The most significant packet loss lasted approximately 30 minutes, after which there was considerable improvement, and packet loss to the impacted Zscaler endpoints began to subside. For the majority of user locations, connectivity to the Zscaler endpoints was restored by 12:32 UTC, although some reachability issues and packet loss spikes persisted intermittently for some user locations over the next three hours. Connectivity was fully restored for all user locations by approximately 15:34 UTC.
Outage Analysis
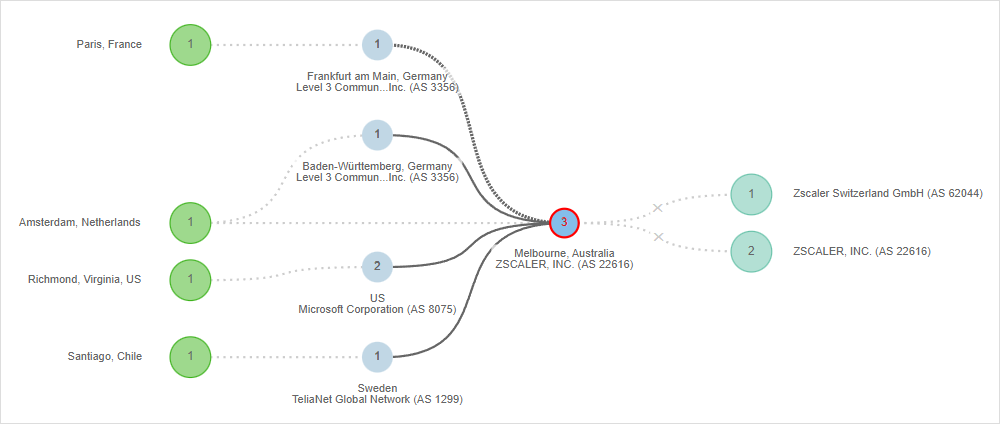
ThousandEyes observations show the sudden onset of the incident, which is consistent with a Zscaler statement citing a maintenance issue that impacted the zscalertwo.net cloud and affected the VIPs of the proxy devices. Figure 2 shows a spike to 100% packet loss for traffic sent to a ZIA proxy device.
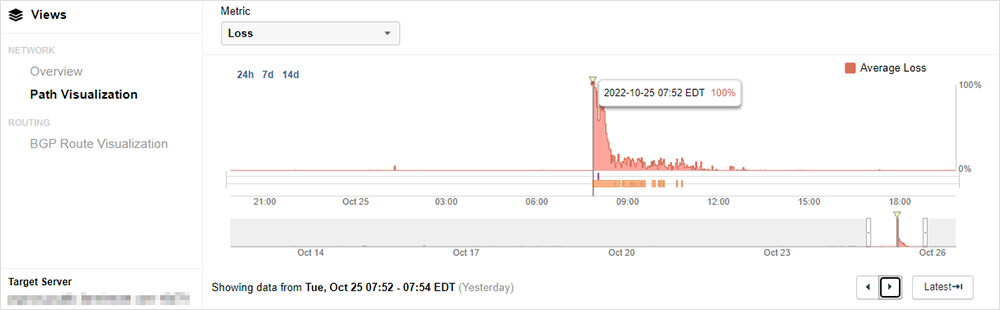
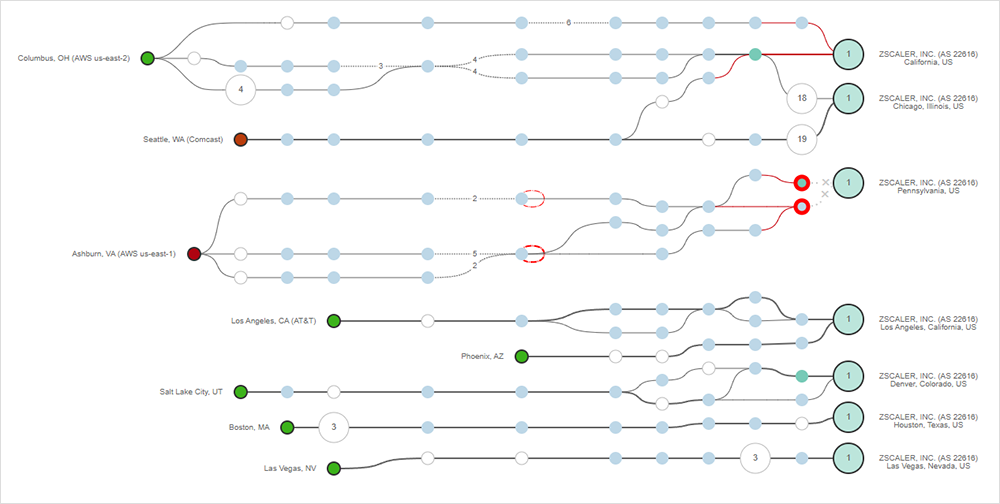
Zscaler noted that the issue began at 11:46 UTC and that by 12:42 UTC they had identified the root cause and were working to mitigate the issue. Shortly after they acknowledged the event, it appears that they performed mitigation measures, and ThousandEyes saw connectivity to the ZIA services on Zscaler cloud 2 begin to restore. In Figure 3, reachability is shown to be restored for most ThousandEyes vantage points, although some locations were still experiencing connectivity failures or high latency in reaching the impacted Zscaler proxies.
