On July 28, 2022, just before 17:00 UTC, Amazon Web Services (AWS) experienced a power failure that disrupted services located within Availability Zone 1 (AZ1) in the US-EAST-2 Region. The outage affected connectivity to and from the region and brought down Amazon’s EC2 instances, which impacted applications such as Webex, Okta, Splunk, BambooHR, and others. While AWS reported the power outage lasted only approximately 20 minutes, some of its customers’ services and applications took far longer to recover—in some cases, up to three hours.

Outage Analysis
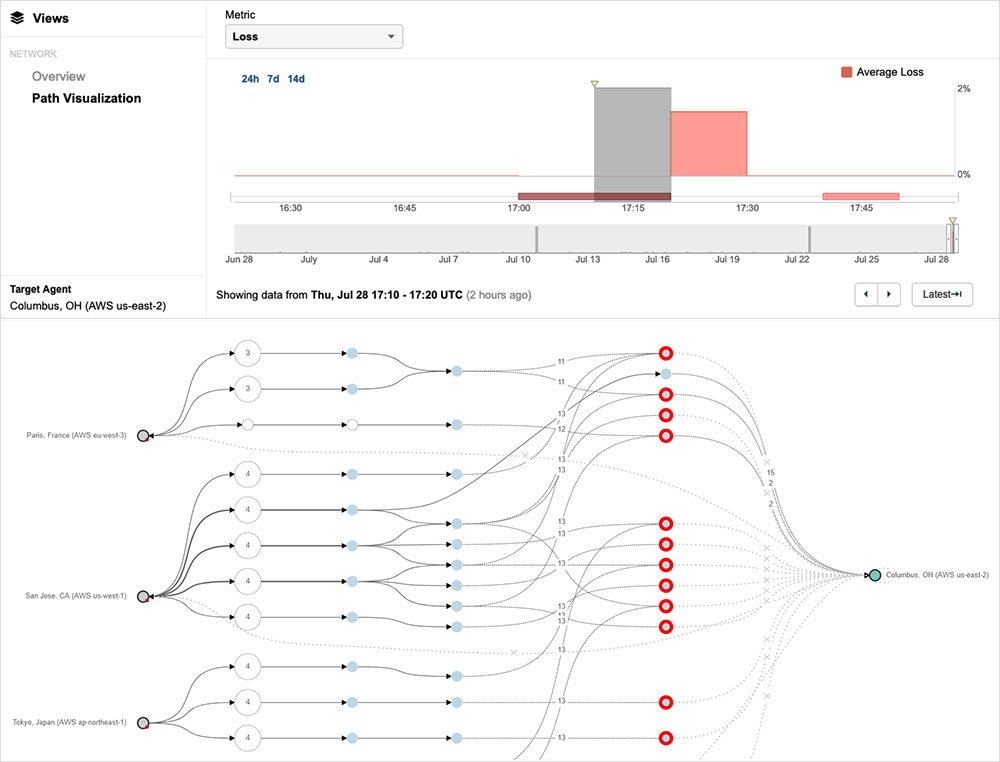
Shortly after the start of the incident, ThousandEyes observed a spike in both application and network outages corresponding with the AWS power outage. Applications hosted on AWS started to see an increase in application errors and, simultaneously, traffic loss was observed on routers in the AWS network (AS 16509 and AS 14618) located in Columbus, OH (see Figure 1 and Figure 2 below).
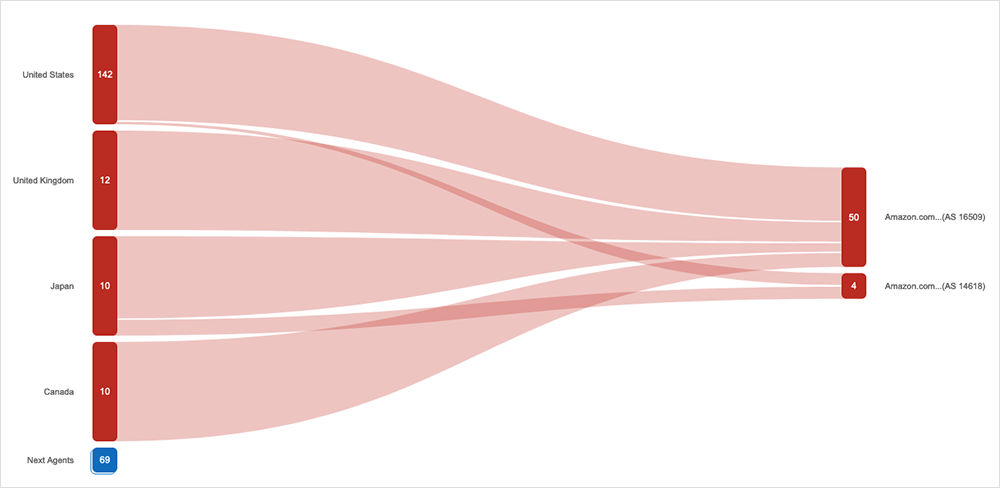
A good look at the impact can be seen at around 17:10 UTC, with several ThousandEyes vantage points located in various AWS regions around the world showing failures connecting to a ThousandEyes vantage point in Columbus, OH, located in the AWS US-EAST-2 AZ1 data center.
