Klassisches, gerätebasiertes SNMP-Monitoring galt lange Zeit als die Lösung der Wahl, wenn es darum ging, die Vorgänge innerhalb von IT-Infrastruktur nachzuvollziehen. Im Zuge technologischer Fortschritte braucht es jedoch alternative Ansätze, die durch tiefergehende Einblicke eine vereinfachte Problembehebung ermöglichen – dies umso mehr in einer Zeit, in der das Internet allgegenwärtig ist.
Flow- oder Agent-basierte Monitoring-Lösungen lassen wir in diesem Artikel bewusst außen vor, da wir ganz spezifisch die wichtigsten Unterschiede zwischen gerätebasiertem SNMP-Monitoring und synthetischem End-to-End-Monitoring beleuchten möchten, wie es Plattformen wie ThousandEyes bieten. Denn mit einem klareren Verständnis davon, wie synthetisches End-to-End-Monitoring bestehende Monitoring-Strategien ergänzen kann, lassen sich bessere Lösungen für spezifische Use Cases gestalten und Probleme zielgenauer beheben.
Die Unterschiede
Zunächst einmal gilt es, die beiden Monitoring-Ansätze zu definieren, die wir im Folgenden untersuchen:
Was ist SNMP-Monitoring?
- Beim SNMP-Monitoring (Simple Network Management Protocol) werden gerätespezifische Metriken erfasst. So etwa Daten zur CPU-Auslastung und Arbeitsspeichernutzung sowie Statistiken zu Interfaces. Genutzt wird SNMP-Monitoring in erster Linie, um innerhalb eines Netzwerks Geräte wie Router, Switches und Server zu managen.
Was ist synthetisches Monitoring?
- Beim synthetischen End-to-End-Monitoring mit ThousandEyes geht es dagegen um die Erfassung und Analyse von Verbindungsdaten zwischen verschiedenen Punkten, wobei der Fokus auf der Performance und Verfügbarkeit des Netzwerks liegt. Die Methodik ist dabei umfassend angelegt, deckt also lokale Netzwerke ebenso ab wie das Internet. So wird eine detaillierte Sicht auf Netzwerkstatus und -performance möglich.
Diese Unterschiede zwischen den beiden Monitoring-Technologien können Einfluss darauf nehmen, wie Netzwerk-Admins Troubleshooting-Prozesse angehen. Deutlich wird dies am Beispiel eines Szenarios, bei dem innerhalb des Netzwerks ein Problem wie ein fehlerhaftes Kabel, ein defekter Switch oder Switch-Port oder auch ein Router-Ausfall vorliegt.
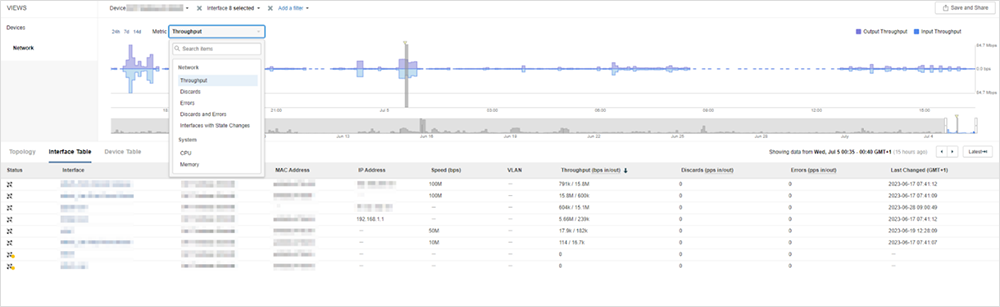
SNMP-basiertes Monitoring wird uns in einem solchen Fall umgehend über jegliche Geräteprobleme oder darüber benachrichtigen, dass bei einer gerätebezogenen Metrik ein vordefinierter Grenzwert überschritten wurde. Darüber hinaus erhalten wir aber keine Informationen, wie in Abbildung 1 zu sehen.
Bis hierhin dürfte alles klar sein.
