Ausfälle, ob groß oder klein, gibt es jeden Tag und überall auf der Welt. Im Jahr 2022 waren Ausfälle so störend wie nie zuvor – sie verschlechterten die User Experience und legten oft den Geschäftsbetrieb lahm. ThousandEyes hat im vergangenen Jahr mit unseren netzwerkunabhängigen Daten tausende von Ausfällen aufgezeichnet, die uns klare Einblicke in das Internet und die Cloud ermöglichen. Diese Erkenntnisse stellen wir unseren Kunden zur Verfügung, damit sie proaktiv planen und Ausfallzeiten nach Möglichkeit abmildern können. Aus dieser Arbeit haben wir die hier folgende Zeitleiste erstellt, die einige der von uns beobachteten Ereignisse und die daraus gezogenen Lehren zusammenfasst. Unser Ziel ist es, Ihnen dabei zu helfen, auch im Jahr 2023 online und einsatzbereit zu bleiben.
British Airways, 25. Februar 2022
Was ist passiert? Der Ausfall der Online-Services von British Airways führte zu Hunderten von Flugstreichungen und Unterbrechungen im Betrieb der Fluggesellschaft, auch an ihrem Drehkreuz London Heathrow, dem verkehrsreichsten internationalen Flughafen der Welt. Unsere Monitoring-Daten zeigen, dass dieser Vorfall nicht auf ein Netzwerkproblem zurückzuführen war, sondern darauf, dass die Applikations-Server nicht mehr reagierten.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: Mithilfe von Backends, die Single Points of Failure vermeiden, lässt sich die Wahrscheinlichkeit einer Kette von Ereignissen wie bei British Airways verringern, die eine gesamte Flotte lahmlegen kann.
Twitter, 28. März 2022
Was ist passiert? Twitter war nicht mehr erreichbar, nachdem ein russischer Internet- und Satellitenkommunikationsanbieter ein Traffic-Blackhole verursacht hatte, indem er eines der Präfixe von Twitter ankündigte. BGP-Fehlkonfigurationen sind keine Seltenheit. Sie können jedoch auch dazu verwendet werden, den Traffic gezielt zu blockieren, und es ist nicht immer leicht zu erkennen, ob es sich um ein Versehen oder eine absichtliche Störung handelt.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: Auch wenn Ihr Unternehmen RPKI implementiert hat, um BGP-Bedrohungen abzuwehren, kann es sein, dass dies bei Ihrem Telekommunikationsanbieter nicht der Fall ist. Das sollten Sie bei der Auswahl von ISPs berücksichtigen.
Atlassian, 5. April 2022
Was ist passiert? Jira, Confluence und OpsGenie von Atlassian sind drei Produkte, auf die sich viele Entwicklerteams verlassen. Aufgrund eines Fehlers in einem Wartungsskript kam es bei diesen Services zu einem tagelangen Ausfall, von dem etwa 400 Kunden von Atlassian betroffen waren. Obwohl die Zahl der betroffenen Kunden relativ klein war, haben die wenig aussagekräftigen Aktualisierungen auf der Statusseite von Atlassian bei Betroffenen und anderen Parteien möglicherweise für Verwirrung gesorgt.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: Man kann sich nicht allein auf Statusseiten verlassen, um über Ausfälle zu informieren. Kunden können sich stunden- oder sogar tagelang Sorgen machen, ohne eine Antwort auf die Frage zu erhalten, wie schwerwiegend der Ausfall ist und wann er behoben sein wird.
Rogers Communications, 8. Juli 2022
Was ist passiert? Rogers Communications hat aufgrund eines internen Routing-Problems seine Präfixe zurückgezogen, wodurch der Tier-I-Anbieter fast 24 Stunden lang nicht über das Internet erreichbar war. Dieser Ausfall betraf Millionen von Usern und viele wichtige Services in ganz Kanada.
