


Automation is often positioned as a game-changer; an architectural future-state capable of reducing human error, saving costs and mitigating an untold number of potential outage scenarios.
As more companies go down the chaos engineering path, the tendency is to dream up as many scenarios as possible to break their infrastructure and test its resilience to unknown operating conditions. For this, they inevitably employ a high degree of automation for testing and results collection, also allowing continuous testing and improvement within the CI/CD chain.
Which is all fine if the automated responses work as expected all of the time. However, challenges arise when automated responses to detected operating variances kick in and worsen the situation.
Case studies on this are still relatively scarce, likely because the number of organizations with sophisticated automated operations (AIOps) setups is still low. One might anticipate the number of instances of “automated ops gone bad” increasing as more organizations gain maturity with the model.
We saw an instance of this occur at the end of last year, when an automated mechanism at AWS that was intended to detect and address capacity issues “triggered an unexpected behavior” that led to network congestion and cascading impacts on a number of cloud services—as well as to a number of popular web-based applications.
Then there was the Coinbase outage, where plummeting cryptocurrency prices triggered a flood of automated ‘sell’ positions, exceeding the number of transactions that could be processed at one time, leading to a backlog.
Microsoft Outage
The reason we’re talking about this now is that another instance of “automated ops gone bad” occurred on September 7. Microsoft experienced an issue that affected connections and services leveraging Azure Front Door (AFD), an Application Delivery Network (ADN) as-a-service that provides global load-balancing capabilities for Azure-based services.
As Microsoft explains, “The AFD platform automatically balances traffic across our global network of edge sites. When there is a failure in any of our edge sites or an edge site becomes overloaded, traffic is moved to other healthy edge sites in other regions. This way, customers and end users don’t experience any issues in case of regional impacts.”
In this case, however, the problems kicked in when the AFD service tried to balance out “an unusual spike in traffic,” only to wind up causing “multiple environments managing this traffic to go offline.”
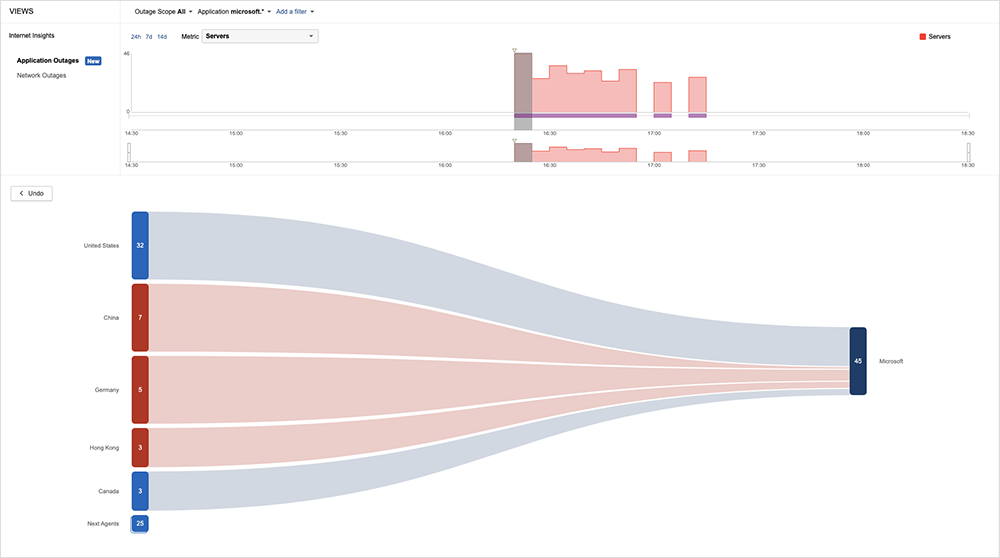
Similar to last year’s AWS incident, cascading failures ensued. As Microsoft notes: “We have auto-mitigations which will cause our environments to recover in such an event. By design, these environments will recover and once they are in a healthy state so they can start to resume managing traffic. During this instance, as users and our systems retried the requests, it exacerbated the situation where we had a build-up of requests and this build-up did not allow time for the environment to fully recover.”
Microsoft solved the problem by manually intervening in the AFD load balancing process, “expediting the auto-recovery system and performing more efficient load distributions in regions where there was a large build-up of traffic.” Only then did the bottlenecks ease, allowing the automated systems to be reinstated.
The incident again highlights the risks of heavily-automated operations and the need for a manual override mechanism—a fallback if the automation doesn’t function as expected. Full “lights out” automated operations may be a dream for some teams and organizations, but checks and balances are needed, as is full visibility that can help identify when an automated process is creating conditions it cannot fix without human intervention and assistance.
Zoom Outage
Also, on September 15, Zoom experienced a global outage that manifested as bad gateway (502) errors for users globally. ThousandEyes observed a range of impacts, with users unable to log in or join meetings. In some cases, users already in meetings were kicked out of them.
The root cause hasn’t been confirmed, but it appeared to be in Zoom’s backend systems, around their ability to resolve, route, or redistribute traffic.
Initially, there was some confusion as to whether or not the problem lay with AWS, which since the pandemic, acts as burst capacity for Zoom. It quickly became apparent this wasn’t the case, as Zoom users globally experienced problems, regardless of where their infrastructure was hosted. As Zoom isn’t entirely in AWS—it still hosts mostly in its own data centers—the logical explanation is that, with locations impacted globally, the cause of the outage was an issue with the Zoom application itself.
