This is the Internet Report: Pulse Update, where we review and provide analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. Every other week, I’ll be here, sharing the latest outage numbers and highlighting a few interesting outages.
We’re headed into the new year with a refreshed format for this series. You can read our full analysis below as you always could, or watch (or listen to) our new podcast to hear our commentary first-hand. This week, in addition to our usual look at global and U.S. outage trends, we’ll take a brief look at some interesting events with Twitter, Autodesk, Microsoft, and AWS.
It’s now been several weeks “under new management” at Twitter, and there’s been a lot of public discussion about how resilient the social media platform’s architecture would be given the combination of mass layoffs and resignations. There were fears at one point that the staff had been reduced so substantially that the application might not survive a weekend.
But, as we now know, Twitter didn’t buckle, and there’s been no specific large-scale outage since the company changed hands. That’s a testament to the resiliency of its architecture and to the years of engineering work invested in its infrastructure and core systems.
In fact, the company’s last major network-related problems were in March, when a BGP hijack rendered its services inaccessible, and again in September, when heatwave conditions exposed a key data center dependency in its application architecture.
That isn’t to say Twitter hasn’t experienced issues, however. Since the sale of Twitter was completed in late October, we’ve observed three main types of issues:
- A higher frequency of spotty, short-duration backend issues that throw 5xx and 4xx errors at users
- A redirect loop resulting in laggy performance and timeouts when trying to access the application
- Unresponsive services that impacted functionality, such as the delivery of SMS codes used in two-factor authentication
Backend Issues
Prior to the change in ownership, application errors, degradations or glitches impacting the Twitter application and backend were sparse—a handful every few days, but nothing that would be perceptible to users.
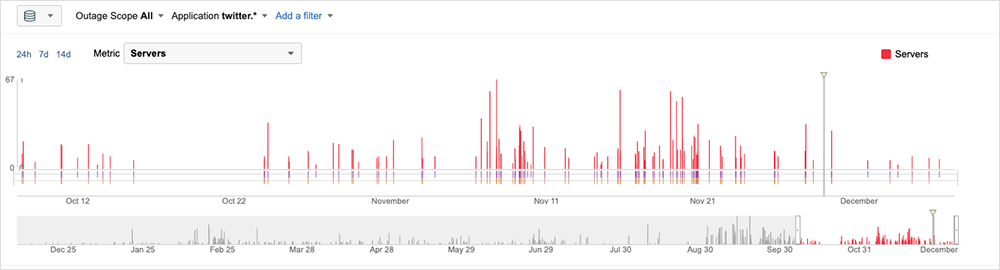
From a monitoring perspective, what we’ve seen since could be indicative of an unprecedented amount of chaos-like testing of the application architecture and support infrastructure. The longest issue we observed lasted 11 minutes, though durations of one to four minutes were the most common. Users could still load Twitter, but the application often had delayed or missing content elements.
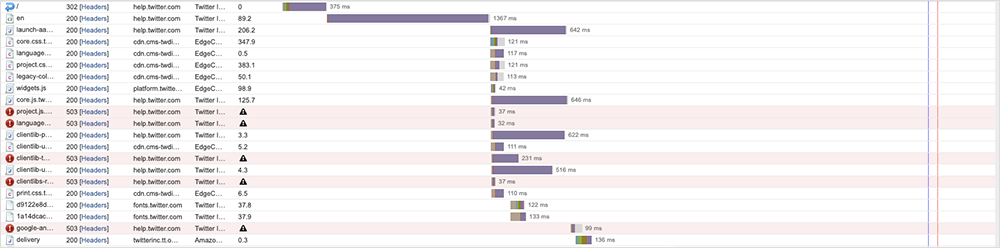
Short-duration incidents may be indicative of small tweaks or even some form of chaos engineering
exercise with automated process and recovery reacting to degradations or errors, but everything we observed had the characteristics of backend issues as opposed to network or infrastructure issues. As a side note, the number and frequency of outages dropped to zero over the Thanksgiving holiday.
Redirect Loop
Another class of issues seemed to stem from a request simply redirecting until it timed out. This manifested in a continuous serial pattern, with each redirect following one that had just finished.
There can be a number of reasons for this. While we cannot know definitively, the intermittent nature of the condition would indicate it is not specifically within the code of the application, but more likely a result of some changes behind a load balancer that are being made in pursuit of optimization, but that do not complete as intended.