Betroffene Regionen: Nordamerika → Ausfallanalyse lesen
Erkenntnisse: Kein Anbieter ist gegen Ausfälle immun, egal wie groß das Unternehmen ist. Planen Sie für wichtige Services, z. B. in Krankenhäusern und Banken, einen Backup-Netzwerkanbieter ein, der die Dauer und den Umfang eines Ausfalls abfedern kann.
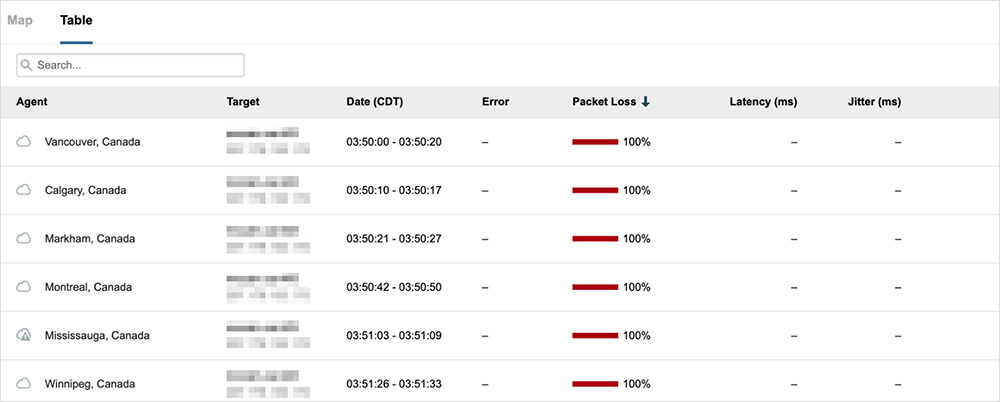
Amazon Web Services, 8. Juli 2022
Was ist passiert? Dieser AWS-Ausfall wurde durch einen Stromausfall in der Verfügbarkeitszone verursacht und betraf Applikationen wie Webex, Okta und Splunk. Es waren jedoch nicht alle User oder Services gleichermaßen betroffen. Webex-Komponenten, die sich in Cisco Rechenzentren befinden, waren weiterhin betriebsbereit.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: Achten Sie auf eine redundante AZ-Architektur, da diese in der Regel aktiv/aktiv sind und Backup-Pläne überflüssig machen.
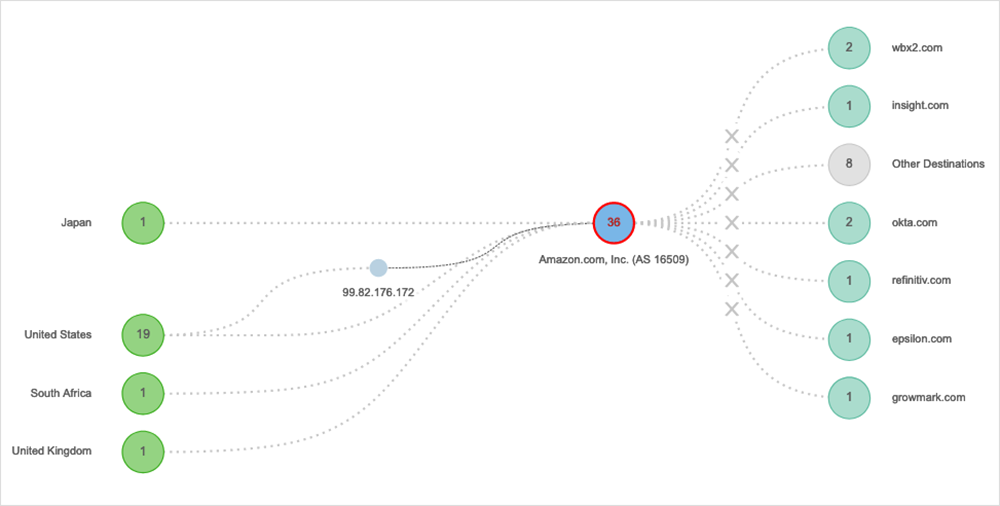
Google, 9. August 2022
Was ist passiert? Die Google-Suche und Google Maps waren für User auf der ganzen Welt nicht mehr verfügbar. Wer versuchte, die Services zu erreichen, erhielt Fehlermeldungen. User von den Vereinigten Staaten bis Australien, von Japan bis Südafrika konnten keine Websites laden oder Funktionen ausführen. Auch Applikationen, die von Google Software abhängig sind, funktionierten während dieses seltenen Ausfalls nicht mehr.
