
9月6日(金)午前10時40分(太平洋標準時)、ThousandEyesは、世界中のウィキペディアサイトへのユーザーアクセスに9時間にわたる大きな障害を検出しました。 ウィキペディア・ドイツのツイッターアカウントでは、「サイトが大規模かつ非常に広範なDDoS攻撃によって麻痺している(翻訳)」との報告がありました。
ThousandEyesは、世界中の29の都市と20か国にあるクラウドエージェントの監視ポイントからウィキペディアのメインページを監視していたため、ユーザー、ネットワーク、およびインターネットルーティングの観点から見た攻撃の開始とその進行状況をキャプチャできました。以下は、イベントの分析です。こちらのシェアリンクを参照してください。
可用性の損失
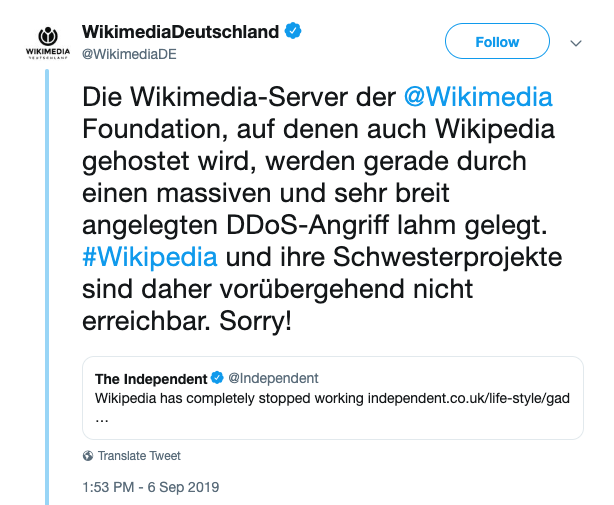
