We often talk in this column about the importance of independent monitoring and visibility across the entire end-to-end network or application supply chain. But, in the age of rapid software development and feature delivery, and of infrastructure-as-code (IaC), the importance of monitoring takes on a new dimension.
When a code change is pushed to production, a policy is changed, or an instance is reconfigured, there needs to be an immediate feedback loop in place that alerts the team making the change to unexpected behaviors observed with other services, or to downstream impacts elsewhere in the network or environment.
An immediate feedback loop is crucial because it reduces the Mean Time to Resolution (MTTR) or mitigation. A rollback of the code or configuration change can be initiated, and the risk of cascading impacts—particularly during front-facing outages—can be minimized.
During the past two weeks, we observed a series of outage traffic patterns that suggest immediate feedback loops aren’t as optimized as they could be.
Zscaler Outage
Zscaler had an outage toward the end of October. It started on October 19, when Zscaler announced service degradation due to a fiber cut in Marseilles, France. The status update declared a “major cable cut” that “may impact transoceanic routes,” and Zscaler escalated the incident in a handful of reports alleging cable sabotage. The unusual part of the incident was that for such a major break, the blast radius (beyond Zscaler) was minimal. Anecdotally, there appeared to be some localized impacts in the South of France, but no major problems for Internet-based companies or providers. The Internet appeared to work as intended, routing around the cut with negligible user impact.
A week later, on October 25, Zscaler experienced major—and independently observable—problems. Traffic destined to a subset of Zscaler proxy endpoints, associated with its zscalertwo.net cloud infrastructure, experienced 100% packet loss, with the most significant loss occurring over a 30-minute period.
The half-hour period between when the initial disruption started and when Zscaler identified the root cause and started remediation highlights the importance of having an immediate feedback loop. It’s clear from looking at the traffic pattern of the incident that once Zscaler acted, things were quickly resolved. The question is whether that “Mean Time to Rollback” and resolution could be reduced further, something that is further canvassed in our in-depth incident writeup.
WhatsApp Outage
On the same day, WhatsApp experienced a global outage that left users unable to connect to their feeds, initiate chats or do anything beyond opening the app and seeing cached data or messages. We observed intermittent connectivity failures that pointed to a backend application or service issue. Due to the time of day, initial reports were most numerous in India and Pakistan, before fanning out into other parts of the world.
The explanation from WhatsApp was reported to be “a technical error on [its] part.” Given the duration of almost two hours and the global nature, this incident also underlines the importance of having an immediate feedback loop available to people and teams making changes to production systems. Teams need to be able to push a change and observe what happens, so they can react quickly if things do not go according to plan.

Salesforce Outage
It was a particularly high-profile outage-laden couple of weeks compared to others this year, with Salesforce experiencing an outage impacting some of its customers globally. The impacts of the outage were first observed around 1:30 AM EDT on October 27. The majority of the disruption appeared to last around 1 hour and 24 minutes and manifested itself as a series of server errors and timeouts, which is consistent with a backend service issue. Around 2:14 AM EDT, Salesforce announced that they were undertaking steps to alleviate the issue. Around 2:35 AM EDT, services appeared to start to return, with the major portion of the issue clearing around 3:15 AM EDT. Around 7:23 AM EDT, the outage was officially cleared.
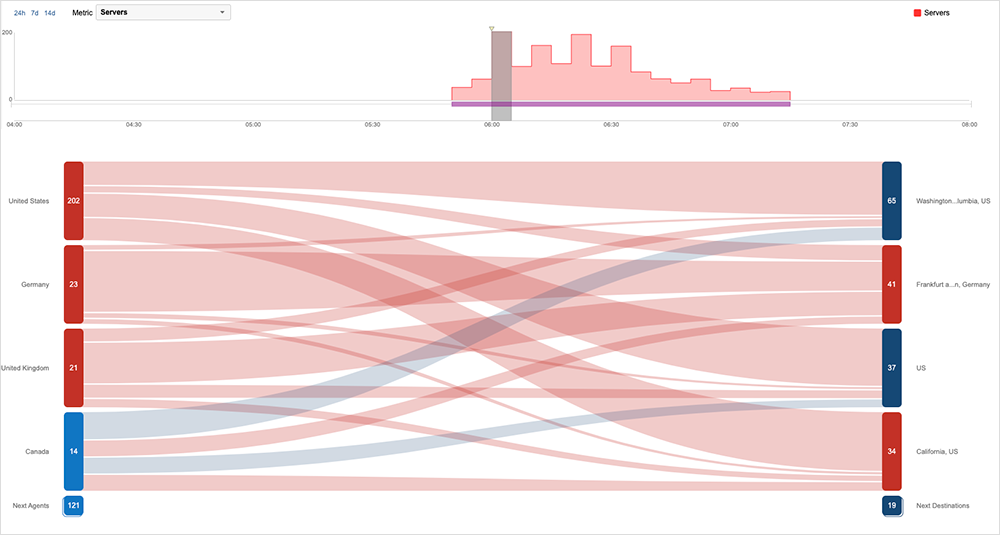
Cloudflare Outage
Cloudflare had issues on October 26. In Cloudflare style, their post-incident report is commendable for its transparency. “A change to our Tiered Cache system caused some requests to fail for users with status code 530,” it says. A 530 status code indicates that the requested host name could not be resolved on the Cloudflare network to an origin server. “The impact lasted for almost six hours in total. We estimate that about 5% of all requests failed at peak. Because of the complexity of our system and a blind spot in our tests, we did not spot this when the change was released to our test environment.”