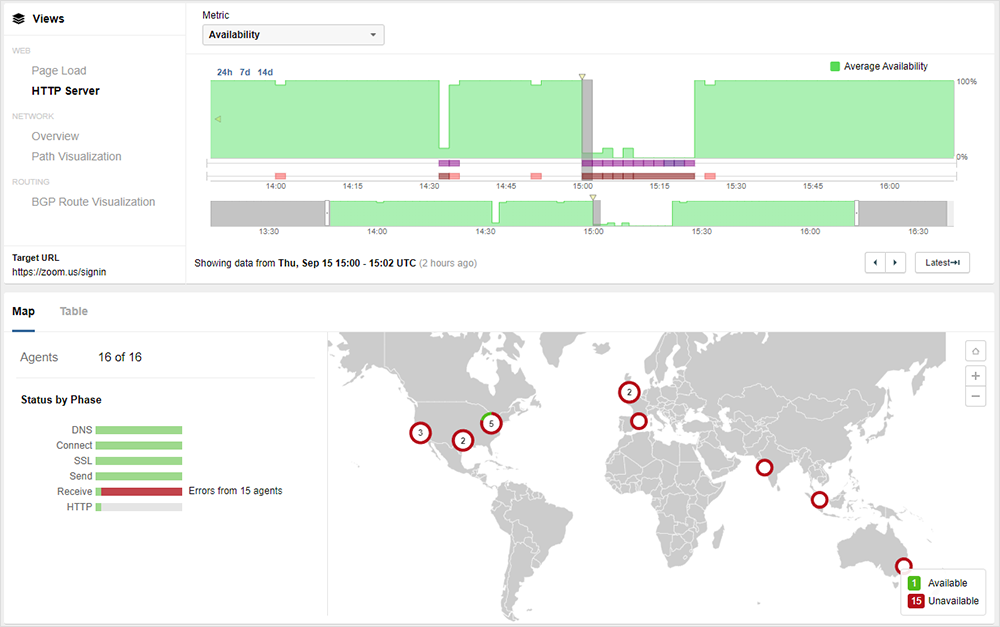
Enterprise users of Zoom that had independent visibility over their environments could also quickly identify that the issue lay with Zoom, and escalate accordingly.
Internet Outages and Trends
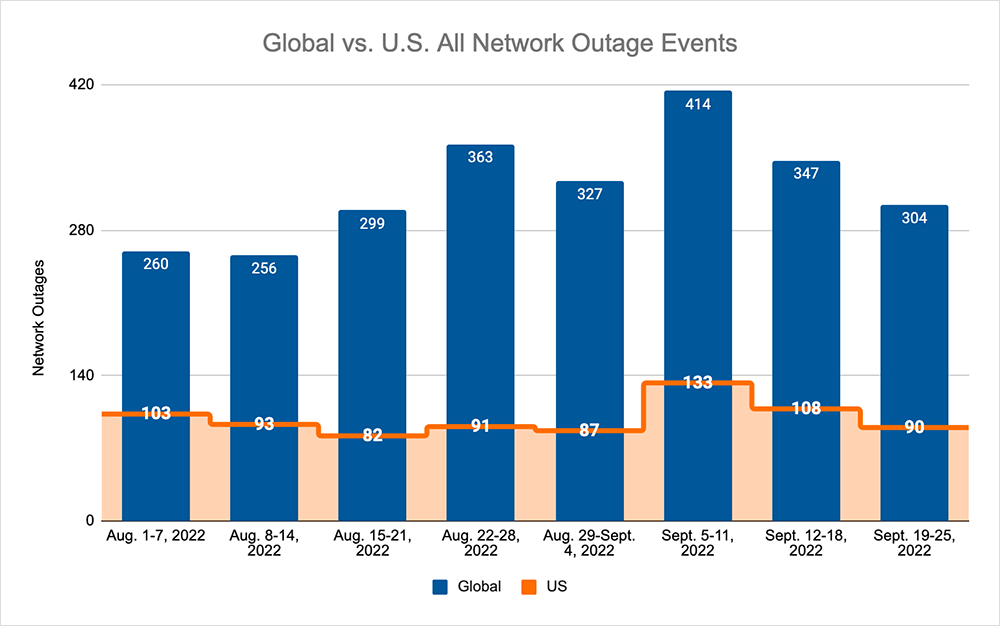
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks, over the previous two weeks, we saw:
- Global outages initially dropped from 414 to 347, a 16% decrease compared to September 5-11, before continuing the downward trend the following week, where we observed a drop from 347 to 304, a 12% decrease when compared to the previous week.
- This pattern, and downward trend, was reflected domestically, with an initial drop from 133 to 108, a 19% decrease compared to September 5-11, before dropping again from 108 to 90, a 17% decrease from the previous week.
- US-centric outages accounted for 30% of all observed outages, which is the same percentage observed on August 29-September 4 and September 5-11, where they also accounted for 30% of observed outages.
Other Incidents of Note
Two other noteworthy incidents also occurred in the period.
First, on September 5, Twitter lost one of its key data centers in heatwave conditions. While this did not cause an outage, it reportedly left Twitter in a “non-redundant” state. That is, if anything happened to its remaining facilities, it would be unable to serve all its users. It appears Twitter was able to gracefully shut down infrastructure at the site, and route around the shutdown. However, the incident is likely to provide “food for thought” on whether or not cost-effective options exist to increase redundancy. Endless redundant options are possible but may be neither cost-effective nor realistic. These are always difficult conversations to have.
AWS also experienced an authentication issue that led to 59 cloud services becoming inaccessible for several hours in South Africa.