Betroffene Regionen: weltweit → Diesen Ausfall in ThousandEyes untersuchen | Ausfallanalyse lesen
Erkenntnisse: Es ist wichtig, nicht nur Ihre Applikations-Frontends zu überwachen, sondern auch die Performance-relevanten Abhängigkeiten im Hintergrund.
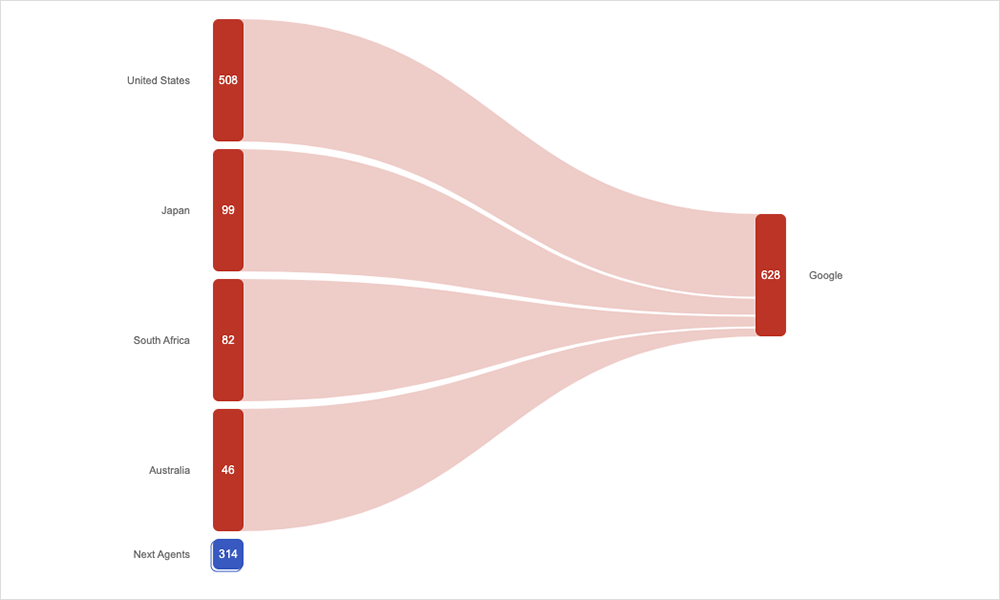
Zoom, 15. September 2022
Was ist passiert? Der kurze Ausfall betraf User auf der ganzen Welt. Sie konnten sich weder anmelden noch an Zoom-Meetings teilnehmen. Es kam dabei unter anderem zu erheblichen Terminproblemen und Verschiebungen, nur eine Auswirkung von vielen, die User durch dieses Applikationsproblem zu spüren bekamen.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: Es kann sein, dass die App selbst die Probleme verursacht und nicht das Netzwerk. Wenn Sie wissen, wo das Problem liegt, können Sie Verwirrung und Schuldzuweisungen bei der Ursachenanalyse vermeiden.
