Per molto tempo le aziende si sono affidate al tradizionale monitoraggio SNMP dei dispositivi per monitorare l'infrastruttura IT. Tuttavia il progresso tecnologico impone di esplorare degli approcci alternativi che sappiano offrire, nell'era di Internet, una visibilità maggiore e una risoluzione dei problemi avanzata.
In questo post, trascureremo volutamente le soluzioni di monitoraggio basate su agenti o flussi, per concentrarci sulle differenze principali tra il monitoraggio SNMP basato sui dispositivi e le funzionalità di monitoraggio end-to-end sintetico offerte da piattaforme come ThousandEyes. L'analisi di queste differenze ci consente di cogliere meglio come l'integrazione del monitoraggio end-to-end sintetico con le strategie di monitoraggio attuali possa fornire soluzioni migliori per scenari d'uso peculiari e agevolare la risoluzione dei problemi.
Le differenze
Prima di trattare l'argomento, per chiarezza è importante definire i due approcci di monitoraggio che esamineremo di seguito:
Cos'è il monitoraggio SNMP?
- Il monitoraggio SNMP (Simple Network Management Protocol) raccoglie i dati sulle metriche dei singoli dispositivi, tra cui l'utilizzo della CPU, della memoria e le statistiche delle interfacce. Le organizzazioni lo utilizzano principalmente per gestire singoli dispositivi all'interno di una rete, come router, switch e server.
Cos’è il monitoraggio sintetico?
- Il monitoraggio end-to-end sintetico di ThousandEyes raccoglie e analizza i dati di connessione tra più punti, con particolare attenzione al monitoraggio delle prestazioni e della disponibilità della rete. Il nostro approccio completo copre le reti locali e Internet, per fornire una visione più ampia dell'integrità e delle prestazioni della rete.
Queste differenze tra le due tecnologie di monitoraggio possono influenzare l'approccio degli amministratori di rete alla risoluzione dei problemi. Consideriamo uno scenario in cui si verifica un problema interno alla rete, come un cavo difettoso, guasti a uno switch o una porta switch o un router non funzionante.
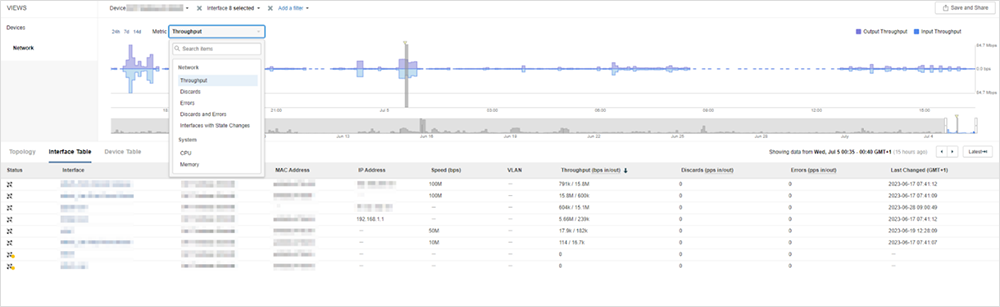
In tale situazione, il monitoraggio basato su SNMP mi segnalerà prontamente eventuali dispositivi difettosi o superamenti di soglie prestabilite da parte di una metrica del dispositivo. Tutto qui, come mostrato nella Figura 1.
Semplice, vero?
Immaginiamo ora che non ci siano dispositivi malfunzionanti e che qualcuno abbia semplicemente segnalato un calo di prestazioni tra un punto A e un punto B. In questo caso, l'amministratore di rete ha due opzioni: analizzare manualmente i dati di connessione per ogni dispositivo del percorso oppure ignorare il problema, sperando che si risolva da solo mentre gli utenti pensano che si tratti di un normale problema di rete.
La situazione è ancora peggiore quando i dispositivi non sono di proprietà dell'azienda e quindi non sono monitorabili tramite il protocollo SNMP, perché magari si trovano nel cloud.
Più punti di osservazione
I comandi ping e traceroute possono aiutare a identificare la causa di un problema, ma intervengono solo dopo che l'incidente si è verificato, non permettendo raffronti tra lo stato della rete precedente e successivo al disservizio. E poiché è impossibile determinarne l'esordio, è altrettanto impossibile adottare misure proattive. L'amministratore di rete deve attendere una segnalazione del problema per intervenire.
Ed è qui che entra in gioco il monitoraggio end-to-end sintetico di ThousandEyes. ThousandEyes offre tre tipi di punti di osservazione così da garantire all'IT diverse prospettive di monitoraggio:
- I Cloud Agent sono distribuiti presso vari provider di servizi cloud per offrire una visione dall'esterno verso l'interno di target visibili.
- Gli Enterprise Agent sono implementati come macchine virtuali nella rete aziendale oppure come container nei dispositivi di rete per offrire una visione dall'interno verso l'esterno alle destinazioni esterne alla rete oppure una visione interna ad altre destinazioni dentro la rete.
- Gli Endpoint Agent sono implementati all'interno delle postazioni di lavoro Apple e Windows e offrono dei test semplificati per qualsiasi destinazione interna o del cloud.
