Ogni giorno, in tutto il mondo, si verificano interruzioni di ogni portata. Quelle del 2022 hanno avuto un impatto mai visto e hanno causato ripercussioni serie per le esperienze degli utenti e, talvolta, paralisi momentanee delle operazioni aziendali. I dati generalizzati raccolti ed elaborati da ThousandEyes per fornirci una chiara visibilità sulle reti Internet e cloud rivelano che l'anno scorso si sono verificate migliaia di interruzioni. Offriamo queste informazioni ai nostri clienti per aiutarli ad adottare un approccio proattivo e, ove possibile, mitigare le interruzioni dell'operatività. Abbiamo creato la seguente cronologia, che ripercorre brevemente alcuni eventi che abbiamo osservato e le lezioni che possiamo trarre per aiutare le aziende a mantenere le connessioni e la continuità operativa nel 2023.
25 febbraio 2022: British Airways
Cosa è successo: l'interruzione dei servizi online di British Airways ha causato la cancellazione di centinaia di voli e l'arresto delle operazioni della compagnia aerea anche presso l'hub di Londra-Heathrow, il primo aeroporto internazionale al mondo per traffico aereo. Il nostro monitoraggio mostra che l'incidente si è verificato in seguito alla mancata risposta dei server delle applicazioni più che per un problema di rete.
Impatto geografico: globale → Leggi l'analisi
La lezione: la progettazione di backend in grado di evitare singoli punti critici può ridurre la probabilità di eventi a catena capaci di bloccare a terra l'intera flotta, come accaduto a British Airways.
28 marzo 2022: Twitter
Cosa è successo: la piattaforma Twitter è diventata irraggiungibile dopo che un provider russo di comunicazioni via satellite e Internet ha dirottato il traffico annunciando un prefisso di Twitter. Le configurazioni errate di BGP non sono insolite. Tuttavia, possono essere utilizzate anche per bloccare il traffico in modo mirato e non è sempre facile determinare se sono azioni volontarie o meno.
Impatto geografico: globale → Leggi l'analisi
La lezione: anche se l'azienda ha implementato un'infrastruttura RPKI per respingere le minacce BGP, è possibile che il provider di telecomunicazioni non l'abbia fatto e occorre tenerne conto al momento di scegliere un ISP.
5 aprile 2022: Atlassian
Cosa è successo: Jira, Confluence e OpsGenie sono tre prodotti Atlassian utilizzati da molti team di sviluppo. A causa di un errore dello script di manutenzione, questi servizi hanno subito un'interruzione di diversi giorni che ha interessato circa 400 clienti di Atlassian. Benché il numero dei clienti interessati sia stato relativamente esiguo, gli annunci generici pubblicati nella pagina di stato dei servizi di Atlassian potrebbero aver confuso i clienti che avevano problemi di altra natura.
Impatto geografico: globale → Leggi l'analisi
La lezione: le pagine di stato non sono uno strumento sufficiente per le comunicazioni relative alle interruzioni; i clienti non vengono aggiornati sulla gravità dell'interruzione e sui tempi di risoluzione per ore o addirittura per giorni.
8 luglio 2022: Rogers Communications
Cosa è successo: Rogers Communications ha dovuto ritirare i propri prefissi per un problema di routing interno, il che ha reso questo fornitore di rete di primo livello irraggiungibile su Internet per circa 24 ore. L'interruzione ha interessato milioni di utenti e molti servizi essenziali in tutto il Canada.
Impatto geografico: America → Leggi l'analisi
La lezione: nessun provider, per quanto grande, è immune dalle interruzioni di rete; perciò, per i servizi essenziali come quelli offerti da ospedali e banche, è bene mantenere un secondo provider di rete che, al bisogno, subentri per ammortizzare la durata e l'entità dell'interruzione.
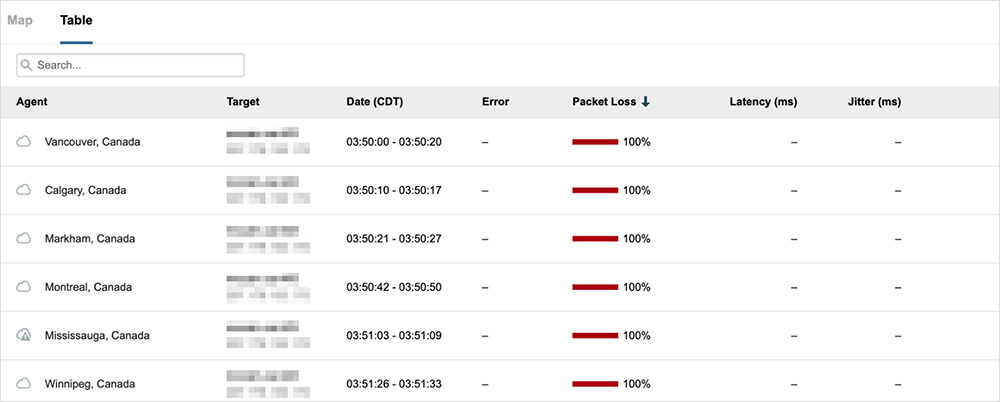
8 luglio 2022: Amazon Web Services
Cosa è successo: questa interruzione di AWS è stata causata da un'interruzione dell'alimentazione in una zona di disponibilità (Availability Zone o AZ) e ha interessato applicazioni come Webex, Okta e Splunk. Tuttavia, non tutti gli utenti o i servizi sono stati colpiti allo stesso modo: i componenti di Webex presso i data center Cisco non hanno presentato problemi.
