Due to a lack of granularity in their telemetry data, traditional monitoring methods often miss elusive problems, such as intermittent performance impacts. This lack of comprehensive visibility can hinder issue resolution and thus prolong problems beyond what is considered reasonable by today's users.
To help IT detect and solve issues that impact critical network services and their end-to-end paths, we are introducing ThousandEyes Continuous Monitoring for One-Minute Interval Tests. Continuous monitoring gives IT more detailed and frequent data about their networks, enabling them to detect and notify teams of network faults and intermittent performance issues more quickly.
Granular Monitoring for Network Performance
With default testing modes, ThousandEyes sends a burst of packets at the start of each testing interval. While this methodology is well-suited for meeting a wide range of monitoring and service-level agreement (SLA) requirements, there is sometimes a need to apply more frequent testing for critical paths and services to find network blips that may otherwise go undetected and to catch and identify transient problems more quickly.
ThousandEyes brings the power of granular monitoring with Continuous Monitoring for One-Minute Interval Tests. This feature on our platform delivers one-second detection for quick fault identification, allowing customers to monitor any SLA, no matter how stringent. It also equips IT teams with a visualized packet loss analysis at one-second intervals for faster troubleshooting.
Continuous monitoring mode is available for agent-to-server tests and sends synthetic traffic every second of each one-minute test interval. Continuous monitoring provides two primary benefits: (1) rapid detection of faults for a more immediate ITOps response and (2) continuous validation of network path quality to discover difficult-to-find and intermittent network performance issues.
Continuous monitoring augments operational teams in several beneficial ways:
- Faster response—increased data granularity catches performance degradations as soon as they happen, enabling reactive teams to identify and respond quickly.
- Less troubleshooting—per-second performance testing finds brief or intermittent spikes of network loss across critical end-to-end paths, reducing operational headaches in identifying transient yet SLA-impacting issues.
- Improved SLAs—continual, 1-second performance testing of critical network paths helps to facilitate continuous network assurance
Streamlined Configuration
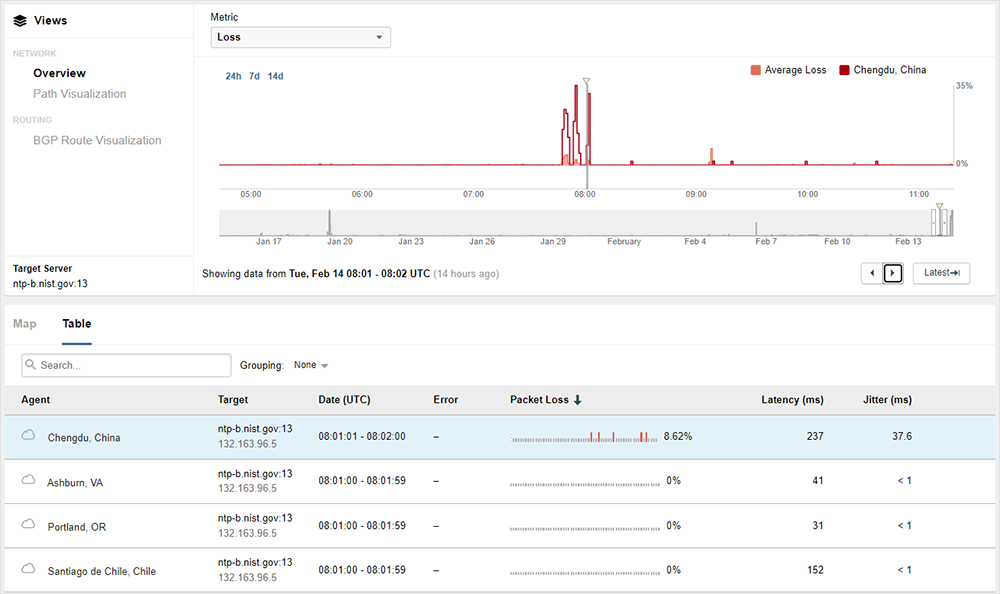
As noted above, continuous monitoring is available for ThousandEyes agent-to-server one-minute interval network tests. Figure 2 below shows where customers can check that the appropriate test and interval are selected.
