Summary of Findings
Based on ThousandEyes’ broad visibility into Internet networks, we observed the following:
- The incident appeared to be triggered by the withdrawal of a large number of Rogers’ prefixes, rendering their network unreachable across the global Internet. However, behavior observed in their network around this time suggests that the withdrawal of external BGP routes may have been precipitated by internal routing issues.
- Because Rogers continued to announce at least some of its customers prefixes, traffic continued to flow into its network but could not route properly, leading to the traffic terminating in their network. This behavior suggests an internal network control plane issue may have been an underlying factor in the incident rather than strictly due to external BGP route withdrawals, which has been widely reported.
- Shortly after the initial withdrawal of routes, Rogers was able to reinstate some prefix advertisements, which restored availability for parts of its service; however, the same withdrawal (and eventual readvertisement) behavior was repeated several more times causing varying levels of impact until the incident was fully resolved.
- The scale and overall duration of the incident suggests an internal control plane issue that took time to be discovered given that the initial route withdrawal was repeated multiple times throughout the incident, possibly due to the underlying cause of the incident getting inadvertently retriggered.
- Given that the incident began at a time that is typical of service provider maintenance windows, the incident may have been triggered by network changes made during a planned update.
Outage Overview
Last week, in the early hours of July 8th (04:44 EDT / 08:44 UTC), ThousandEyes began observing BGP routing instability caused by the withdrawal of large numbers of Rogers Communications (AS 812) prefixes.
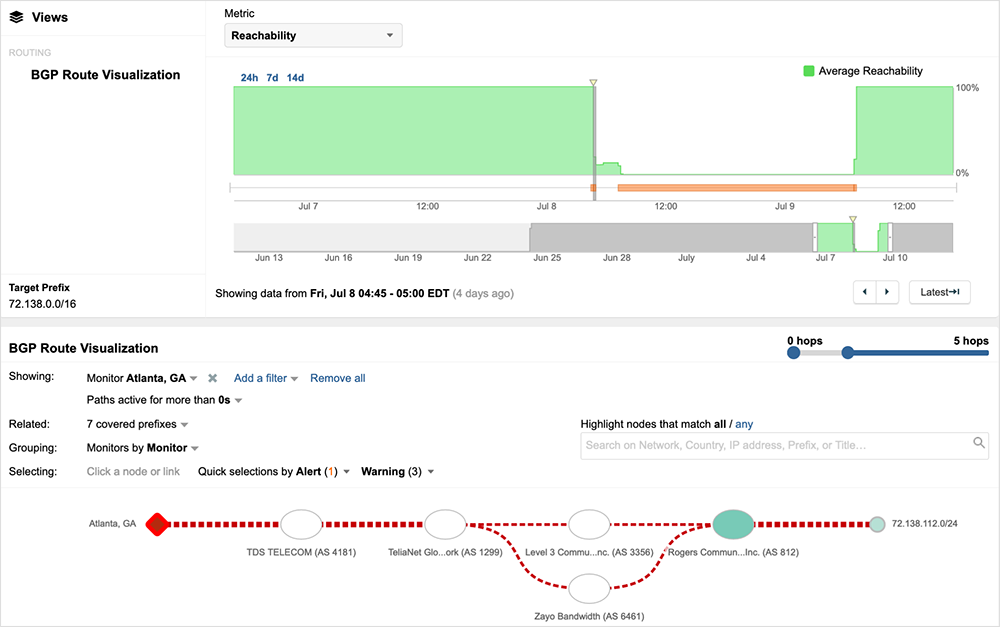
The withdrawal of routes from a densely peered service provider like Rogers can lead to an extended period of network convergence as routes are propagated across the global Internet. Service provider routing tables will get rapidly updated as they attempt to find a viable route to the destinations covered by the withdrawn prefixes.
Figure 2 shows traffic dropping at the egress of neighboring ISP networks during an initial period of route instability.
