En lo que se refiere a monitorización de la infraestructura de TI, la monitorización de SNMP tradicional basada en dispositivos lleva bastante tiempo siendo la solución estándar. Sin embargo, a medida que avanza la tecnología, se deberían explorar enfoques alternativos que ofrezcan una visibilidad y resolución de problemas mejorada, en especial en la era de Internet.
En este blog no vamos a mencionar las soluciones de monitorización basadas en agentes o en el flujo a propósito; sino que analizaremos las diferencias clave entre las funciones de la monitorización de SNMP basada en dispositivos y la monitorización sintética de extremo a extremo que ofrecen plataformas como ThousandEyes. Con esta distinción, podremos apreciar mejor de qué manera la monitorización sintética de extremo a extremo complementa las estrategias de monitorización actuales para proporcionar mejores soluciones a casos de uso únicos, además de una ruta más clara para resolver problemas.
Las diferencias
Empezaremos definiendo los dos tipos de monitorización que vamos a abordar.
Qué es la monitorización SNMP?
- La monitorización del protocolo simple de administración de red (SNMP por sus siglas en inglés) recopila datos de métricas de determinados dispositivos, como las estadísticas de la interfaz, el uso de la memoria y de la CPU. Las compañías la usan principalmente para gestionar dispositivos particulares de una red, como routers, switches y servidores.
Qué es la monitorización sintética?
- La monitorización sintética de extremo a extremo de ThousandEyes reúne y analiza los datos de conexión entre varios puntos, con especial atención en la disponibilidad y el rendimiento de la red que se monitoriza. Nuestro enfoque integral abarca redes locales e Internet, y proporciona una visión más amplia del rendimiento y el estado de la red.
Estas diferencias entre las dos tecnologías de monitorización afectarán al enfoque de troubleshooting que tome la persona encargada de la administración de redes. Imaginemos una situación en la que hay un problema con la red, como un cable defectuoso, un switch o el puerto de un switch roto, o un router que falla.
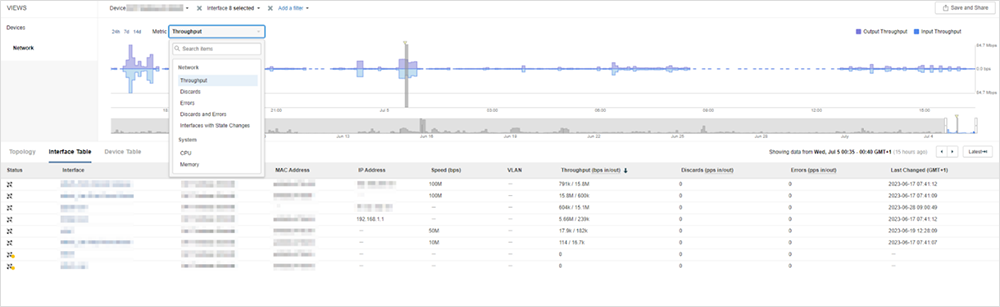
En esa situación, la monitorización basada en SNMP me enviaría una notificación en poco tiempo sobre cualquier dispositivo defectuoso o en caso de que la métrica de un dispositivo haya superado un umbral definido previamente. Se puede ver en la figura 1.
Sencillo, ¿verdad?
Sin embargo, ¿qué ocurre si no hay un "dispositivo defectuoso" en particular y simplemente alguien se queja de un mal funcionamiento del punto A al punto B? En estos casos, la persona encargada de la administración de la red tiene dos opciones: inspeccionar manualmente cada posible dispositivo de la ruta para buscar las métricas deficientes o desestimar la solicitud y esperar que el problema se resuelva solo mientras todo el mundo sigue culpando a la red.
La situación se vuelve incluso peor cuando no posee ese dispositivo y no puede monitorizarlo porque no cuenta con un SNMP en él (probablemente porque está en la nube).
Más puntos de visibilidad
Cuando haya un problema, puede ejecutar ping y traceroute para identificarlo. Aun así, este enfoque reactivo solo le permitirá investigar después de que ocurra dicho incidente, y será imposible comparar las estadísticas de la situación anterior y posterior. Además, no podrá responder de forma proactiva porque no sabe cuándo se inició el problema. Así que, como responsable de la administración de redes, depende de que alguien o algo notifique el problema para poder reaccionar.
Aquí es donde la monitorización sintética de extremo a extremo de ThousandEyes entra en juego. ThousandEyes ofrece tres tipos de puntos de visibilidad de monitorización para adaptarse a las distintas perspectivas que puedan necesitar las TI:
- Los Cloud Agents están ubicados en varios proveedores de nube y ofrecen una vista del exterior al interior de objetivos visibles de forma externa.
- Los Enterprise Agents, implementados dentro de su red o en dispositivos de red, proporcionan una visión del interior al exterior de los objetivos que se encuentran fuera de la red (como una aplicación SaaS) o una visión del interior al interior de otros objetivos que están dentro de la red.
- Los Endpoint Agents residen en estaciones de trabajo de Windows o Apple y ofrecen pruebas simplificadas hacia cualquier objetivo interno o en la nube.
