


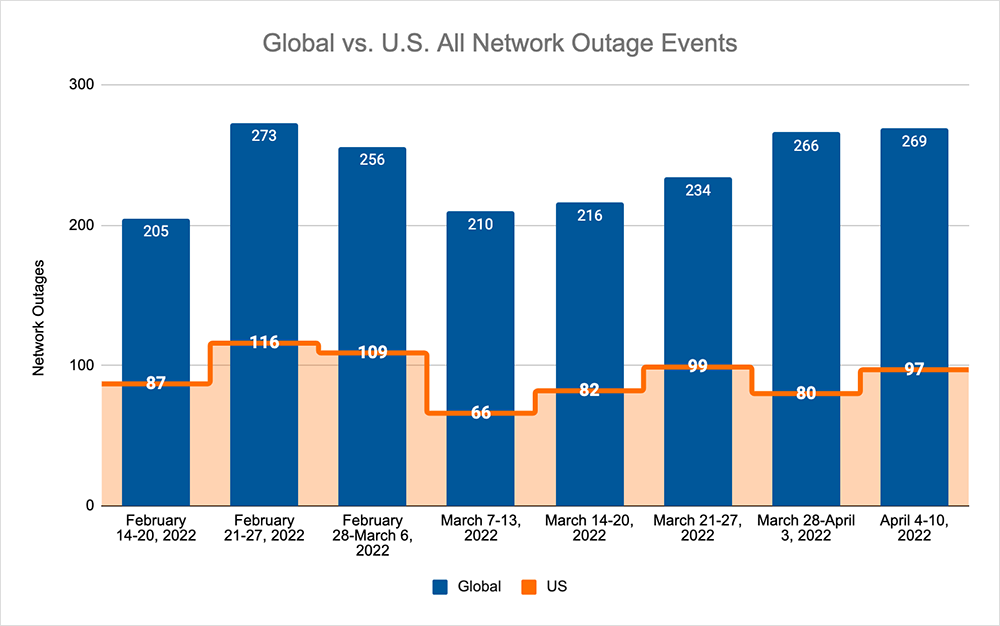
This past week, we saw the return of a familiar occurrence, namely, the status page of a popular website misrepresenting its actual status, although not for the reasons you might think. Before we dive into that, let’s take a look at the outage numbers from last week. The upward trend we’ve been observing since the beginning of March continued this week, as total outages rose from 266 to 269, a 1% increase compared to the previous week. In contrast to last week, this increase was also reflected domestically, where observed outage numbers rose from 80 to 97, a 21% increase compared to the previous week. The increase in domestic outages means that U.S. outages accounted for 36% of all global outages during the week, which was a 6% increase over the previous week (when it was only 30%).
Regular readers will know that we’ve previously explored the disconnect between status pages and reality; the status page historically showing a “sea of green” indicators, as if all systems were online and operational, when, in fact, there were well-publicized customer-facing issues.
This week, surprisingly, we saw almost the exact opposite occur: a status page with a sea of orange and red indicators—the hallmark of a significant outage—but without the corresponding flood of customer complaints and Twitter commentary that one might expect in the wake of such an “issue.”
Let’s first put this into context.
Atlassian, a maker of a number of tools critical to the functioning of development teams worldwide, started reporting problems with several of its biggest tools, including Jira, Confluence and OpsGenie, on the morning of April 5th.
The incident manifested as several cloud instances being incorrectly categorized as “under maintenance,” rendering them inaccessible to the development tools hosted by those cloud instances.
A “partial restoration” for a “cohort of customers” started about 2.5 days after the issues were first acknowledged, according to Atlassian’s status page, although they were unresolved at the time of writing.
Atlassian attributed the cause to “a maintenance script” that unintentionally disabled “a small number of sites.” The company then reportedly “mobilized hundreds of engineers across the organization to work around the clock to rectify the incident,” and said it would “provide post-incident review data with more details on what happened and steps we are taking to ensure this never happens again.”
Clearly, this is an incident that is having some customer impact. The amount of engineering resources being allocated to the incident is a giveaway. Despite this, the customer impact has been relatively difficult to determine throughout the incident.
That’s a bit of an anomaly in our line of work. It’s an outage that publicly presents to be bigger than it actually is.
If this were a widespread or large-scale outage, we’d expect to see a large number of reports from developers on social media platforms like Twitter or forums like Reddit. And, while there are some scattered reports of impact to be found in those places, they are relatively difficult to find. ThousandEyes also represents proof that the impact is being felt unevenly, as fortunately, we’re seeing no significant issues with our Jira instances.
Yet, any Jira or Confluence user that casually hits the status page is going to find a sea of orange and red indicators. They might do as I did, which is to go immediately and double-check that my instances are online, then once confirmed, try to find out who exactly is impacted.
Presumably, a subset of customers are impacted, and the multi-day duration makes this a relatively unusual event, one that would test the patience of anyone directly caught up in it. But it would also be easy to get the wrong impression if the official status page is your primary—or sole—source of performance intelligence.
In a world where the status page often under-emphasizes the extent of an outage, what we’ve seen this week is that it’s also possible for a status page to overstate the impact, as well.
It’s a really difficult balance to strike: say too little or too late, and customers will be upset at the responsiveness; say too much, be overly transparent, and risk unnecessarily worrying a large number of unaffected customers, as well as stakeholders more broadly. I’d be curious for feedback from anyone reading this on how you strike that balance.
A second incident was experienced by American Express on April 1st, which prevented users from getting past a two-factor authentication check and also routed user requests to incorrect pages. The public explanation was of a “systems issue,” with users in the UK and U.S. impacted over a period of hours. Reporting of the incident points to a backend connectivity or routing issue that led to user queries being misdirected by systems. However, it is difficult to pinpoint a cause with any great certainty without knowledge of the company's systems.