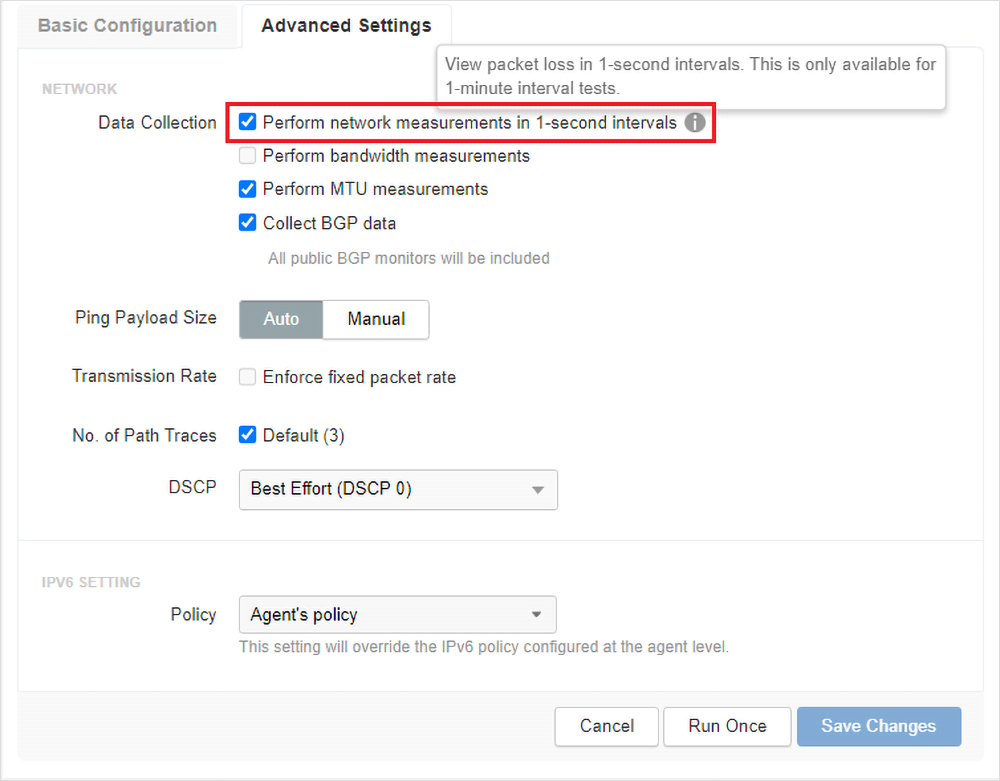
The continuous monitoring configuration is streamlined and enabled per-test by checking a single checkbox in the Advanced Settings tab, as shown in Figure 3.
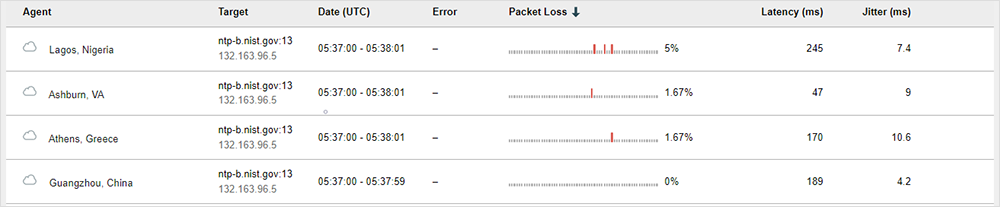
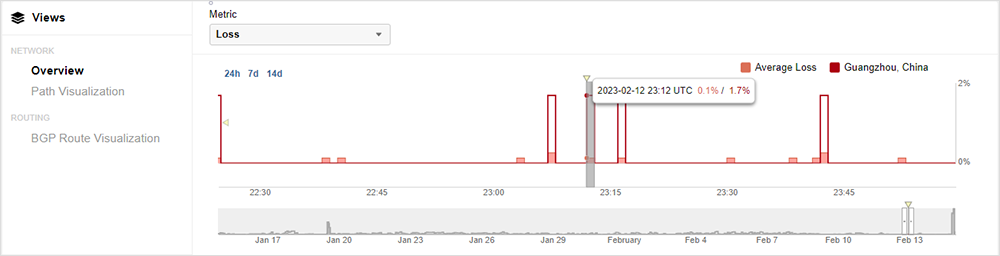
Customers can view loss metrics in a sparkline visualization that is provided for continuous monitoring tests, identifying where packet loss has occurred within the 1-minute test interval.