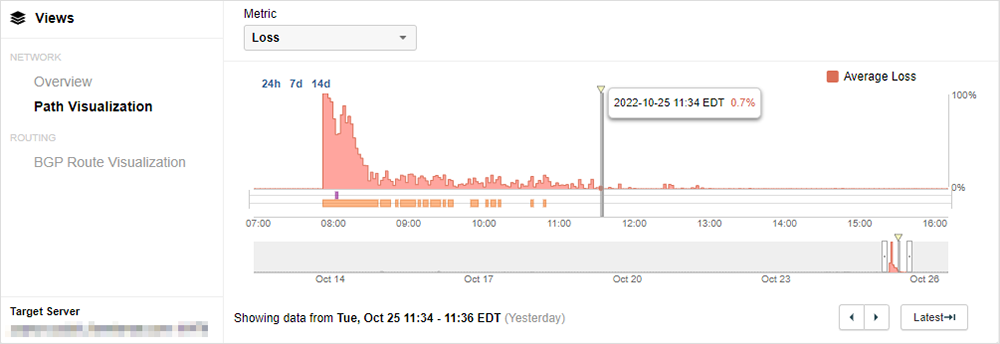
Zscaler announced that 80% of services had been restored by 15:25 UTC. This aligns with ThousandEyes no longer observing any intermittent reachability failures by approximately 15:34 UTC. As shown in Figure 4, connectivity was restored, and the spikes in packet loss are no longer present.
The Challenges of Visibility and SaaS
Zscaler subsequently identified the issue on their status page as a “traffic forwarding issue.” Essentially, the virtual IP (VIP) of the proxy device became unreachable, resulting in an inability to forward traffic. This may have affected a variety of applications for enterprise customers using Zscaler’s service, as it’s typical in Secure Service Edge (SSE) implementations to proxy not just web traffic but also other critical business tools and SaaS services such as Salesforce, ServiceNow, and Microsoft Office 365. The proxy is therefore in the user’s data path and, when the proxy isn’t reachable, the access to these tools is impacted and remediation often requires manual interventions to route affected users to alternate gateways.
The potential impact of a network change is a constant fear for IT operations. IT change management processes are complex, with network operators concerned about what can go wrong any time the network is touched, particularly when configuration changes are made.
Interestingly, Zscaler recently reported on a fiber cut occurring in France that they detected as a user of that infrastructure. Similarly, AWS was impacted by an unpredictable hardware event with a recent power outage impacting one of their availability zones. Despite having UPS backup batteries and lots of redundancy, power events can still take down a major cloud provider data center. However, these types of hardware faults will typically be protected by the underlying resilience of infrastructure design. Rarely is a fiber cut felt by customers unless it’s in the last mile before your data center or in a similarly critical position. Cloud architects will leverage multi-zone software stacks to keep their systems running should a power event take down a cloud availability zone.
When it comes to network changes, however, all bets are off. With network and software maintenance, upgrades, or changes it’s quite possible to alter the state of the network in such a way that redundancy or resiliency mechanisms do not kick in or trigger an elusive gray failure that’s hard to identify. Change management, therefore, requires the same protections and the same ability to assess application performance, network state, and the health of the infrastructure that IT operations teams require to keep the lights on and users happy. Which is why having before and after snapshots of application and network performance is so critical, as this enables IT to gauge whether or not a change rollback is needed.
Lessons and Takeaways
After experiencing an outage or performance impact, IT teams will be asked to answer the question of, “How do we do better next time?”, which may feel like being asked, “How do we avoid the unavoidable?” Architecture is generally the first line of defense. If problems can’t be avoided, how can the architecture enable resilience in the face of inevitable faults? Infrastructure design, proper monitoring, and the necessary reactive IT operations processes can all help with the unavoidable. When it comes to network maintenance triggered outages, however, these can have unpredictable and wide-ranging effects that even the best of designs cannot accommodate. To prepare for these events, the right visibility can greatly lessen the impact and duration.
No solution or service is immune to issues, but isolating the root cause can be a tremendous challenge. Further complicating this is the ubiquitous use of specialized network solutions, such as cloud services or CDNs, adding more pieces to the puzzle when things go awry. Is it my ISP? Is it in my environment or is it on the public cloud or SSE provider side? IT teams must be able to quickly isolate fault domain and attribution, so they know who to call and how to mitigate a problem. Which is why independent visibility is extremely important in these complex scenarios to help better understand when specific use-cases, applications, or users are impacted and why—enabling much quicker remediations.





