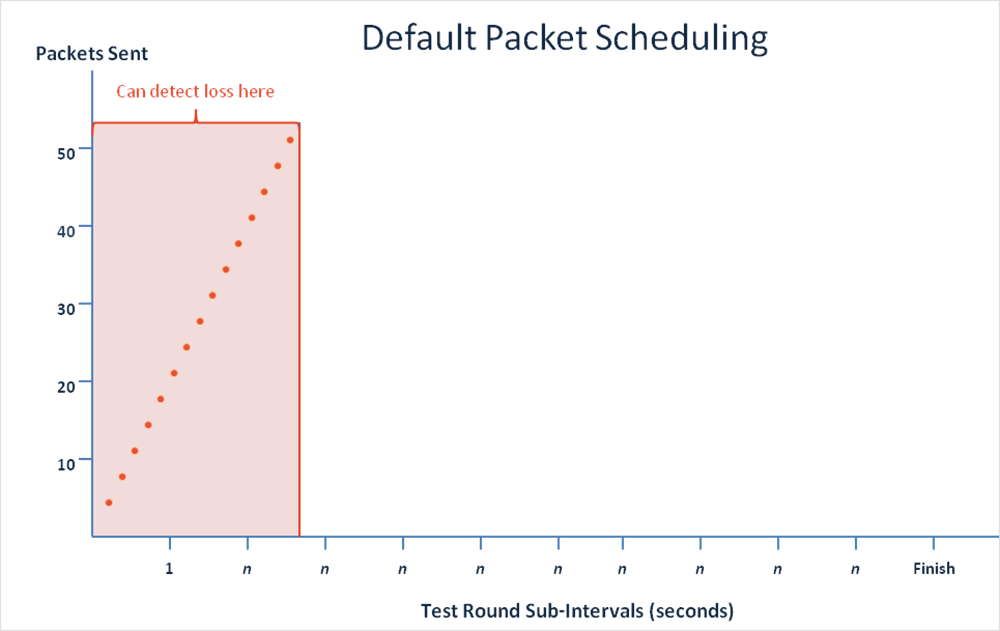
ThousandEyes se sirve de un algoritmo que programa paquetes para enviar paquetes de prueba durante un intervalo determinado. Por defecto, la plataforma envía numerosos paquetes al inicio de cada intervalo y espera a que llegue el siguiente intervalo para enviar otro montón de paquetes. Este mecanismo es muy bueno para captar problemas persistentes y se ilustra en el siguiente gráfico.
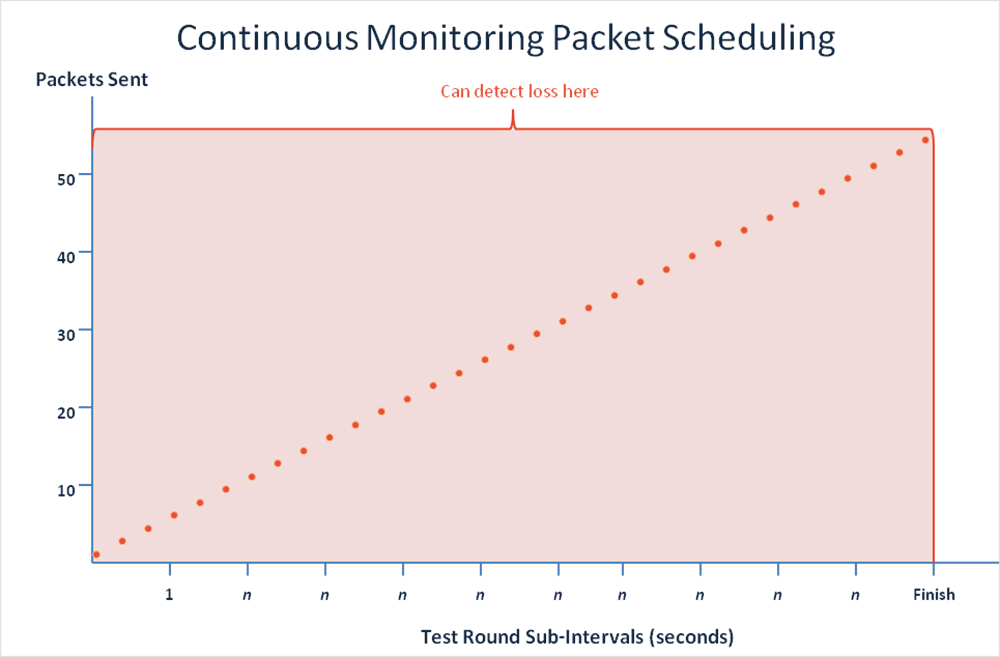
Nuestro algoritmo de programación de paquetes se ha modificado para dispersar los paquetes a través del intervalo de la prueba e implementar la monitorización continua en una cobertura más amplia. Los resultados de todos los paquetes se agregan en un único punto de datos. La figura 6 ilustra este cambio en el programador de paquetes para las pruebas de monitorización continua.