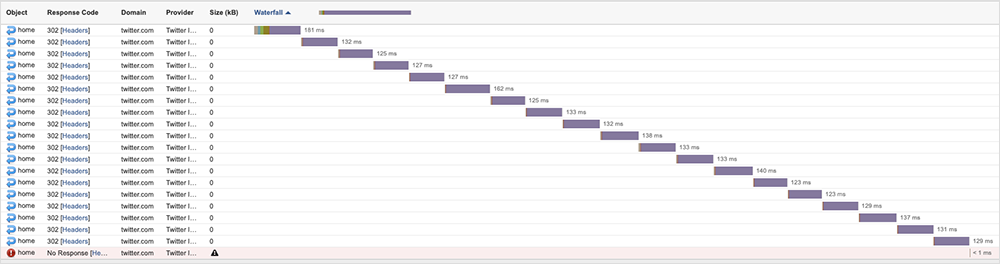
As with all of our observations, it was very short-lived and wouldn’t have resulted in the user experiencing a complete outage, but, depending on where they were in the flow (e.g., logging on, loading a thread, etc.), it would have likely manifested as “laggy” performance.
Unresponsive Services
The other issue we observed was a service that had become unresponsive. This was sometimes as part of a process (for example, when a backend service on different infrastructure was called) and sometimes whole services would momentarily become unresponsive, as if they were missing. In both scenarios, the functionality appeared to be impacted.
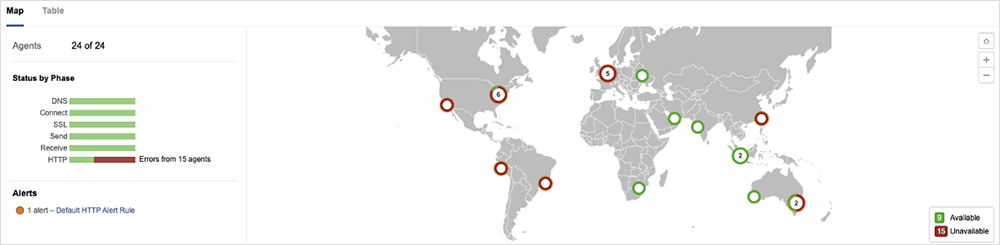
What’s next?
All in all, the performance issues outlined above have been nowhere near as catastrophic as some speculated they might be. But as with all SaaS, we can never call an all-clear, and we’ll continue to monitor for performance changes – good or bad.
Autodesk Outage
A large-scale outage at architecture and engineering software maker Autodesk on November 17 reportedly rendered its software inaccessible for a full day. Multiple users reported work being at a standstill.
The root cause was an issue with Autodesk’s Identity Authorization Service, meaning users could not authenticate in order to gain access to the cloud-based Autodesk software.
This kind of outage is not unprecedented. Identity services are the gateway to all cloud-based products. We’ve seen issues—with Azure Active Directory, for example—cause services like Microsoft 365 to become inaccessible for users on multiple occasions—see December 2021 and August 2022 for examples. The fact that you can’t verify authentication means you never get past the login page.
Microsoft Outage
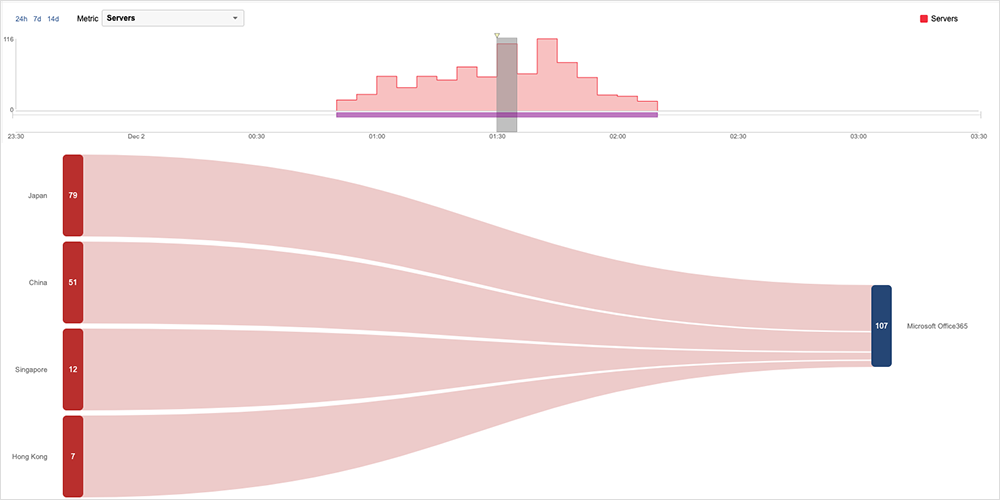
As December began Microsoft experienced an issue that appeared to affect users across the Asia Pacific region. The disruption was first observed around 7:50 PM EST on December 1, seemingly impeding users’ access to some Microsoft services, including Microsoft 365, with general functionality, such as sending emails and files, affected. The major portion of the disruption lasted approximately 1 hour and 18 minutes, and appeared to originate in Microsoft infrastructure located in Japan before radiating to other Microsoft servers in the region.