Was aber, wenn ein Problem nicht auf ein bestimmtes fehlerhaftes Gerät zurückgeht, sondern von einem User unzureichende Performance zwischen Punkt A und Punkt B gemeldet wird? In Fällen wie diesen bleiben Netzwerk-Admins nur zwei Optionen: die Port-Metriken sämtlicher potenziell auf dem Pfad befindlichen Geräte untersuchen oder das Problem ignorieren und hoffen, dass es sich von selbst löst. In letzterem Fall würden dann einfach weiterhin alle das Netzwerk als Problemursache ansehen.
Noch problematischer wird es, wenn sich das Gerät nicht in der eigenen Infrastruktur befindet und kein Monitoring dafür möglich ist, weil SNMP darauf nicht genutzt werden kann. (Etwa, weil es sich in der Cloud befindet.)
Mehr Beobachtungspunkte
Bei der Identifikation eines Problems könnte eine Nachverfolgung via Ping oder Traceroute helfen. Ein reaktiver Ansatz wie dieser bedeutet jedoch, dass das Problem erst untersucht wird, nachdem es bereits aufgetreten ist. Ein Vorher-Nachher-Vergleich lässt sich somit nicht anstellen, außerdem ist keine proaktive Reaktion möglich, da nicht bekannt ist, wann das Problem ursprünglich aufgetreten ist. Als Netzwerk-Admin ist man also davon abhängig, dass jemand das Problem meldet, bevor Gegenmaßnahmen eingeleitet werden können.
Genau hier kommt synthetisches End-to-End-Monitoring mit ThousandEyes ins Spiel. Denn dieser Ansatz bietet drei Arten von Beobachtungspunkten, die der IT wichtige zusätzliche Monitoring-Perspektiven liefern:
- Cloud Agents: Diese werden innerhalb verschiedener Cloud-Provider positioniert, um eine Sicht „von außen nach innen“ auf extern sichtbare Ziele zu ermöglichen.
- Enterprise Agents: Diese werden in Ihrem Netzwerk oder auf Netzwerkgeräten bereitgestellt. Für Ziele außerhalb des Netzwerks (z. B. eine SaaS-App) liefern sie eine Sicht „von innen nach außen“ oder für andere Ziele innerhalb des Netzwerkseine liefern sie eine Sicht „von innen nach innen“.
- Endpoint Agents: Diese werden auf Windows- oder Apple-Workstations implementiert und erleichtern die Durchführung von Tests auf beliebige Ziele innerhalb interner Infrastruktur oder der Cloud.
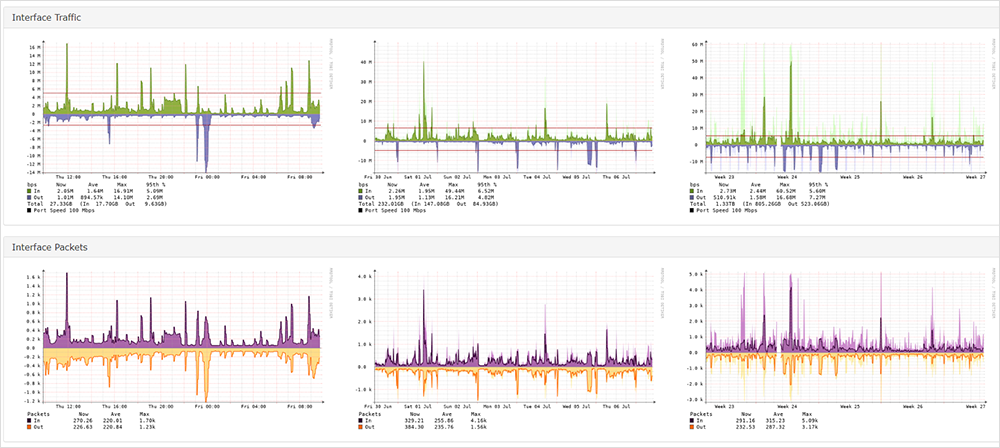
Sehen wir uns das am Beispiel des Enterprise Agent an: Indem wir einen Test vom Enterprise Agent zu einem Ziel wie https://cisco.webex.com/ konfigurieren, erhalten wir Daten zur Performance vom Netzwerk bis zum Ziel. Wie im Dashboard in Abbildung 2 zu sehen, umfassen die Testdaten wertvolle Einblicke etwa zur Rate des Paketverlusts oder auch zu Latenz und Jitter.