Continuous Monitoring: How Does It Work?
ThousandEyes uses a packet scheduling algorithm to send test packets during a designated test interval. The platform’s default behavior sends a burst of packets at the start of each interval and then waits for the next interval before sending another burst of packets. This mechanism performs well at catching sustained issues and is illustrated in the diagram below.
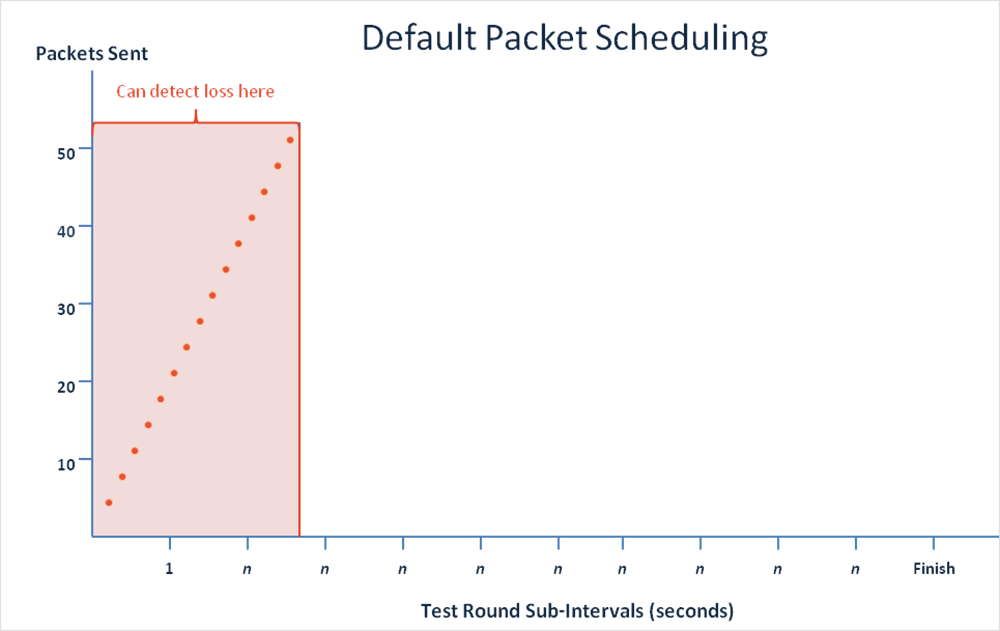
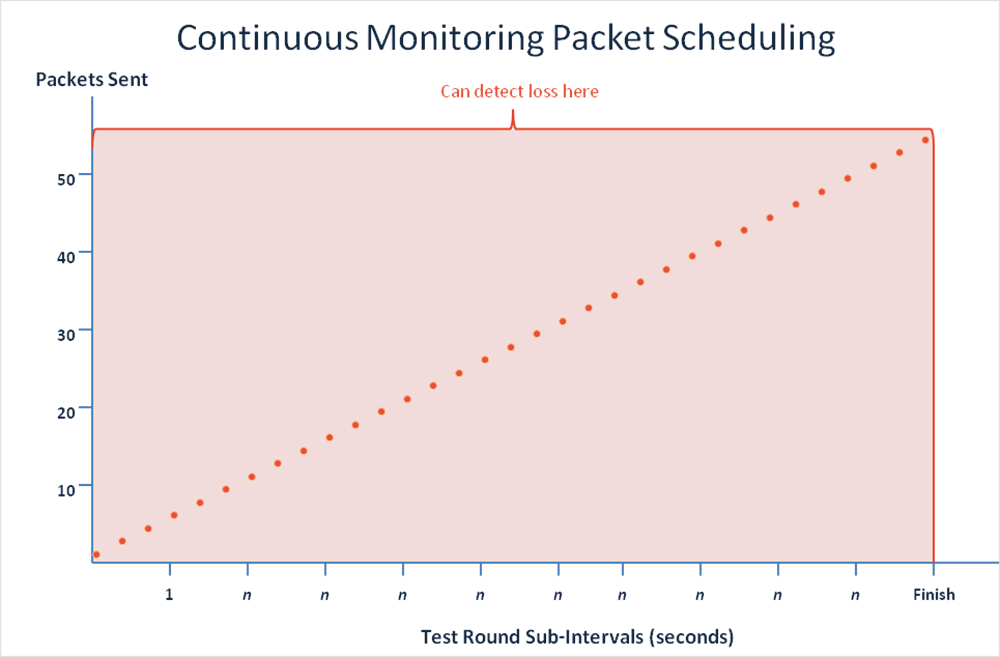
Our packet scheduling algorithm has been modified to spread the packets throughout the test interval to implement continuous monitoring for expanded coverage. The results from all packets are then aggregated into a single data point. Figure 6 illustrates this change to the packet scheduler for continuous monitoring tests.
Continuous mode tests utilize an expanded 1-minute sparkline view for packet loss metrics, allowing customers to identify where precisely in the subinterval packets were lost. For example, the diagram in Figure 7 below illustrates a 1-minute test interval with 9 seconds, or subintervals, of packet loss and 51 subintervals of no loss. This calculates to a 15% packet loss for this 1-minute test interval.

Use Cases for Data Granularity in ITOps
Data granularity is crucial to the success of many modern applications. But gaining data granularity requires precise testing capabilities. For network monitoring, this requirement creates a need for continual measurements of network performance. IT teams work hard to improve both MTTR (mean time to repair) and mean time between failures (MTBF), yet the latter can be a constant struggle to improve. Real-time network data and quick fault detection can help with the restoration of services when they falter, as well as with the continual improvement of infrastructure performance over time.
Knowing how and when to leverage real-time network data depends on the application, service-level agreements, and other business criteria. Case in point: TCP flows. Even tiny amounts of packet loss negatively impacting TCP flows result in a slowdown in TCP data transfer and require the retransmission of the lost data. For some loss-intolerant applications, the impact can be even more significant. Use cases for continuous monitoring include:
- fault detection for high bandwidth, low latency paths
- monitoring of critical microservices
- monitoring of critical network or WAN links
- monitoring for micro-disruptions to path health
- any scenario where the quick detection and response for performance impacts is essential to the business
ThousandEyes was built to help teams diagnose, isolate, and triage problems quicker and with less guesswork. IT teams from Ops to SRE to 24/7 NOCs benefit from ThousandEyes’ layered visibility to detect any hit to the performance of their critical infrastructure or digital services. Continuous monitoring furthers these goals, which we’ll elaborate on in the following sections.
Use case #1: Granular Fault Detection for ITOps
The goal of anyone in ITOps faced with degraded service and incoming service tickets is to quickly remediate or workaround problems and to provide timely updates to stakeholders. One cannot decouple fault detection from notification and expect a good outcome. Moreover, timely alerting of critical performance impacts is necessary to trigger additional operational processes and established corrective actions.
ThousandEyes continuous monitoring delivers granular fault detection for your network infrastructure, enabling reactive teams to mobilize quickly to address even minor performance degradations that affect defined SLAs. This gives IT leaders the confidence that their teams can adhere to the demanding SLAs established with stakeholders for their critical services.
For example, a degradation as low as 2 percent packet loss may be unacceptable for some applications. In such a case, the business policy may mandate actions like a network or service failover or some other remediation. Catching such performance degradations quickly and accurately is imperative in this scenario. Continuous monitoring provides network teams the visibility to detect any impacts to their loss-sensitive services—even only minor.