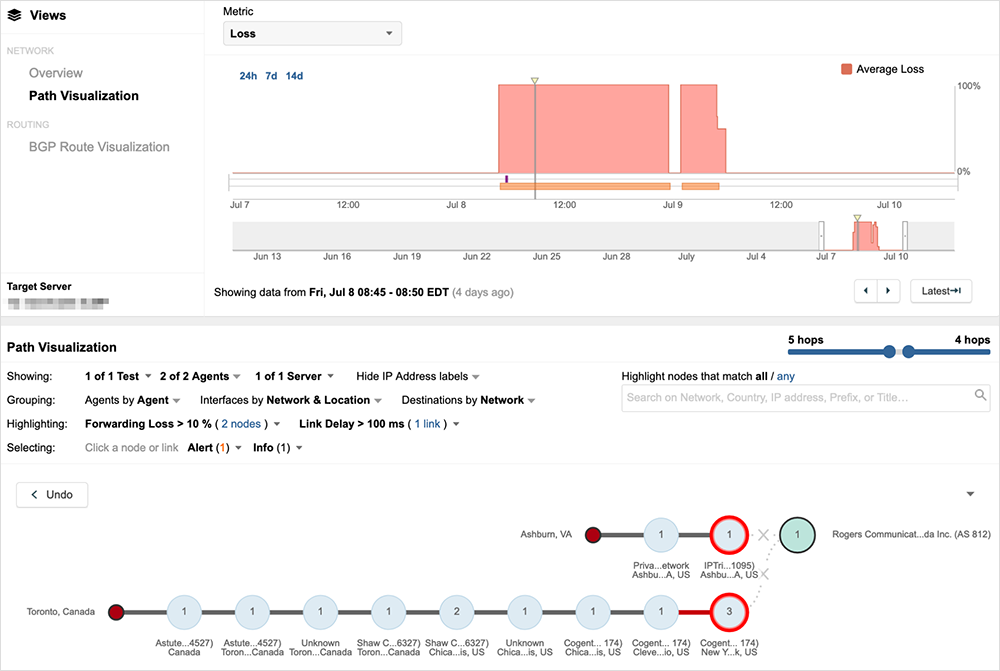
Because the originator of the prefixes (in this case, Rogers) had withdrawn them, no viable route was available and service providers will eventually remove the routes from their routing tables. At that point, with no provider advertising a path to Rogers, traffic would have dropped closer to the source of the traffic, at Internet egress, as shown in figure 3, where traffic is dropping at the edge of the source network.
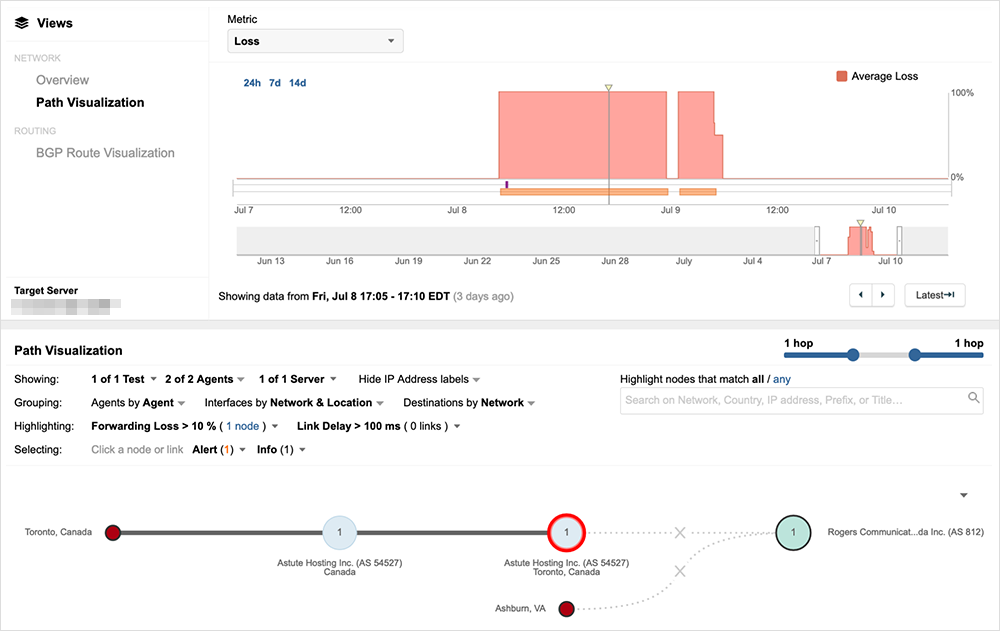
Regardless of where traffic loss occurred, the outcome was the same—many users and services using Rogers’ network would have been unreachable.
