いわゆるインターネット障害は、大なり小なり、世界各地で毎日起きています。そのため 2022 年には、ユーザー体験が悪化したり事業の流れが淀んだりと、一部の企業は大きな被害を被ることになりました。世界のネットワーク全体から ThousandEyes がデータを収集したところ、
昨年も莫大な数の障害が発生するなど、インターネット全体からクラウドに至る各所で、様々なことが明らかになっています。このようなインサイトをお客様と共有することで、可能な限りダウンタイムを軽減する準備の一助となればと思い、主な出来事を振り返るタイムラインを作成しました。また、2023 年に向けての教訓もまとめましたので、ぜひご覧ください。
British Airways 社(2022 年 2 月 25 日)
出来事:British Airway のオンラインサービスが停止して数百の便がキャンセルになったほか、世界で最も忙しいロンドンヒースロー国際空港(同社のハブ)を含む全体のサービスが停止。ThousandEyes の分析によれば、この問題は、ネットワークの障害ではなく、アプリケーションサーバーが無反応になったことが原因です。
地理的影響:グローバル → サービス停止分析を読む
教訓:シングルポイント障害を避けられる構造のバックエンドならば、全便が欠航となるような障害の連鎖リスクを低減可能。
Twitter 社(2022 年 3 月 28 日)
出来事:ロシアのインターネット・衛星通信プロバイダーが、Twitter 社のプレフィックスのうちの一つを宣言することでトラフィックをブラックホール化した結果、Twitter への接続障害が発生。BGP の設定ミスは珍しいことではないものの、これを利用して故意にブラックホールを発生させることも可能です。実際にそうした問題が発生した際、それが事故なのか意図的なのかを判断することは難しい場合もあります。
地理的影響:グローバル → サービス停止分析を読む
教訓:BGP の脅威に対抗するべく自社が RPKI を導入している場合でも、利用している通信プロバイダーでは未導入の可能性も。ISP は慎重に選ぶことが必要。
Atlassian 社(2022 年 4 月 5 日)
出来事:メンテナンススクリプトのエラーのため、Attlassian 社の主要 3 製品である Jira と Confluence、OpsGenie が数日間に渡って停止し、およそ 400 社の顧客に影響が発生。顧客への影響範囲は比較的小さかったものの、Attlassian の公式サイトでは詳細を欠いた状況説明しかなかったこともあり、自社の状況を確認できないなど混乱を招いた可能性が指摘されています。
地理的影響:グローバル → サービス停止分析を読む