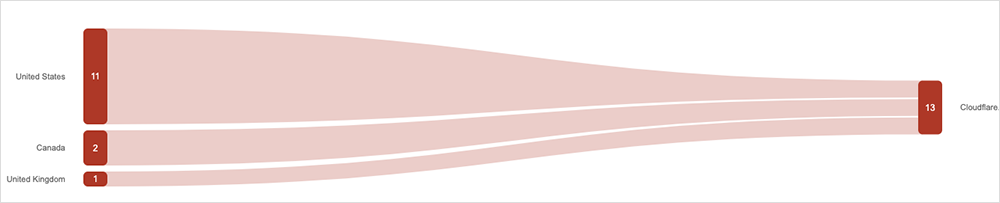
An interesting aspect of the Cloudflare incident is that it was a “slow burn,” where a change at the CDN origin server slowly filtered through to edge servers, leading to a longer overall duration and uneven impact. This is reflected in our observations of the incident: we saw bits and pieces as the origin and edge servers glitched, creating an unusual and drawn-out traffic disruption pattern. It’s also clear that, unlike other providers, Cloudflare has prioritized the use of immediate feedback loops for change management; albeit, they did not work quite as intended here.
Finally, LinkedIn experienced an almost one-and-a-half-hour disruption on October 20. The cause appeared to be in the backend, and impacts manifested as feeds not loading and an inability to post or comment. It is difficult to pinpoint the root cause with any certainty, however, due to the way the service is architected and handles user requests for data.
Internet Outages and Trends
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
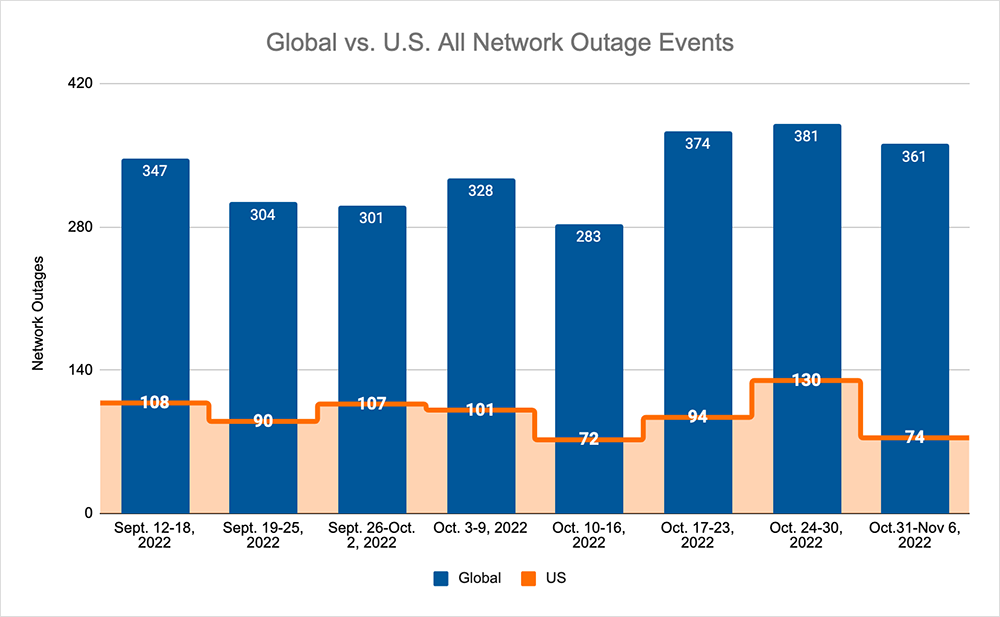
- Global outages continued the recent upward trend, rising from 374 to 381 initially, a 2% increase compared to October 17-23, before decreasing the following week, where we observed a drop from 381 to 361, a 5% decrease when compared to the previous week.
- This pattern was reflected domestically, with an initial rise from 94 to 130, a 38% increase compared to October 17-23, before dropping from 130 to 74, a 43% decrease from the previous week.
- US-centric outages accounted for 27% of all observed outages, which is larger than the percentage observed on October 10-16 and October 17-23, where they only accounted for 26% of observed outages.