Some service restoration occurred at various points throughout the incident for some users, with Rogers readvertising some prefixes and then, after a varying period of time, again withdrawing its routes.
By 08:30 UTC on July 9th—nearly 24 hours after the start of the initial disruption—the service had finally stabilized in an available state for most users.
Outage Analysis
While the withdrawal of Rogers’ prefixes would have prevented traffic from reaching their network (consistent with the broad reachability issues observed), other behavior seen during the incident suggests that the external BGP routing issues were only one manifestation (and, possibly) a byproduct of another issue. Traffic routing behavior seen within Rogers’ network around the time of the withdrawals suggests that there were significant routing problems within its network that prevented it from successfully forwarding traffic.
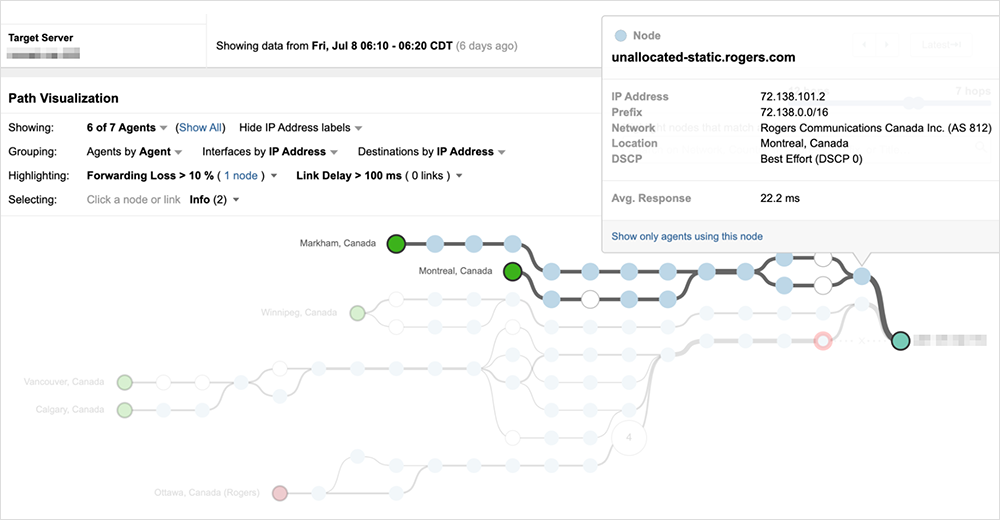
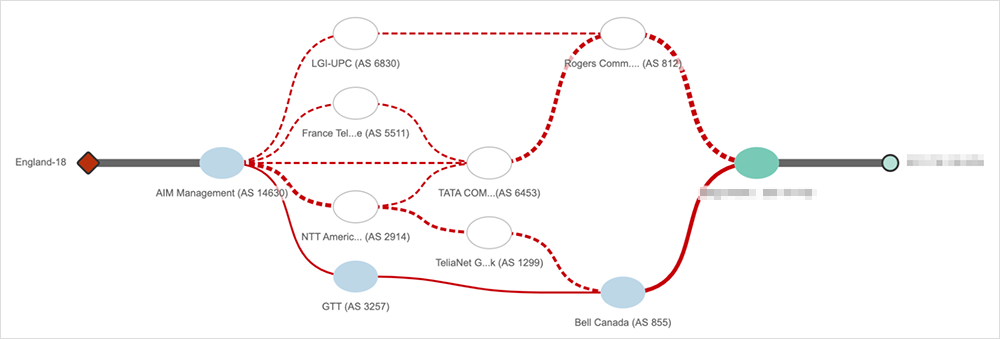
Since Rogers continued to advertise at least some of its customer’s prefixes, conditions within Rogers’ network could continue to be observed. Figure 5 below shows a customer of Rogers—who is also connected to Bell Canada (AS 855)—just a few minutes before the incident began.