Microsoft's preliminary analysis identified an issue related to a legacy process that, in isolation, was not problematic, but when combined with large numbers of requests, resulted in resource saturation that subsequently impacted multiple Microsoft 365 applications. It appears that Microsoft was able to mitigate the outage by transitioning away from the legacy process and restarting the affected infrastructure, at which point access to the service began to recover.
Amazon Web Services (AWS) Outage
On December 5, just after 2:30 PM EST, AWS’s Ohio-based us-east-2 region experienced connectivity issues that appeared to cause packet loss for some AWS customer traffic as it transited between us-east-2 and a number of global locations. The loss was seen only between end users connecting via ISPs, and didn’t appear to impact connectivity between instances within the region, or in between regions. The packet loss continued for more than an hour before resolving around 3:50 PM EST.

Internet Outages and Trends
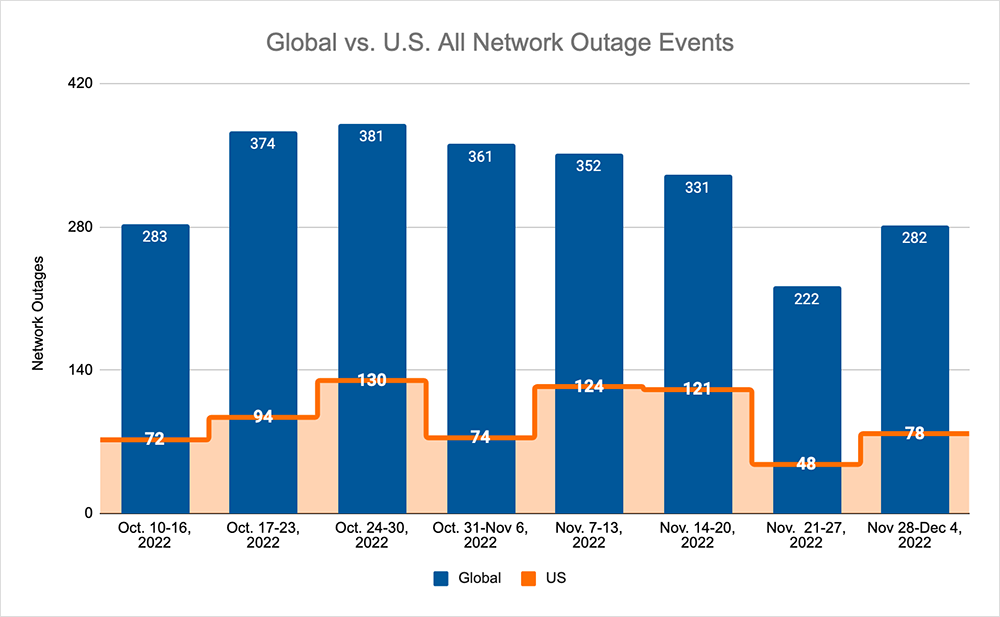
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
- Global outages continued the downward trend seen over the previous three weeks, dropping from 331 to 222, a 33% decrease compared to November 14-20. Before rising from 222 to 282, a 27% increase when compared to the previous week.
- This pattern was reflected domestically, with an initial drop from 121 to 48, a 60% decrease compared to November 14-20, before rising from 48 to 78, a 63% increase from the previous week.
- US-centric outages accounted for 27% of all observed outages, which is smaller than the percentage observed on November 7-13 and November 14-20, where they accounted for 36% of observed outages.