Impatto geografico: globale → Leggi l'analisi
La lezione: è opportuno avere un'architettura AZ ridondante, generalmente di tipo attivo/attivo, che elimina l'esigenza del piano di backup.
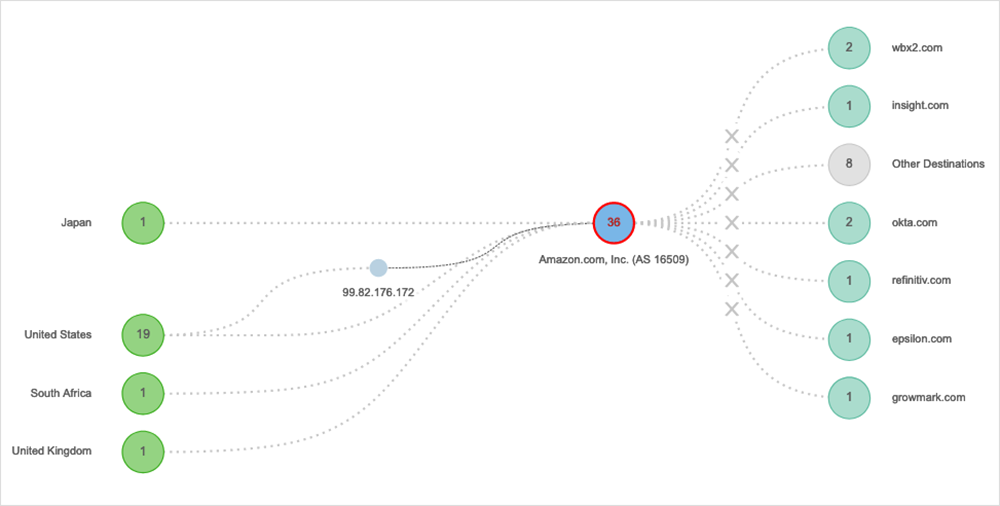
9 agosto 2022: Google
Cosa è successo: il motore di ricerca di Google e Google Maps sono diventati inutilizzabili per gli utenti di tutto il mondo, che hanno ricevuto messaggi di errore nel tentativo di raggiungere i servizi. Dagli Stati Uniti all'Australia, dal Giappone al Sudafrica, nessun utente poteva caricare i siti o eseguire funzioni. Anche le applicazioni dipendenti dal software di Google sono state interessate da questa rara interruzione.
Impatto geografico: globale → Esplora questa interruzione in ThousandEyes | Leggi l'analisi
La lezione: oltre ai frontend delle applicazioni, è importante monitorare anche le loro dipendenze critiche per le prestazioni.
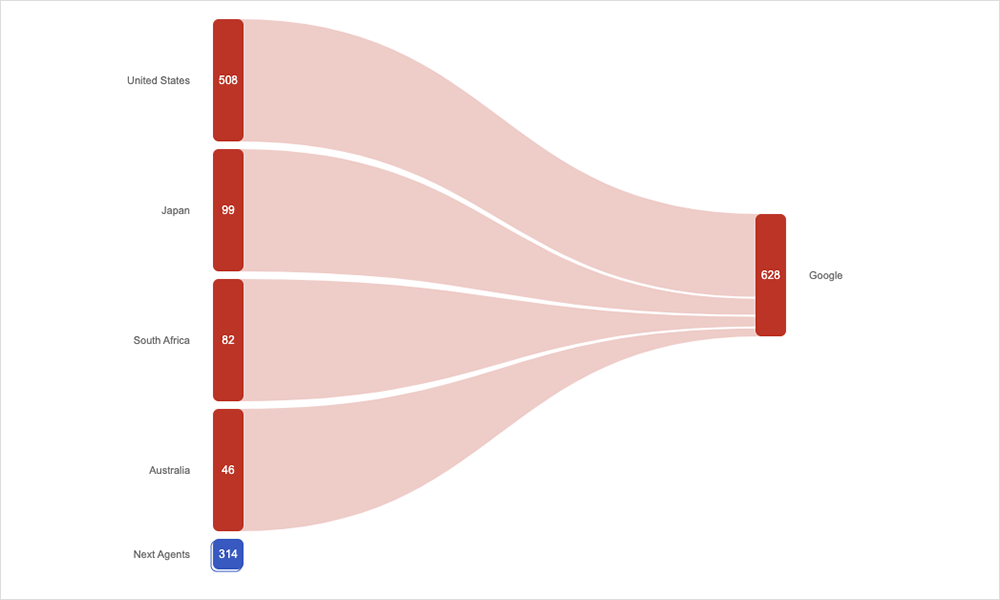
15 settembre 2022: Zoom
Cosa è successo: questa breve interruzione ha interessato gli utenti di tutto il mondo, impedendo di accedere e partecipare alle riunioni con Zoom. Il rinvio degli appuntamenti di telemedicina o dei colloqui di lavoro sono soltanto due delle problematiche degli utenti a seguito dell'interruzione dell'applicazione.
