Les entreprises ont longtemps privilégié la supervision SNMP classique basée sur les équipements pour superviser leur infrastructure IT. Cependant, avec l’évolution de la technologie, d'autres approches qui améliorent à la fois la visibilité et la résolution des problèmes ont vu le jour, dans un monde toujours plus connecté avec l'internet.
Dans ce blog, nous nous concentrerons sur les principales différences entre la supervision SNMP, basée sur les équipements, et les fonctionnalités de supervision synthétique complète proposées par des plateformes telles que ThousandEyes, plutôt que d'explorer d'autres méthodes comme le flux. Cette distinction est essentielle pour pouvoir combiner au mieux ces deux approches afin d'offrir des solutions plus ciblées et une résolution avancée des problèmes.
Les différences
Voyons tout d'abord en quoi consiste chaque type de supervision :
Qu'est-ce que la supervision SNMP ?
- Le protocole SNMP (Simple Network Management Protocol) collecte des indicateurs associés aux équipements tels que les données d'utilisation du processeur et de la mémoire, et les statistiques d'interface. Il permet ainsi de gérer les différents équipements du réseau, notamment les routeurs, les commutateurs et les serveurs.
Qu'est-ce que la supervision synthétique ?
- De son côté, la supervision synthétique complète de ThousandEyes collecte les données de connexion entre de multiples points d'observation afin d'analyser les performances et la disponibilité du réseau. Elle tient compte à la fois des réseaux locaux et de l'Internet pour assurer une visibilité plus étendue sur l'intégrité et la fiabilité du trafic.
Ces deux technologies offrent ainsi une approche distincte de la résolution des problèmes de réseau. Prenons l'exemple d'une défaillance réseau due à un câble défectueux, à un commutateur ou un port de commutateur endommagé, ou encore à un routeur inopérant.
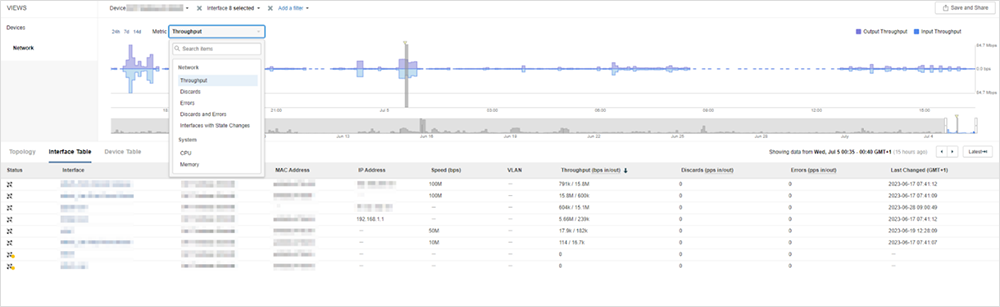
Dans ce cas, la supervision basée sur le protocole SNMP identifiera les éventuels équipements défectueux ou dépassements de seuils prédéfinis pour ces derniers. Mais les informations s'arrêtent là, comme le montre la figure 1.
Est-ce si simple que cela ?
Imaginons qu'il n'y ait aucun équipement défaillant et que quelqu'un ait simplement signalé une baisse de performance entre un point A et un point B. L'administrateur réseau a alors deux options : analyser manuellement les données de connexion de chaque équipement présent sur le trajet ou ignorer le problème en espérant qu'il se résolve tout seul, laissant les utilisateurs rejeter la faute sur le réseau.
La situation est encore plus complexe lorsque l'équipement n'appartient pas à l'entreprise et ne peut donc pas être supervisé via le protocole SNMP, par exemple s'il se trouve dans le cloud.
Davantage de points d'observation
Si les commandes ping et traceroute permettent généralement d'identifier la cause d'un problème, elles n'interviennent qu'en aval de l'incident, n'offrant aucune possibilité de comparer l'état initial et l'état actuel du réseau. Et comme l'entreprise ne sait pas quand a eu lieu l'incident, elle ne peut pas prendre de mesures proactives. En tant qu'administrateur réseau, vous devez donc attendre que le problème soit signalé avant de pouvoir agir.
C'est là que la supervision synthétique complète de ThousandEyes intervient. ThousandEyes propose trois types de points d'observation pour s'adapter aux divers besoins de visibilité :
- Les Cloud Agents sont déployés auprès de divers fournisseurs cloud pour obtenir une visibilité externe-interne sur les cibles visibles de l'extérieur.
- Les Enterprise Agents sont déployés au sein de votre réseau ou sur des périphériques réseau, fournissent une vue interne-externe sur les cibles situées sur le réseau (telles qu'une application SaaS) ou une vue interne-interne sur les autres cibles de votre réseau.
- Les Endpoint Agents sont déployés sur les postes de travail des utilisateurs finaux et offrent des tests simplifiés sur des cibles internes ou externes.