Services Affected
The most significant impact was to Amazon’s EC2 service, which powers a wide range of hosted customer applications and which went down in US-EAST-2 AZ1 during the event. Incidents impacting EC2 can affect the reachability of multiple customer and business applications.
ThousandEyes captured the impact that this power loss event had on numerous services and their global users. Here are some examples of the apps and services that were affected.
Webex
Many users experienced issues with the Webex app, preventing them from creating rooms, sending or reading messages, signing in, or sharing files, and even some users reported the Webex status page was presenting an issue.
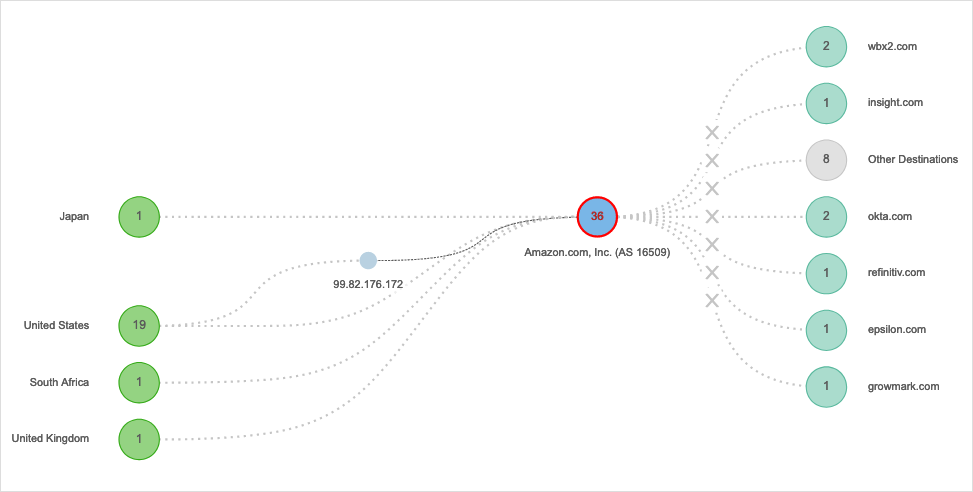
The reason is that while many Webex service components are located in Cisco’s Webex data centers, some others are built on top of AWS. Some of these Webex services use the prefix 170.72.231.0/24, and this prefix is inside the AS 16509 (Amazon, Inc. Columbus, OH, US) and within the affected US-EAST-2 AZ1. One of the impacted Webex services was wbx2.com.
From different tests targeting wbx2.com, we can see how they failed during the power outage for US-EAST-2 AZ1 (as seen in Figure 4). ThousandEyes also captured the problem as a network outage for this target and is seen within Internet Insights™ (as seen in Figure 5).

In Figure 6, we can see how Webex (AS 13445) was unable to communicate with the server hosted on AWS (AS 16509). We can see that for the Columbus, OH, location the test result was presenting 100% packet loss.