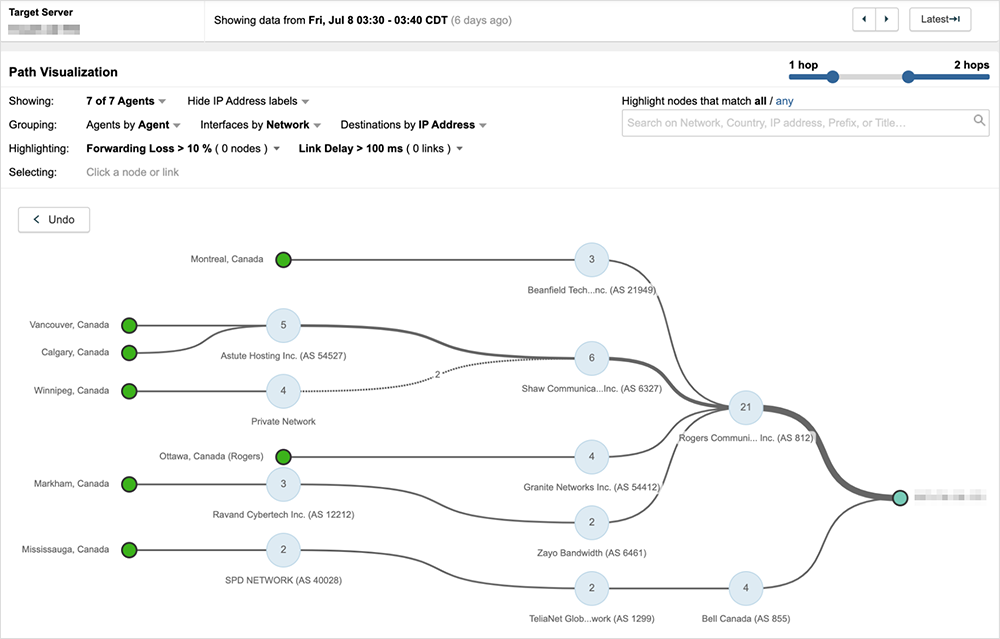
As the incident unfolds, most traffic destined to the customer is going through Rogers’ network compared to Bell Canada, so once the incident starts, 100% packet loss is observed across most paths.
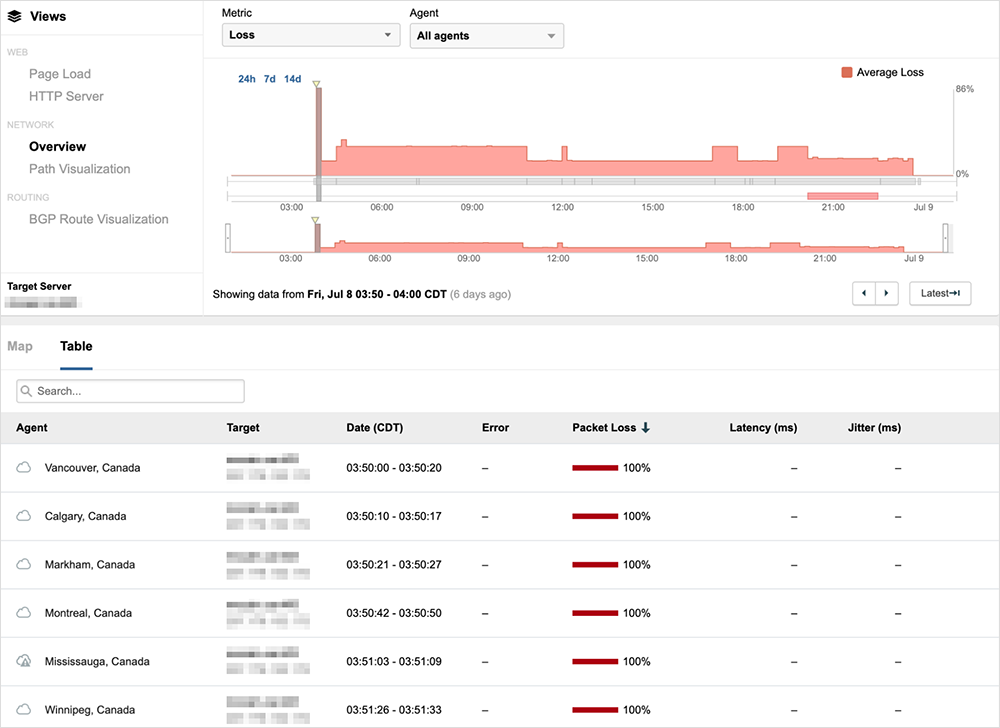