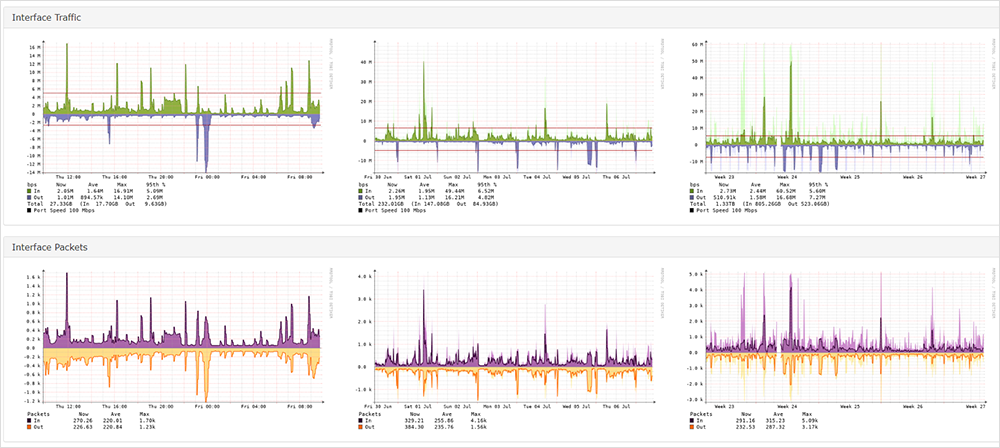
Tomemos un Enterprise Agent como ejemplo. Al configurar una prueba desde un Enterprise Agent a un objetivo como https://cisco.webex.com/, usted puede recopilar datos de rendimiento que van desde su red hasta el objetivo. El panel de la figura 2 muestra que los datos de la prueba incluyen insights relevantes como la tasa de pérdida de paquetes, latencia y fluctuación.
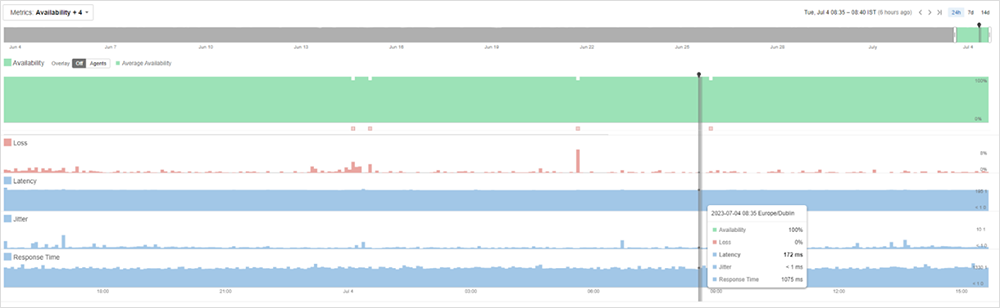
No solo obtendrá datos del agente al objetivo, sino que también podrá ver la latencia y la pérdida de paquetes entre los saltos. Esta visión integral le permite identificar si el problema reside en su red o fuera, en el Internet más amplio, como se muestra en la figura 3.

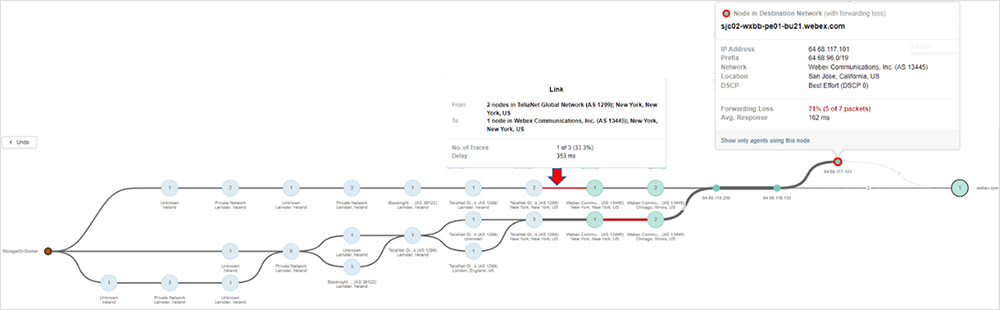
Cuando se identifica un problema como la pérdida de paquetes, se puede ver exactamente dónde ocurre. En la figura 4, puede observar que uno de los rastreos experimenta pérdida de paquetes en la red de Webex. Esta información le notifica que puede haber un límite en las acciones que tomar directamente, puesto que le permite conocer la ubicación específica del problema.
Ahora, pensemos en una situación en la que surge un problema con su propia red. En este momento específico, puede aprovechar su supervisión de dispositivos basada en SNMP para explorar las métricas del dispositivo en cuestión.
Aquí hay una bonificación poco conocida para estas instancias: en ThousandEyes, recopilamos algunos datos de métricas con SNMP desde routers, switches, firewalls, equilibradores de carga y puntos de acceso inalámbricos compatibles que exponen MIB de SNMP estándar. La figura 5 muestra dónde están disponibles estos conocimientos en la plataforma.