


This past week was an eventful one on the Internet as we saw a complete loss of data services to an Australian state, a loss of access to core systems at a major airline and a loss of service at two cloud-based productivity tools.
All four instances resulted in service impacts that, while varying in severity, were felt by end users and carried residual impacts. Before we delve into these outages, let’s take a look at the overall outage numbers for the week.
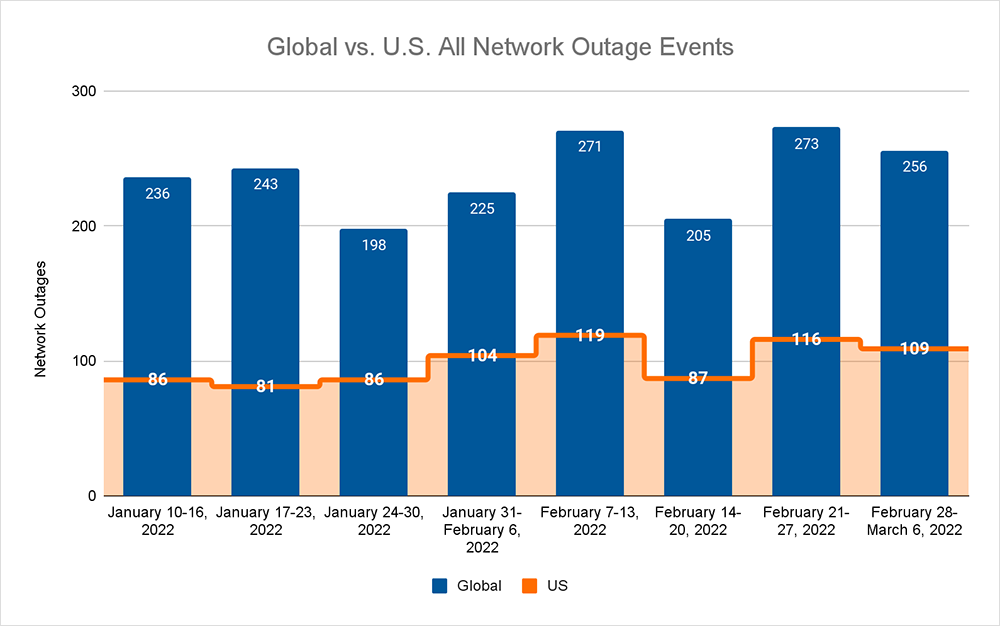
For the week, we saw total global outage numbers decrease, dropping from 273 to 256, which is down 6% when compared to the previous week. This decrease was mirrored domestically, where outages dropped from 116 to 109, which is also down 6% when compared to the previous week. With this parallel decrease, U.S. outages accounted for 43% of all total global outages, which was slightly higher than the previous week (which was 42%), but U.S. outages remained in line with the average percentage of weekly contributed outages observed across 2021.
On February 25, British Airways was reportedly forced to return to paper-based processes when its online systems became inaccessible. According to reports, flights couldn’t be booked and travelers couldn’t check in to flights electronically. Hundreds of flights were delayed or canceled, and there were subsequent impacts on passengers and baggage already in the system.
According to media outlets, the official explanation was unspecified “technical issues.” Our monitoring showed that the network paths to the airline’s online services (and servers) were reachable, but that the server and site responses were timing out.