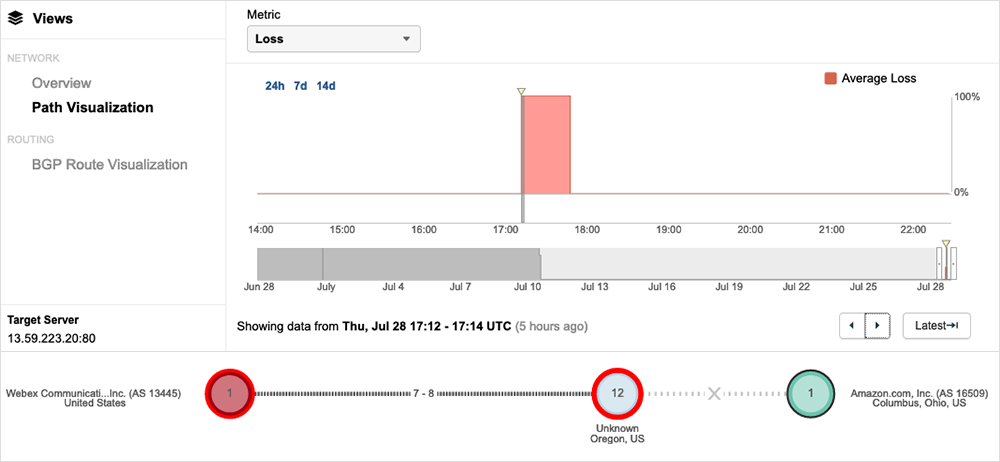
Not all Webex services were impacted, and not every user had an issue with Webex services during the US-EAST-2 power failure. Users near the impacted region experienced problems with some Webex services (i.e., messaging, devices, authentication), whereas users in other parts of the world did not. Webex owns the data centers that deliver the core Webex services and, therefore, these weren’t affected.
Additionally, Webex load balances the network traffic by having multiple Points of Presence (PoPs) in different regions and with different providers, which also provides redundancy to deliver content from other servers located in different regions. The impact to Webex was, therefore, only on some of their microservices that were housed on AWS.
Okta
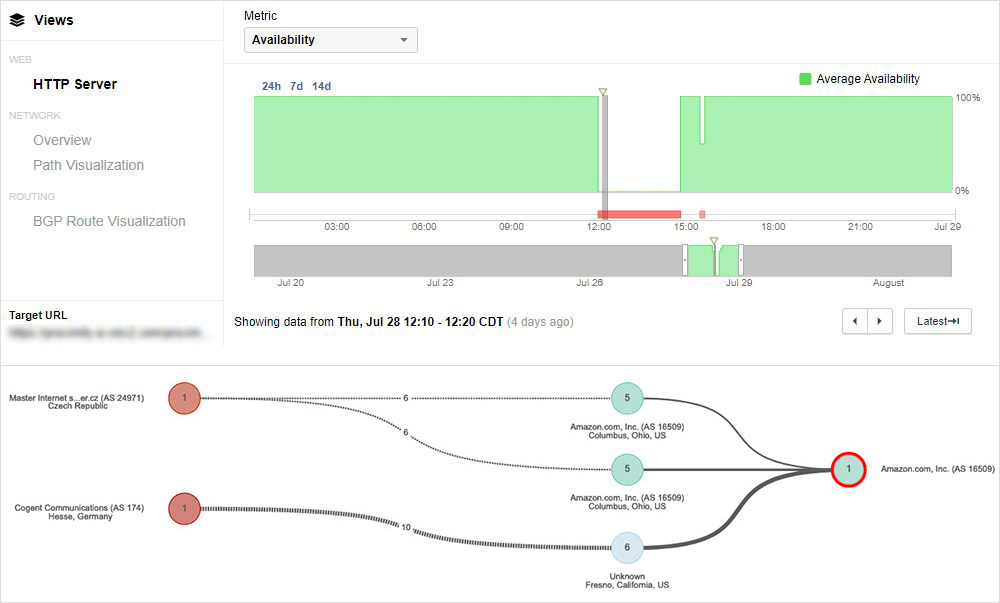
The Okta application was widely affected by the AWS outage. During the event, ThousandEyes observed problems in connecting to a large number of Okta servers.