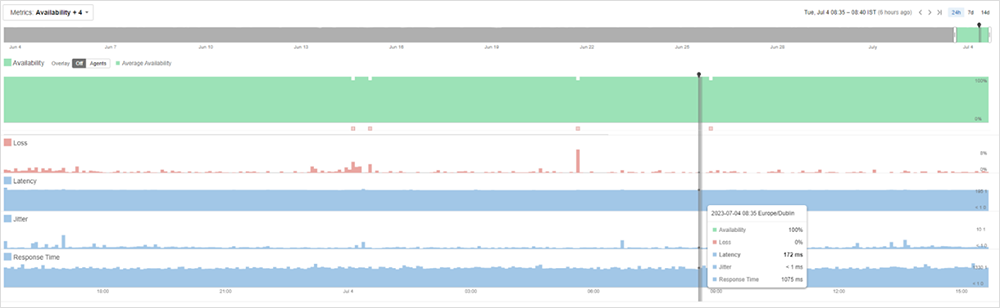
Wir erhalten also nicht nur Daten zum Verbindungsweg vom Agent zum Ziel, sondern können Details zu Latenz und Paketverlust zwischen den Hops einsehen. Dank dieser umfassenden Einblicke lässt sich punktgenau ausmachen, ob ein Problem innerhalb unseres Netzwerks oder im Internet besteht (siehe Abbildung 3).

Nachdem die Art eines Problems bestimmt wurde (z. B. Paketverlust), lässt sich präzise ausmachen, wo es verortet ist. So sehen wir in Abbildung 4, dass bei einer der Traces Paketverlust innerhalb des Webex-Netzwerks vorliegt. Dies wiederum verrät uns, dass wir selbst nur wenig direkte Maßnahmen dagegen unternehmen können, da wir nun den genauen Problemstandort kennen.
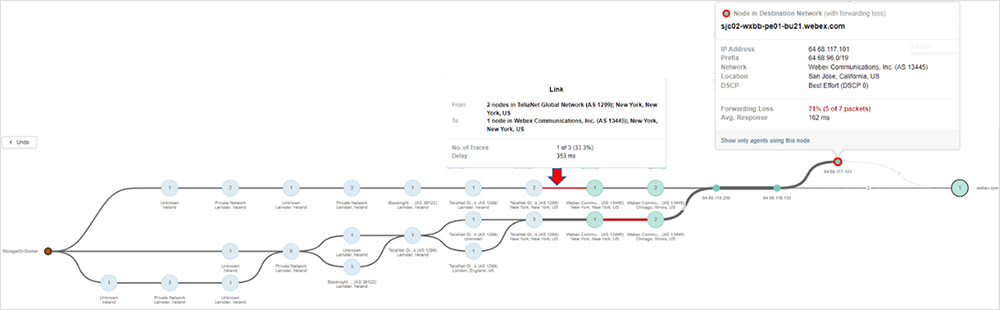
Wie gestaltet sich das Ganze aber, wenn ein Problem innerhalb unseres eigenen Netzwerks auftritt? Nun, in diesem Fall können wir SNMP-basiertes Geräte-Monitoring zurate ziehen, wobei wir uns die Metriken des jeweils betroffenen Geräts genauer ansehen.
Was in diesem Zusammenhang allerdings wenig bekannt ist: ThousandEyes erfasst ebenfalls einige Metriken anhand von SNMP – dies für unterstützte Router und Switches, Firewalls, Load Balancer sowie Wireless Access Points, die standardmäßige SNMP-MIBs bereitstellen. Abbildung 5 zeigt, wo diese Einblicke innerhalb der Plattform verfügbar sind.