教訓:サービス停止について、状況説明のページだけに頼るべきではない。サービス停止の重大度や復旧までの見込みについて詳しい説明のないまま、何時間、あるいは何日も放置されてしまう可能性がある。
Rogers Communications 社(2022 年 6 月 8 日)
出来事:内部ルーティング問題のためにプレフィックスを引き上げた結果、Tier 1 のプロバイダーがおよそ 24 時間アクセス不能に。このサービス障害により、カナダ全土の数百万規模のユーザーおよび重要なサービスが影響を受けました。
地理的影響: グローバル → サービス停止分析を読む
教訓:規模を問わず、どのようなプロバイダーにもサービス停止は発生しかねない。病院や銀行のような重要度の高いサービスでは、バックアップのネットワークプロバイダーを選んでおくことで、サービス停止の規模や期間を軽減することが重要。
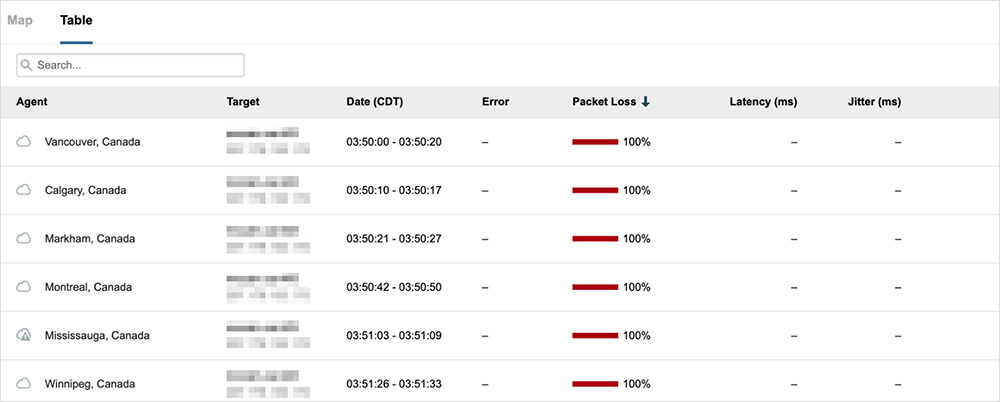
Amazon Web Service(2022 年 7 月 8 日)
出来事:アベイラビリティゾーンでの停電が原因となり AWS サービスが停止し、Webex や Octa、Splunk といったアプリケーションに影響が波及。ただし、シスコデータセンターに配置されていた Webex コンポーネントは稼働を続けるなど、影響はユーザーやサービスごとに異なるものでした。
地理的影響:グローバル → サービス停止分析を読む
教訓:AZ アーキテクチャに冗長性を確保することで、通常時はアクティブ/アクティブ状態を維持できるため、バックアッププランの実行の必要性を軽減可能。
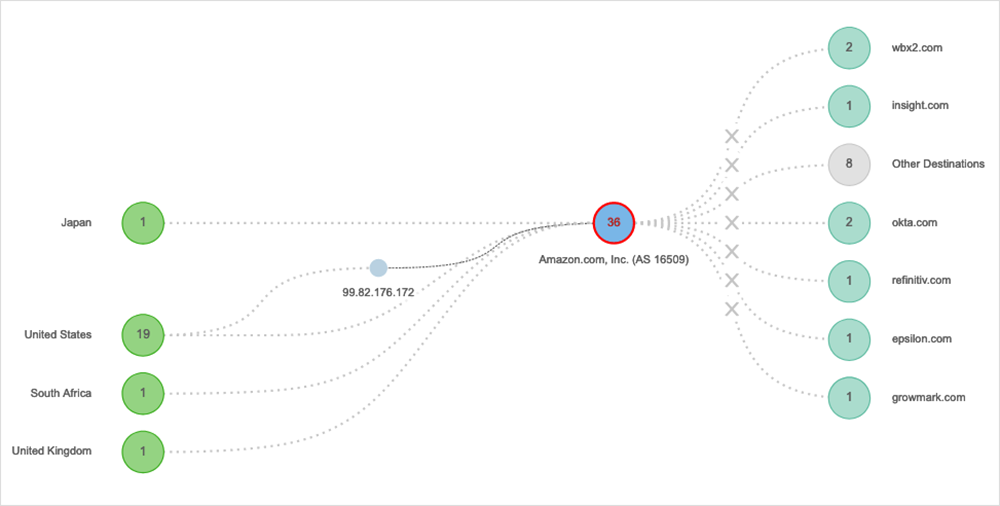
Google 社(2022 年 8 月 9 日)
出来事:Google Search および Google Maps が全世界で利用できなくなり、サービスにアクセスしようとするとエラーメッセージが表示。米国やオーストラリア、日本、南アフリカのユーザーは各サービスや機能を読み込んで使うことができない状態でした。Google 社のソフトウェア機能に依存しているアプリケーションも影響を受けて使えない状態が続きました。
地理的影響:グローバル → このサービス停止に関する ThousandEyes の分析 | サービス停止分析を読む
教訓:アプリケーションのフロントエンドだけでなく、そのアプリケーションのパフォーマンスの維持に不可欠な外部サービスまで監視することが重要。
Zoom 社(2022 年 9 月 15 日)
出来事:短時間の停止ではあったが、Zoom ミーティングへの参加やログインが世界中で停止。遠隔医療のアポイントメントや仕事の面接などが延期になるなどの影響が見られました。
地理的影響:グローバル → サービス停止分析を読む
教訓:ネットワークではなくアプリケーションそのものが問題の原因となる場合も。原因分析の際には、この分野における可視性を高めておくことが重要。