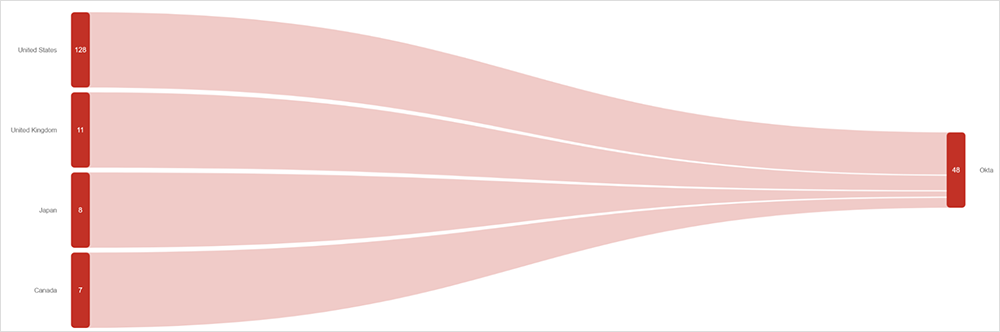
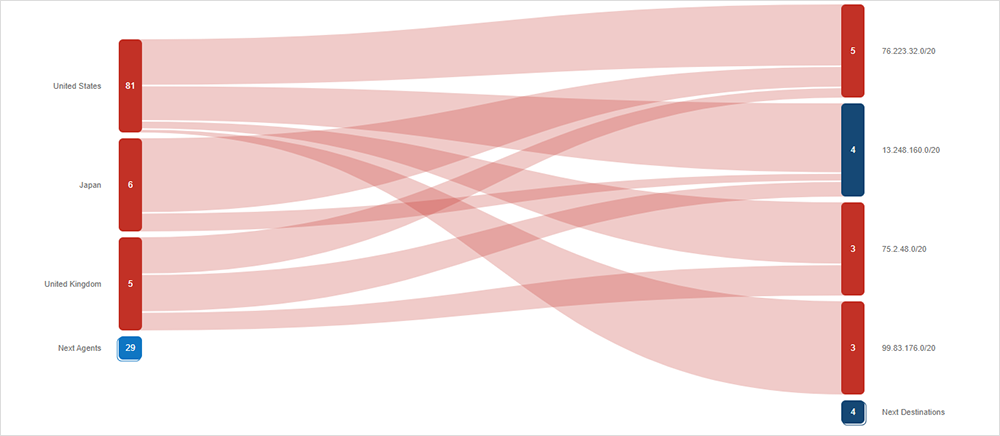
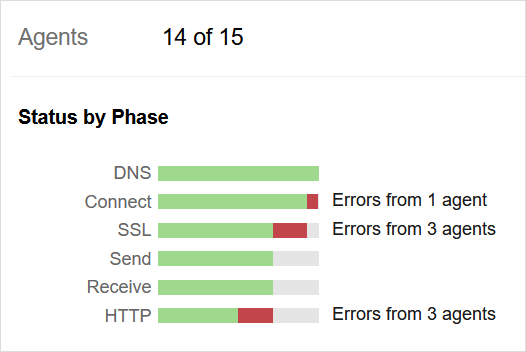
The path visualization shows certain locations were unable to reach Okta during the outage. However, it is important to mention that not all of Okta’s servers were impacted as only those residing in the AWS US-EAST-2 AZ1 network were affected by the power outage. For the tests that did fail, ThousandEyes observed connection failures and SSL and HTTP errors.

Lessons and Takeaways
There’s no soft landing for a data center power outage—when the power stops, reliant systems are hard down. Whether it’s an electric grid outage or a failure of one of the related systems, such as UPS batteries, it’s times like this where the architected resiliency and redundancy of your digital services is critical.
For cloud-delivered applications and services, some level of physical redundancy should be factored in. Even within AWS’s US-EAST-2 region, there are multiple AZs and only one AZ was brought down by the power outage. Having AZ redundancy even within the same AWS region, such as US-EAST-2, would have allowed for the failing over to the other working AZ.
When designing your application services, implementing geographic redundancy or physical infrastructure (e.g., AZ) redundancy should be considered. Alongside this design, knowing how to enact any necessary contingency or failover plans should be known, documented, and rehearsed so that you’re ready to execute should the need arise.
This brings to light the other critical half of this recommendation—knowing when to execute on contingency plans. Without knowing that there is a failure happening, and even more importantly, not knowing where the failure is or which application dependencies are being impacted lengthens the impact to your business. It’s important to have observability of not just end-to-end network performance but also of the performance of your applications and their connected services and components so that we know what is failing and why and how we can work around it. The goal is always to quickly inform IT Operations that a problem is underway, facilitating faster detection and the activation of failover mechanisms.
You can never know when the proverbial plug will be pulled from your data center, but you can ensure that you are seeing everything that you need to see and can rapidly respond and react to restore your services when there’s a fault.