Impatto geografico: globale → Leggi l'analisi
La lezione: talvolta, la causa di un problema risiede non tanto nella rete quanto nell'applicazione stessa. Avere visibilità sulla probabile causa può evitare confusione e semplificare l'analisi delle cause profonde.
25 ottobre 2022: Zscaler
Cosa è successo: i clienti di Zscaler Internet Access (ZIA) hanno avuto problemi di connettività o di latenza elevata durante la connessione ai proxy Zscaler. Poiché le implementazioni Secure Service Edge (SSE) generalmente fungono da proxy per il traffico Web e gli strumenti aziendali critici, questo incidente ha impedito ad alcuni clienti di accedere a SaaS, Salesforce, ServiceNow e Microsoft365.
Impatto geografico: globale → Leggi l'analisi
La lezione: il Secure Service Edge è un altro fattore da considerare in caso di criticità. Disporre di dati di rete neutrali per scenari complessi come quello di Zscaler può accelerare gli interventi di attribuzione delle cause e la risoluzione.
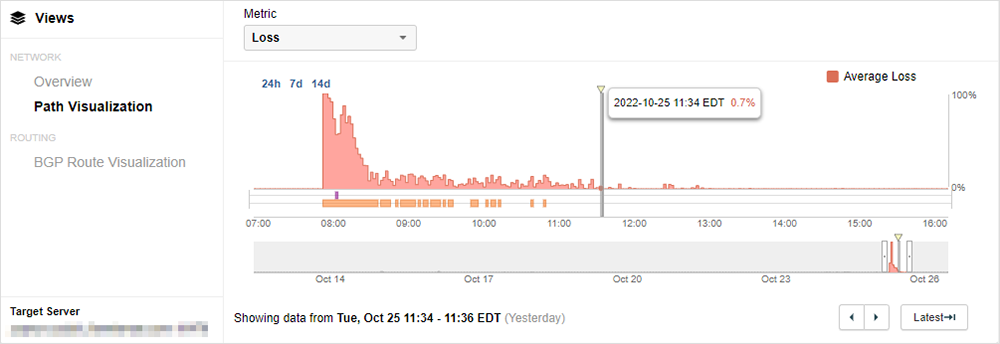
25 ottobre 2022: WhatsApp
Cosa è successo: l'interruzione, durata due ore, ha impedito agli utenti di WhatsApp di inviare o ricevere messaggi ed è stata attribuita a un malfunzionamento dell'applicazione di backend anziché a un'interruzione della rete. L'incidente si è verificato durante le ore di punta in India (dove l'app ha centinaia di milioni di utenti), rendendo impossibili le comunicazioni private e commerciali.
Impatto geografico: globale → Leggi l'analisi
La lezione: la prosperità di un'azienda SaaS dipende dal miglioramento continuo, per questo è necessario un ciclo di feedback immediato che consenta di correggere rapidamente gli errori. Disporre di dati che aiutino a escludere la rete dalle possibili cause di un errore del sistema di produzione può accelerare la risoluzione dei problemi tecnici.
5 dicembre 2022: Amazon Web Services
La vicenda: ThousandEyes ha riscontrato una significativa perdita di pacchetti tra due aree internazionali e la regione "us-east-2" di AWS per oltre un'ora. L'evento ha interessato gli utenti finali che cercavano di connettersi tramite i loro ISP ai servizi del fornitore di infrastrutture cloud di quella regione.
Impatto geografico: globale → Esplora questa interruzione in ThousandEyes | Leggi l'analisi
La lezione: quando si usa un cloud pubblico, è importante monitorare non solo le applicazioni stesse ma anche i componenti dell'infrastruttura cloud, comprese le singole regioni e zone di disponibilità del cloud e tutti i servizi software cloud dipendenti.
Le interruzioni dell'operatività sono eventi inevitabili e normali per tutti gli ISP e provider di servizi cloud. Ma la progettazione di un'infrastruttura resiliente può proteggere le applicazioni dalle conseguenze negative e migliorare, al contempo, l'esperienza utente.
Non perdere il nostro webinar "Le principali interruzioni del 2022: analisi e conclusioni" dove gli esperti parlano delle principali interruzioni dell'anno scorso e delle possibili misure preventive per l'anno corrente.