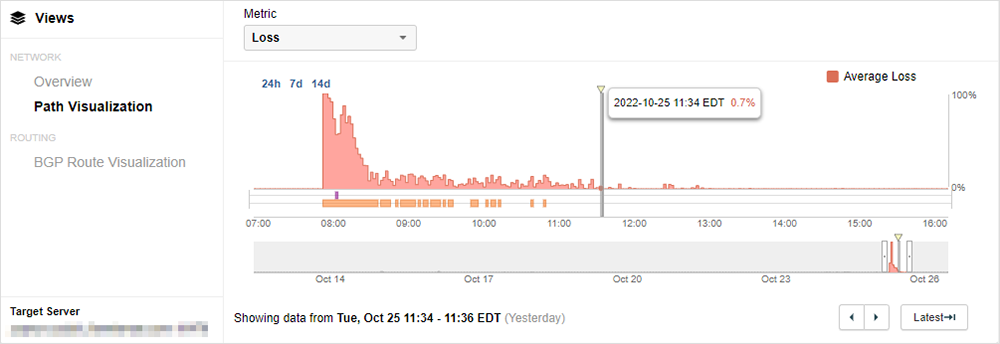
Zscaler 社(2022 年 10 月 25 日)
出来事:Zscaler Internet Access(ZIA)のユーザーが Zscaler プロキシに接続する際に、接続の失敗や遅延が発生。実装された Secure Service Edge(SSE)は通常、Web トラフィックと重要なビジネスツールや SaaS のプロキシ経路となるため、一部のユーザーは Salesforce、ServiceNow、Microsoft 365 などにアクセスできなくなった可能性があります。
地理的影響:グローバル → サービス停止分析を読む
教訓:SSE も問題の原因になり得る。今回のような複雑な状況でも迅速に原因を特定して修復できるよう、ネットワークに依存しないデータを準備しておくことが重要。
WhatsApp(2022 年 10 月 25 日)
出来事:メッセージの送受信ができなくなるなど、WhatsApp で 2 時間のサービス障害が発生。問題の原因はネットワークではなく、バックエンドのアプリケーションの障害によるものでした。億単位のユーザーを抱えるインドでは、利用がピークの時間帯に障害が発生したことで、私生活やビジネスにも影響が及びました。
地理的影響:グローバル → サービス停止分析を読む
教訓:SaaS 事業を成功させるには、継続的な改善が必要であり、そのためには問題をすぐに修復できる迅速なフィードバックループが必要になる。製品システムにエラーが起こった際にネットワークが原因である可能性を除外できるようなデータがあれば、技術的問題を迅速に解決できる。
Amazon Web Service(2022 年 12 月 5 日)
出来事:ある 2 か所の地域と AWS の us-east-2 地域の間で、1 時間以上、重大なパケットロスが発生していることを ThousandEyes が確認。ISP を通じて該当地域のクラウドインフラ プロバイダーのサービスにアクセスしていたエンドユーザーが影響を受けました。
地理的影響:グローバル → このサービス停止に関する ThousandEyes の分析 | サービス停止分析を読む
教訓:パブリッククラウドを利用する場合、アプリケーションだけではなく、個々のクラウドリージョンやアベイラビリティーゾーンを含むクラウドインフラや、それに依存するクラウドソフトウェアサービスにも注意が必要。
ダウンタイムは避けらないものであり、サービスの停止はあらゆる ISP やクラウドプロバイダーに発生しかねないものです。しかし、レジリエンス(回復力)のあるインフラを構築しておけば、アプリケーションを保護してユーザー体験を改善することができます。