Prendiamo, come esempio, l'Enterprise Agent. Configurando un test dall'Enterprise Agent per una destinazione come https://cisco.webex.com/, è possibile raccogliere dati sulle prestazioni per tutto il traffico dalla rete alla destinazione. Come mostrato nella dashboard della Figura 2, il test raccoglie informazioni preziose come il tasso di perdita dei pacchetti, la latenza e il jitter.
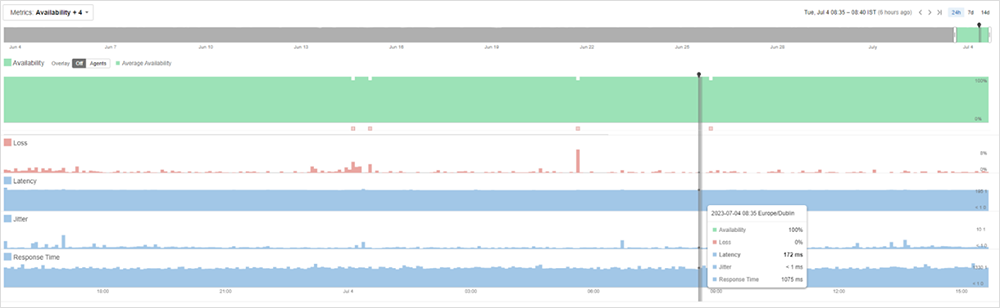
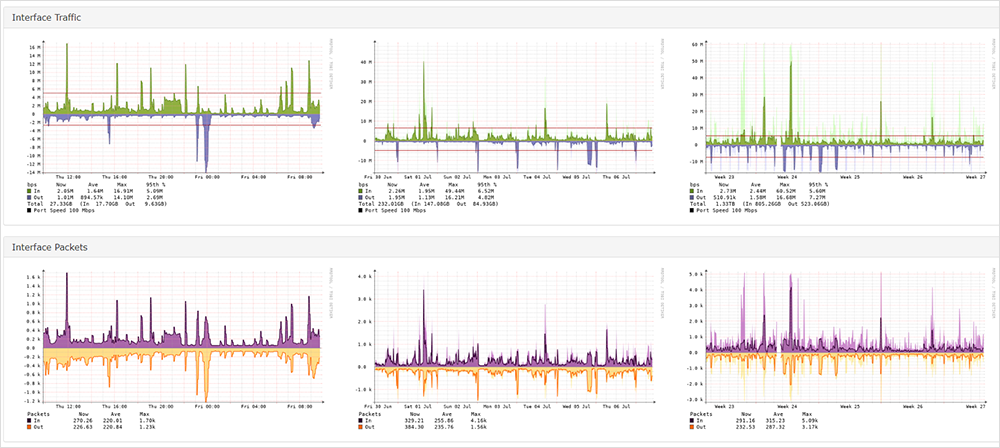
Non solo si ottengono dati dall'agent alla destinazione, ma si ha anche visibilità sulla latenza e sulla perdita di pacchetti tra gli hop. Grazie a questa visione completa, è possibile determinare se un problema risiede nella rete aziendale o nella rete Internet esterna, come mostra la Figura 3.

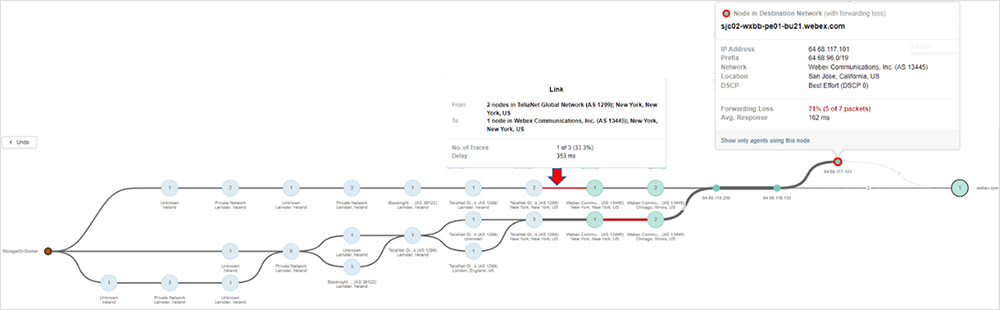
Una volta identificato un problema, ad esempio una perdita di pacchetti, è possibile determinare con precisione dove avviene. La Figura 4 sottostante mostra che una delle tracce presenta una perdita di pacchetti all'interno della rete Webex. Accertata la posizione esatta del problema, in questa data situazione si può fare ben poco per risolverlo in prima persona.
Consideriamo ora uno scenario in cui si verifica un problema all'interno della rete aziendale. In tale situazione, il monitoraggio basato su SNMP consentirà di analizzare i dati provenienti dalle metriche del singolo dispositivo interessato.
In pochi sanno, però, che ThousandEyes raccoglie metriche tramite il protocollo SNMP da router, switch, firewall, bilanciatori di carico e wireless access point that con standard MIB-SNMP. La Figura 5 mostra dove queste informazioni sono disponibili sulla piattaforma.