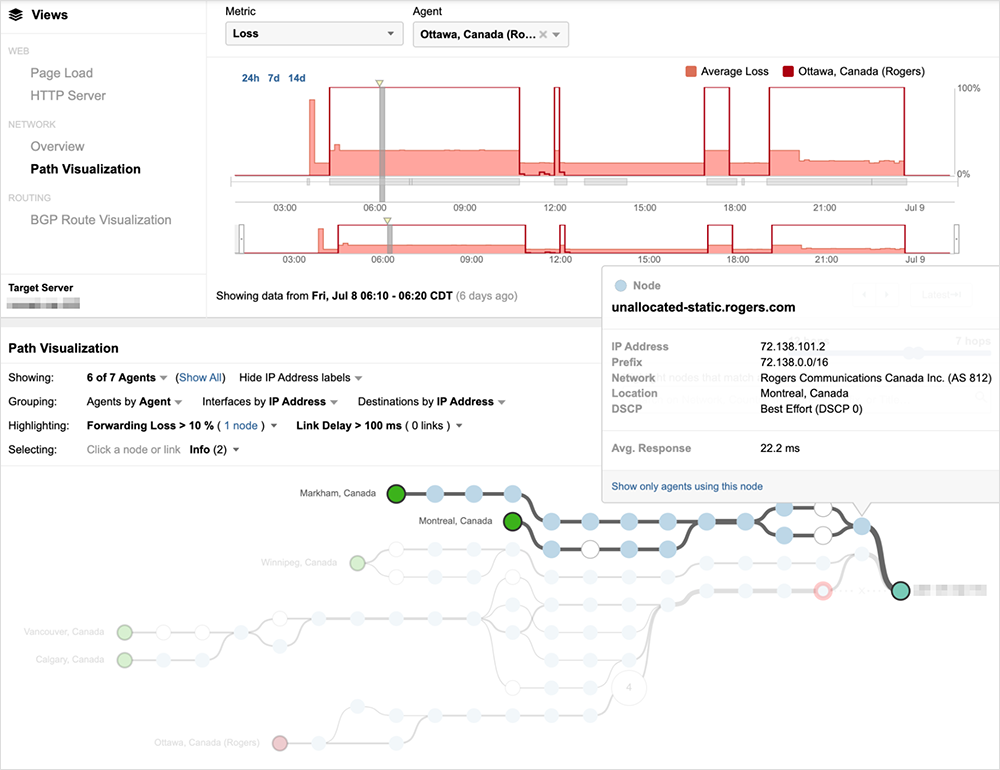
However, unlike the previous examples, traffic is not dropped prior to reaching Rogers’ network. Instead, traffic destined to the customer’s prefix enters Rogers’ network and begins to loop internally until the traffic ultimately times out and is dropped.