Use case #2: Isolate Transient Network Problems
Intermittent network problems are the bane of IT operations–troublesome to catch and identify, difficult to gather data on, and the source of ongoing challenges for IT teams. Such transient problems may be over before a team can be mobilized or data can be collected. Moreover, these problems often result in repeated tickets being closed with “no problem found” for recurring issues.
While some recurring, short-lived issues may cause sizable impacts to critical services, such as loss-intolerant voice services or latency-sensitive data replication systems, even minor transient problems can be noise that frequently hits your operations team and eats up valuable cycles. Unfortunately, such elusive problems are not uncommon, yet each time they may require multiple tools and hours of staff time to investigate, often without a successful resolution.
For intermittent performance impacts, especially ones that quickly clear, granular monitoring provides an expanded net to catch more problems, including transient issues that strike at seemingly random intervals. Continuous monitoring detects those brief or infrequent occurrences and, most importantly, captures and records detailed network data from the time of the event. The result for ThousandEyes customers is that their teams can identify and isolate precisely when and where transient problems occur.
Use case #3: Discover Elusive Performance Issues
Ensuring ample network visibility, especially across infrastructure you do not own or control, can be a constant challenge for IT teams. ThousandEyes continuous monitoring is designed to catch those persistent but low-loss level issues and those micro-disruptions that drain performance and degrade the user experience.
By measuring network performance with 1-second granularity, ITOps teams can readily catch and identify small but troublesome issues, i.e., those problems missed by monitoring tools using traditional polling intervals. This real-time methodology of continuous monitoring supports the improvement of your critical network paths over time by helping teams to optimize edge infrastructures and other network components of the end-to-end service delivery.
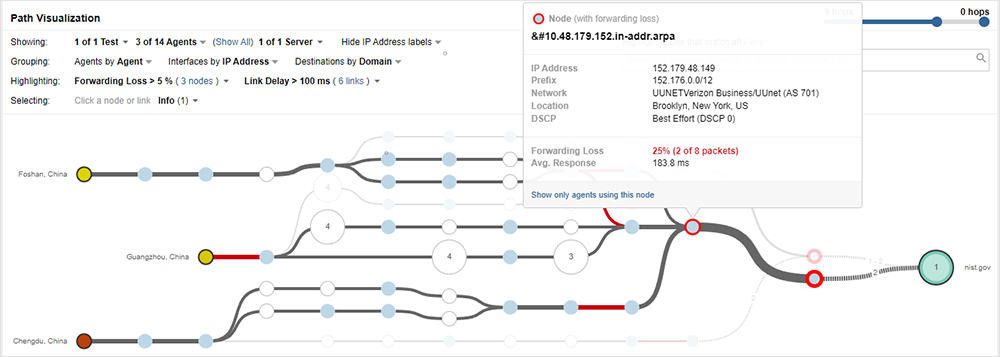
Discovering the true performance of critical network infrastructure helps organizations, in turn, know the true value of their network and what they are paying for, including provider networks and services. By shrinking the performance monitoring gap, you gain visibility on issues you did not have visibility into, along with a sound operational framework to identify reliably any new problems that develop.
Knowing Your Monitoring Strategy
A well-planned monitoring strategy is essential to IT success. Determining what targets to monitor, with what type of test, and at what testing intervals all need to be thoughtfully considered and purposely implemented. The key to an effective monitoring strategy is to know your SLAs and expectations on a per-application and per-service basis. Teams must not only determine what metrics but also the granularity that’s needed to assure good user experiences. I may need to know of intermittent, low-loss degradations for some applications, whereas I am more flexible for others.
ThousandEyes provides a range of tactical options to monitor various scenarios that meet IT goals, whether it’s rapid fault detection, SLA validations, change management quality assurance tasks, or any other use case where deep, actionable, and timely end-to-end network visibility is a must. Continuous monitoring adds an additional tool to the platform that enables IT teams to broaden monitoring coverage and helps facilitate ongoing assurance of end-to-end network paths.