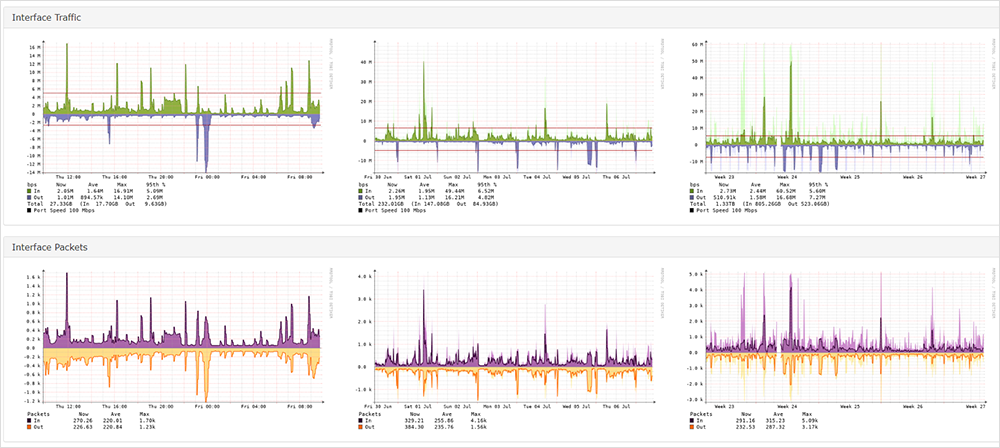
Prenons l'exemple de l'agent d'entreprise. En configurant un test depuis ThousandEyes Enterprise Agent sur une cible telle que https://cisco.webex.com/, vous pouvez collecter des données de performance pour l'ensemble du trafic depuis votre réseau jusqu'à la cible. Comme illustré dans le tableau de bord de la Figure 2, le test recueille des informations précieuses telles que le taux de perte de paquets, la latence et la gigue.
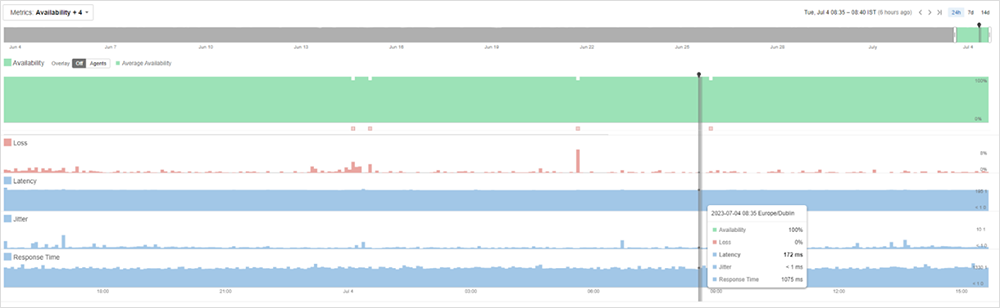
Vous obtenez des données sur le trafic de l'agent vers la cible, ainsi qu'une visibilité sur la latence et la perte de paquets entre les sauts. Cette vue d'ensemble, vous aidera rapidement à déterminer si l'incident provient de votre réseau ou de l'extérieur, comme illustré sur la Figure 3.

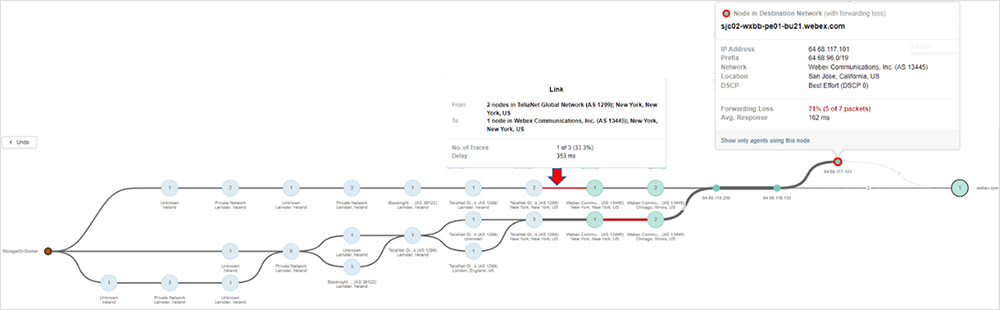
Une fois le problème identifié, par exemple une perte de paquet, vous pouvez savoir exactement où il s'est produit. La Figure 4 ci-dessous montre ainsi une perte de paquet au niveau du réseau Webex, ce qui vous permet de prendre certaines mesures en fonction de l'endroit où se produit l'incident.
Imaginons maintenant qu'un incident se produit sur votre propre réseau. C'est désormais votre solution de supervision SNMP qui va vous permettre d'analyser les données de l'équipement concerné.
Mais ce n'est pas tout : ThousandEyes peut collecter des données de mesure via le protocole SNMP auprès de routeurs, de commutateurs, de pare-feu, d'équilibreurs de charge et de points d'accès sans fil compatibles qui exposent des bases MIB SNMP standard. La Figure 5 indique où vous pouvez retrouver ces informations sur la plateforme.