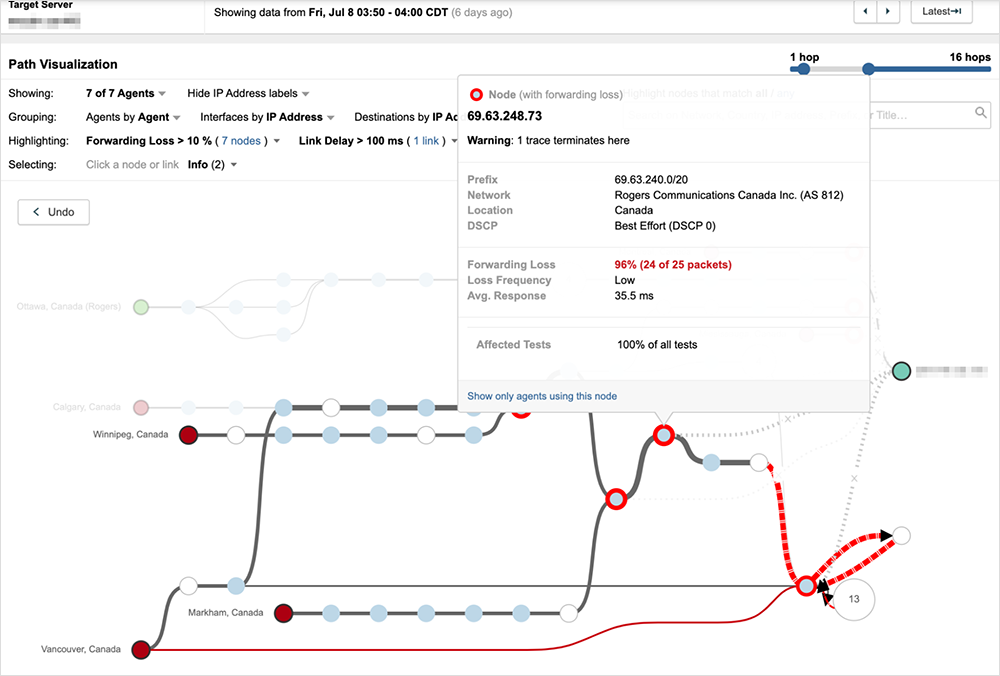
Looking at the interfaces the traffic passed through within Rogers’ network reveals the severity of the looping issue, as seen in figure 8, where traffic repeatedly loops through the same router interface more than half a dozen times.
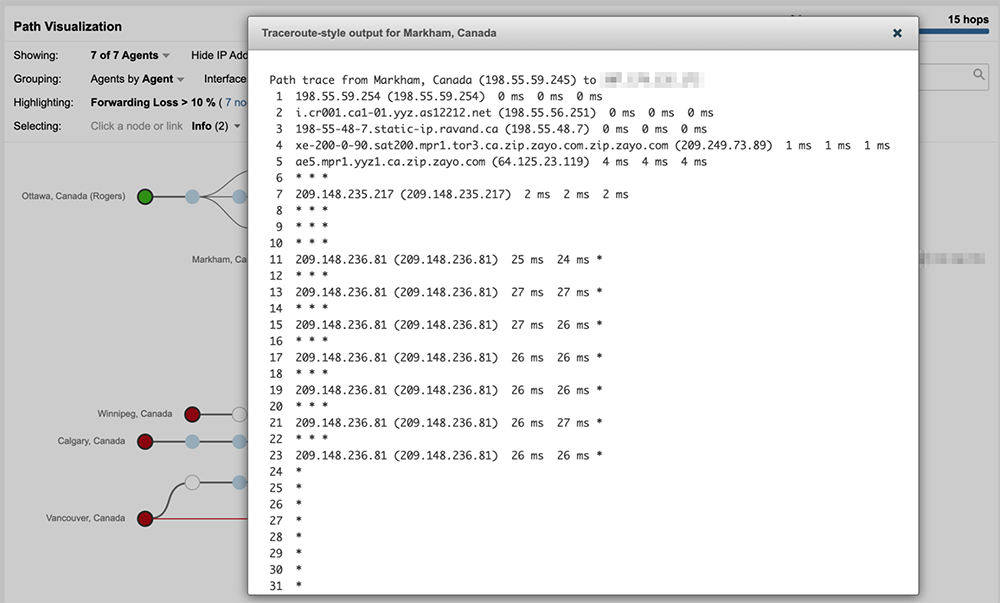
Rogers’ continued advertisement of its customer’s prefixes during this time enabled traffic to enter its network, but once inside the network, there appeared to be internal routing issues that prevented traffic from progressing to its destination, suggesting a broader issue impacting its control plane.