Las pruebas en modo continuo usan una vista ampliada en minigráfico de 1 minuto para las métricas de pérdida de paquetes, de forma que los clientes pueden identificar de forma precisa los subintervalos en los que se perdieron los paquetes. Por ejemplo, el diagrama de la figura 7 a continuación ilustra un intervalo de prueba de 1 minuto con 9 segundos o subintervalos de pérdida de paquetes y 51 subintervalos sin pérdidas. Esto da como resultado un 15 % de pérdida de paquetes para este intervalo de prueba de 1 minuto.

Casos de uso de granularidad de datos en operaciones de TI
La granularidad de los datos es fundamental para el buen funcionamiento de muchas aplicaciones modernas; no obstante, para obtenerla se necesitan funciones de pruebas precisas. En la monitorización de la red, este requisito crea la necesidad de medir continuamente el rendimiento de la red. Los equipos de TI se esfuerzan por mejorar tanto el MTTR (tiempo medio de reparación) como el tiempo medio entre fallos (MTBF), y aun así, es muy difícil mejorar este último. La detección rápida de fallos y los datos de red en tiempo real contribuyen a la restauración de servicios cuando se debilitan y a la mejora continua del rendimiento de la infraestructura con el tiempo.
Conocer la forma y el momento de aprovechar los datos de la red en tiempo real depende de los acuerdos de nivel de servicio, la aplicación y otros criterios del negocio. Un ejemplo lo encontramos en los flujos de TCP. Incluso las cantidades muy pequeñas de pérdida de paquetes afectan a los flujos de TCP, dando lugar a una ralentización de la transferencia de datos de TCP y la necesidad de retransmisión de los datos perdidos. En algunas aplicaciones que no toleran la pérdida, el impacto puede ser incluso más significativo. Algunos casos de uso de la monitorización continua son:
- detección de fallos en un gran ancho de banda, rutas de baja latencia
- monitorización de microservicios fundamentales
- monitorización de enlaces de WAN o la red fundamental
- monitorización de microinterrupciones en el estado de la ruta
- cualquier situación en la que la detección y la respuesta rápidas a los aspectos que afectan al rendimiento sea algo fundamental para el negocio
ThousandEyes se diseñó para ayudar a los equipos a diagnosticar, aislar y evaluar los errores más rápidamente y con menor incertidumbre. Los equipos de TI, ya sean de operaciones, SRE o NOC se benefician de la visibilidad por capas de ThousandEyes para detectar cualquier incidente que afecte al rendimiento de su infraestructura fundamental o a sus servicios digitales. La monitorización continua va más allá de estos objetivos, como explicamos en los siguientes apartados.
Caso de uso 1: Detección granular de fallos para los equipos de operaciones de TI
El objetivo de cualquier miembro del equipo de operaciones de TI que se enfrente a una degradación de un servicio y empiece a recibir tickets es remediar o solucionar rápidamente los problemas y proporcionar actualizaciones a tiempo para las partes interesadas. No se puede romper el vínculo entre la detección del fallo y la notificación, y esperar un buen resultado. Es más, es necesario alertar a tiempo de problemas graves de rendimiento para desencadenar otros procesos operativos y definir acciones correctivas.
La monitorización continua de ThousandEyes ofrece una detección de fallos granular para su infraestructura de red, de forma que los equipos puedan reaccionar y movilizar rápidamente los recursos para abordar incluso las degradaciones de rendimiento más pequeñas que puedan afectar los SLA definidos. Así, las personas responsables de TI están seguras de que sus equipos pueden ajustarse a los estrictos SLA definidos con las partes interesadas en lo relativo a sus servicios fundamentales.
Por ejemplo, una degradación de tan solo el 2 por ciento de pérdida de paquetes sería inaceptable para algunas aplicaciones. En ese caso, la política empresarial podría requerir acciones como una conmutación por fallo de servicio o red, o alguna otra remediación. Captar esas degradaciones de forma rápida y precisa es esencial en esta situación. La monitorización continua ofrece visibilidad a los equipos de redes para que puedan detectar aspectos que afecten a los servicios que estén expuestos a pérdidas, incluso aunque sean leves.
Caso de uso 2: Aislar problemas de red transitorios
Los problemas intermitentes de la red son la pesadilla de las operaciones de TI, ya que son difíciles de detectar e identificar, los datos no se pueden recopilar fácilmente y son fuente de retos constantes para los equipos de TI. Estos problemas transitorios pueden terminar antes de que se llegue a movilizar un equipo o a recopilar todos los datos. Además, estos problemas suelen dar lugar al cierre repetido de tickets con el mensaje "no se ha encontrado ningún problema" para problemas recurrentes.