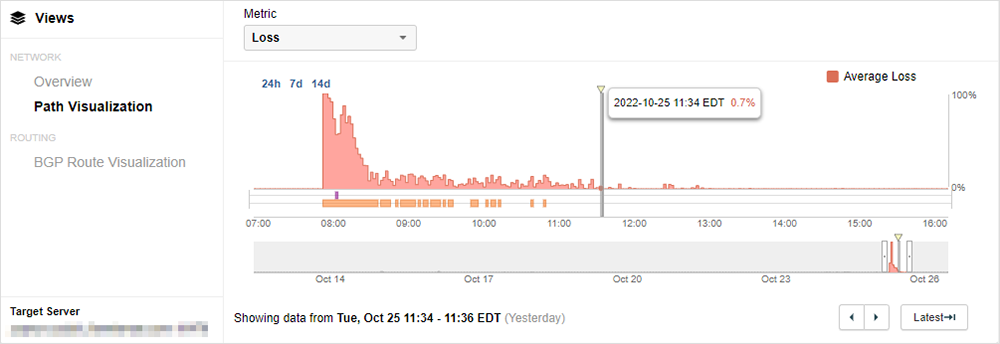
Zscaler, 25. Oktober 2022
Was ist passiert? Bei Kunden, die Zscaler Internet Access (ZIA) verwenden, kam es zu Konnektivitätsausfällen oder hohen Latenzzeiten beim Erreichen der Zscaler-Proxys. Da SSE-Implementierungen (Secure Service Edge) in der Regel als Proxys für den Web-Traffic und kritische Geschäfts-Tools und SaaS fungieren, könnten Salesforce, ServiceNow und Microsoft 365 durch diesen Vorfall für einige Kunden unerreichbar gewesen sein.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: SSE ist ein weiterer Teil des Internet-Puzzles, das zu berücksichtigen ist, wenn etwas schief läuft. Netzwerkunabhängige Daten für komplexe Szenarien wie dieses können eine schnellere Zuordnung und Abhilfe ermöglichen.
WhatsApp, 25. Oktober 2022
Was ist passiert? Der zweistündige Ausfall führte dazu, dass WhatsApp-User keine Nachrichten senden oder empfangen konnten, und war eher auf Fehler in der Backend-Applikation als auf einen Netzwerkausfall zurückzuführen. Der Vorfall ereignete sich während der Hauptnutzungszeiten in Indien, wo die App mehrere Hundert Millionen User hat, und führte dazu, dass die Menschen weder privat noch geschäftlich kommunizieren konnten.
Betroffene Regionen: weltweit → Ausfallanalyse lesen
Erkenntnisse: Ein erfolgreiches SaaS-Business erfordert kontinuierliche Verbesserung. Deshalb ist eine unmittelbare Feedback-Schleife, in der Fehler schnell behoben werden können, notwendig. Wenn Sie über Daten verfügen, mit denen Sie bei einem Fehler im Produktionssystem das Netzwerk als Ursache ausschließen können, können Sie die Lösung technischer Probleme beschleunigen.
Amazon Web Services, 5. Dezember 2022
Was ist passiert? ThousandEyes beobachtete mehr als eine Stunde lang erhebliche Paketverluste zwischen zwei globalen Standorten und der Region us-east-2 von AWS. Das Ereignis betraf End User, die sich über ISPs mit den Services des Cloud-Infrastrukturanbieters in dieser Region verbinden.
Betroffene Regionen: weltweit → Diesen Ausfall in ThousandEyes untersuchen | Ausfallanalyse lesen
Erkenntnisse: Bei Public Clouds ist es wichtig, nicht nur die Applikationen selbst zu überwachen, sondern auch die Komponenten der Cloud-Infrastruktur, einschließlich einzelner Cloud-Regionen und -Verfügbarkeitszeiten sowie aller abhängigen Cloud-Software-Services.
Ausfallzeiten sind unvermeidlich und Ausfälle sind für jeden ISP und Cloud-Provider Realität. Aber wenn Sie sich die Mühe machen, eine widerstandsfähige Infrastruktur aufzubauen, können Sie Ihre Applikationen vor negativen Auswirkungen schützen und gleichzeitig die User Experience verbessern.