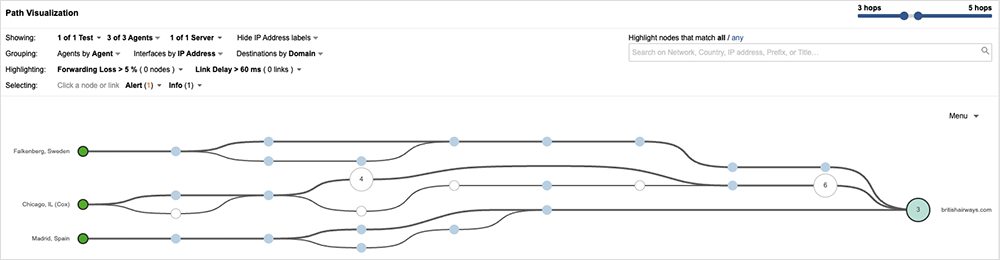
The nature of the issue, and the airline’s response to it, suggests the root cause is likely to be with a central backend repository that multiple front-facing services rely on. If that is the case, this incident may be a catalyst for British Airways to re-architect or deconstruct their backend to avoid single points of failure and reduce the likelihood of a recurrence. Equally possible, however, is that the chain of events that led to the outage is a rare occurrence and can be mostly controlled in future. Time will tell.
We also saw outages to a pair of productivity suites, Monday.com and Microsoft 365.
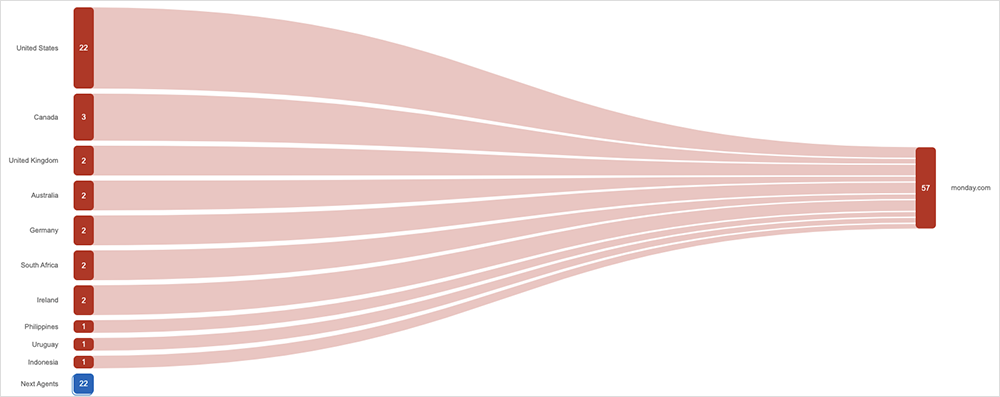
Monday.com experienced “connectivity issues” on February 27 that resulted in about 30 minutes of total downtime. Our monitoring shows that this incident wasn’t network-related. Rather, it was related to an issue with application servers that had become unresponsive.
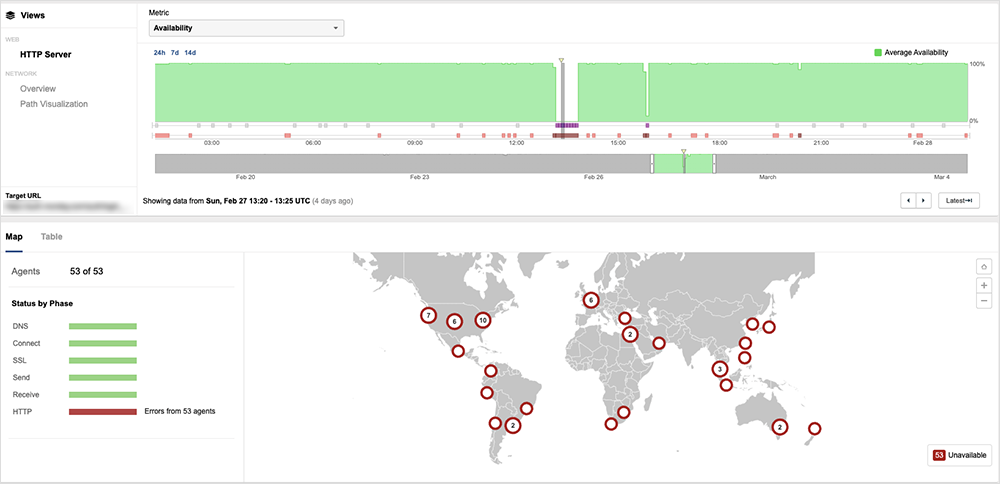
On March 2, Microsoft 365 reported that users were experiencing issues with SharePoint Online and OneDrive for Business, and that the issue was remediated through network configuration changes. Microsoft also addressed an issue users were having accessing the Microsoft 365 admin center, which they mitigated by redirecting traffic to healthy infrastructure.
The final outage occurred on March 1 and cut off entirely Australia’s island state of Tasmania from fixed-line and cellular data services for about 30 minutes, with service degradation and congestion continuing for hours, even after service was restored. Tasmania is served by subsea cables from the Australian mainland, and while these remained functional, simultaneous cuts on both ends of the terrestrial portions of the transmission network meant that subsea traffic dropped to almost zero for about half an hour.

The lost connectivity had a broad blast radius, from ATMs to airline check-ins, from TV broadcasting to access to government services.
So, what to do in these circumstances, other than just sit it out?
One might try to insulate from the impact of an outage by paying for diversity or backup capabilities from another provider.
However, this is always a question of cost-benefit. An outage’s rarity and productivity impact may not be worth the outlay for a backup service that otherwise sits underutilized. In saying that, if the front-facing service is more mission-critical, such as e-payments, route diversity to keep transactions “always on” is likely to trump any additional costs.
It’s also often the case that the outage duration may not warrant the recourse options being invoked. Switching telecommunications services or productivity platforms isn’t going to be easy or feasible in the time that a primary service is down. Outages are a fact of life in an Internet-powered world, and to a certain extent, we have to learn to live with them.
It doesn’t mean that no long-term harm is done to the reputation of that company, however. An outage still may lead to a change of buying behavior down the road, particularly if problems are perceived by end users to have been left unaddressed despite a notable outage event and potentially allowed to reoccur.
Companies that experience crippling outages, however unusual, may need to go on the offensive with their user base to show that they took notice and have taken steps, however large or small, to prevent a recurrence.
The same goes for service status pronouncements during outages. We’ve talked at length in this column about the relative usefulness of outage status advisories, and we continue to see a broad spectrum of approaches.
For particularly public incidents, we also see an upward trend in vague or overly technical explanations, where a simpler and more effective approach would be a plain English explanation. “The application is down. You may not be able to use services x, y and z for 15 minutes” might buy more goodwill than a status update that is late or uses language that is hard to understand.