Si bien algunos incidentes recurrentes y de corta duración pueden afectar de forma considerable a los servicios críticos, como los servicios de voz que no toleran pérdidas o los sistemas de replicación de datos sensibles a la latencia, incluso los problemas transitorios de menor importancia pueden convertirse en un ruido que afecte con frecuencia a su equipo de operaciones y que consuma ciclos valiosos. Desgraciadamente, estos problemas tan escurridizos son frecuentes, y a veces requieren múltiples herramientas y horas del personal para investigarlos, para terminar a menudo sin una solución satisfactoria.
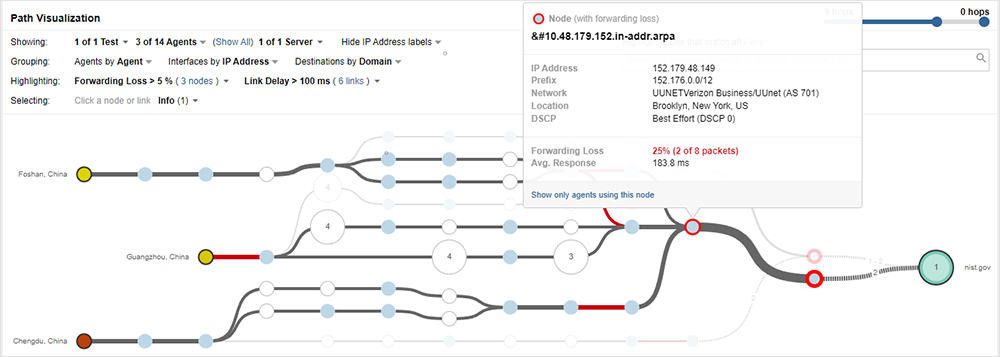
En lo relativo a los impactos intermitentes en el rendimiento, especialmente los que desaparecen rápidamente, la monitorización granular proporciona una red ampliada para detectar más problemas, como los problemas transitorios que se producen en intervalos aparentemente aleatorios. La monitorización continua detecta esas incidencias breves o infrecuentes y, lo que es más importante, captura y registra datos detallados de la red desde el momento de la incidencia. El resultado para los clientes de ThousandEyes es que sus equipos podrán identificar y aislar con precisión el momento y la ubicación en el que se producen los problemas transitorios.
Caso de uso 3: Detectar problemas ocultos de rendimiento
Garantizar una amplia visibilidad de red puede ser un reto constante para los equipos de TI, sobre todo en una infraestructura que no posee o no controla. La monitorización continua de ThousandEyes está diseñada para captar esos problemas persistentes, pero con niveles de pérdida bajos, y esas microinterrupciones que obstaculizan el rendimiento y degradan la experiencia de usuario.
Al calcular el rendimiento de red con granularidad de 1 segundo, los equipos de operaciones de TI pueden captar e identificar al instante hasta los problemas que, aunque sean pequeños, causan daños, y que suelen omitirse en las herramientas de monitorización que utilizan intervalos de sondeo tradicionales. Esta metodología de monitorización continua en tiempo real respalda la mejora de sus rutas de red fundamentales con el tiempo, de forma que ayuda a los equipos a que optimicen infraestructuras del perímetro y otros componentes de red que forman parte de la prestación del servicio de extremo a extremo.
Detectar el rendimiento real de la infraestructura de red fundamental contribuye a que las organizaciones conozcan en todo momento el valor verdadero de su red y de lo que están pagando, incluidos los servicios y redes de proveedores. Al reducir los vacíos en la monitorización del rendimiento, obtiene visibilidad para problemas que antes no podía ver, además de un buen marco operativo para identificar de forma fiable cualquier problema que surja.
Entender su estrategia de monitorización
Es fundamental contar con una estrategia de monitorización bien planeada para el buen funcionamiento de TI. Determinar qué objetivos supervisar, con qué tipo de prueba y a qué intervalos de prueba es algo que se debe considerar detenidamente La clave para conseguir una estrategia de monitorización efectiva es conocer sus SLA y sus expectativas en cuanto al servicio y a la aplicación. Los equipos no solo deben determinar las métricas, sino también la granularidad necesaria para garantizar buenas experiencias de usuario. Podrían tener que saber las degradaciones intermitentes con poca pérdida de determinadas aplicaciones y ser más flexibles con otros aspectos.
ThousandEyes ofrece una gama de opciones tácticas para monitorizar varias situaciones que cumplen con los objetivos de TI, ya sea una detección rápida de fallos, validaciones de SLA, tareas de control de calidad con cambios de gestión o cualquier otro caso de uso en el que la visibilidad profunda, práctica y a tiempo de la red de extremo a extremo sea esencial. La monitorización continua agrega una herramienta más a la plataforma que permite a los equipos de TI ampliar la cobertura de monitorización y facilita la garantía actual de rutas de red de extremo a extremo.