Given the timing of the measurements directly before and after the external BGP withdrawals (several minutes before and after), it’s difficult to definitively determine whether the internal routing issues precipitated the incident; however, such a scenario would reflect behavior designed to ensure network (in this case, Internet) resilience. If parts of a network become incapacitated because routing is not functioning, withdrawing external routes could be expected behavior—as was the case in the Facebook outage last year, when an internal issue triggered an automatic withdrawal of some external routes. In that case, the BGP withdrawals were simply a byproduct of the triggering event and even if the routes had not been withdrawn, the service would not have been available.
Regardless of the underlying cause, from a customer standpoint, impact is of greater importance. In the case of the customer shown above, because they were also connected to Bell Canada, routing eventually reconverged around routes through that service provider approximately 15 minutes after the start of the outage.
Long stretches of availability followed by route instability and service disruption may indicate that Rogers was not aware of the specific change that triggered the routing issues, leading to repetition of the precipitating event and resultant service disruption.
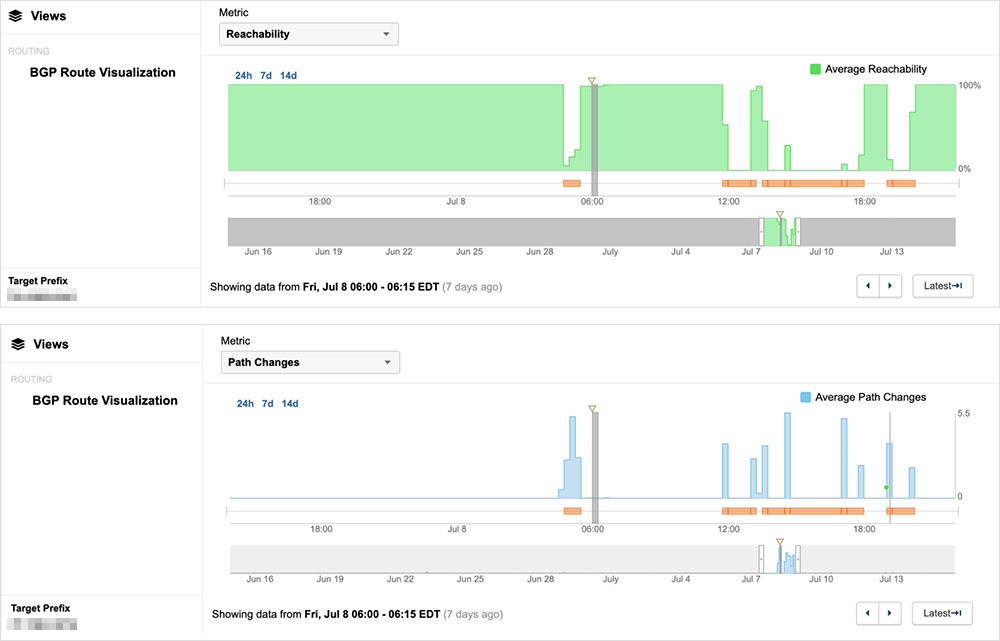
During periods when some of Rogers’ prefixes are reachable, traffic flows normally for some users, as seen in figure 11.
Lessons and Takeaways
Outages are inevitable and no provider is immune to them, including operators of the largest networks and services, such as Facebook, Google, and AWS. However, outage impact can vary widely depending on whether enterprises have taken steps to reduce their risk and increase their responsiveness. This outage was an important reminder on the need for redundancy for every critical service dependency. Here are some takeaways from this outage and its enterprise customer impact:
- Diversify your delivery services—having more than one network provider in place or at the ready will reduce the impact of any one ISP experiencing a disruption in service.
- Have a backup plan for when outages happen, and be sure you have proactive visibility in place so you know when you need to activate your backup procedures (such as revoking a BGP announcement to an ISP having an outage so your users are routed around the problem).
- Understand all of your dependencies—even indirect, “hidden” ones. For example, if you rely on external services for site or app components, be sure to understand their dependencies, such as their ISP providers, so you can ensure they are also resilient.
Continuous visibility into the availability of your services over the Internet will ensure you have proactive awareness of potential issues and enable you to respond quickly to resolve them.