午前10時40分、世界中に配置されたHTTPサーバーで可用性の大幅な低下を検出し、主にヨーロッパ、中東、アフリカの11カ所のエージェントからのサイトへのアクセスが失われました。その後の攻撃の間も、被害の影響はEMEA地域に残りました。図1の左下隅の「フェーズごとのステータス」の凡例では、ほとんどの問題がHTTPサーバーの「接続」フェーズにあったことを示しています。つまり、ユーザーのコンピューターはTCPの3ウェイハンドシェイクを確立できず、Wikipediaサーバーとの継続的な通信のためのインターネット接続ができませんでした。
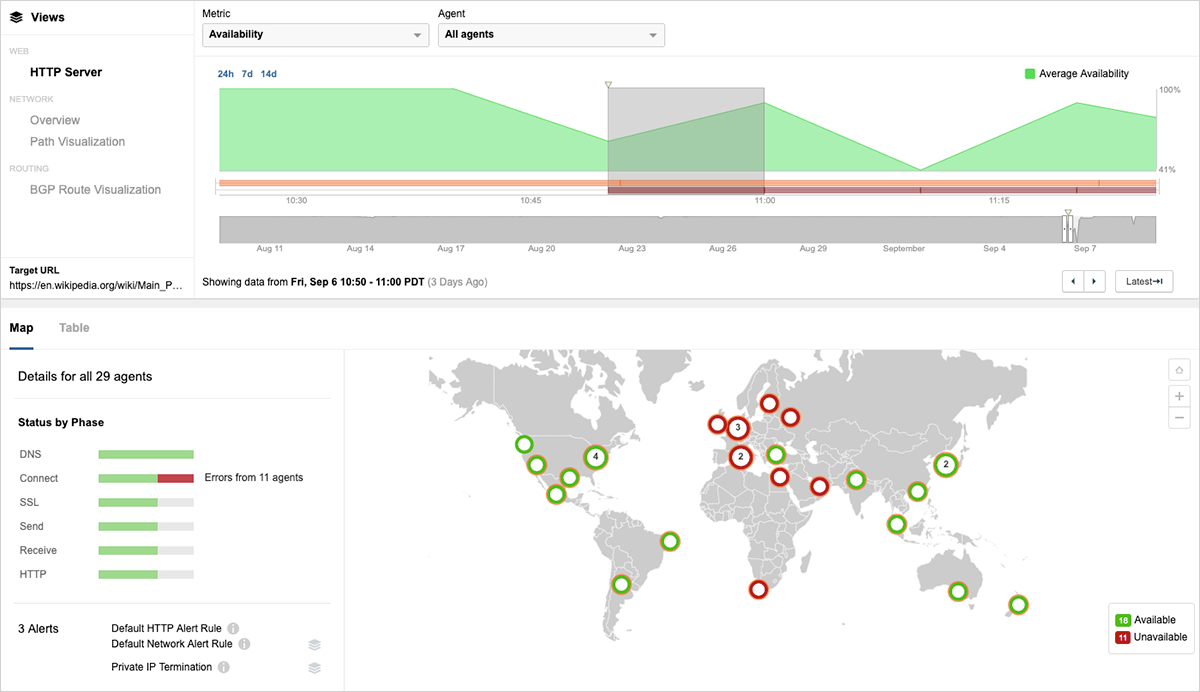
攻撃の過程で、図2に示すように、米国、メキシコ、アルゼンチン、ブラジルからのアクセスも断続的に影響を受けました。
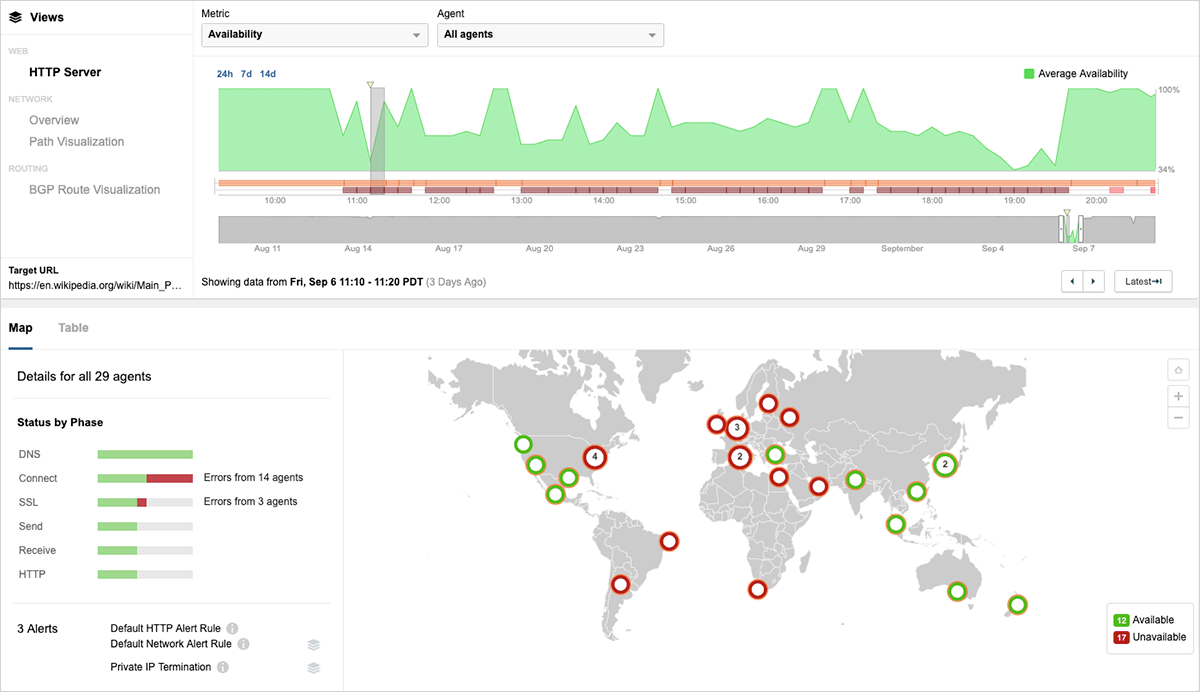
最悪の状況下では、図3に示すように、インド、韓国、香港、マレーシア、オーストラリアからのアクセスでも影響を受けました。
応答時間の増加
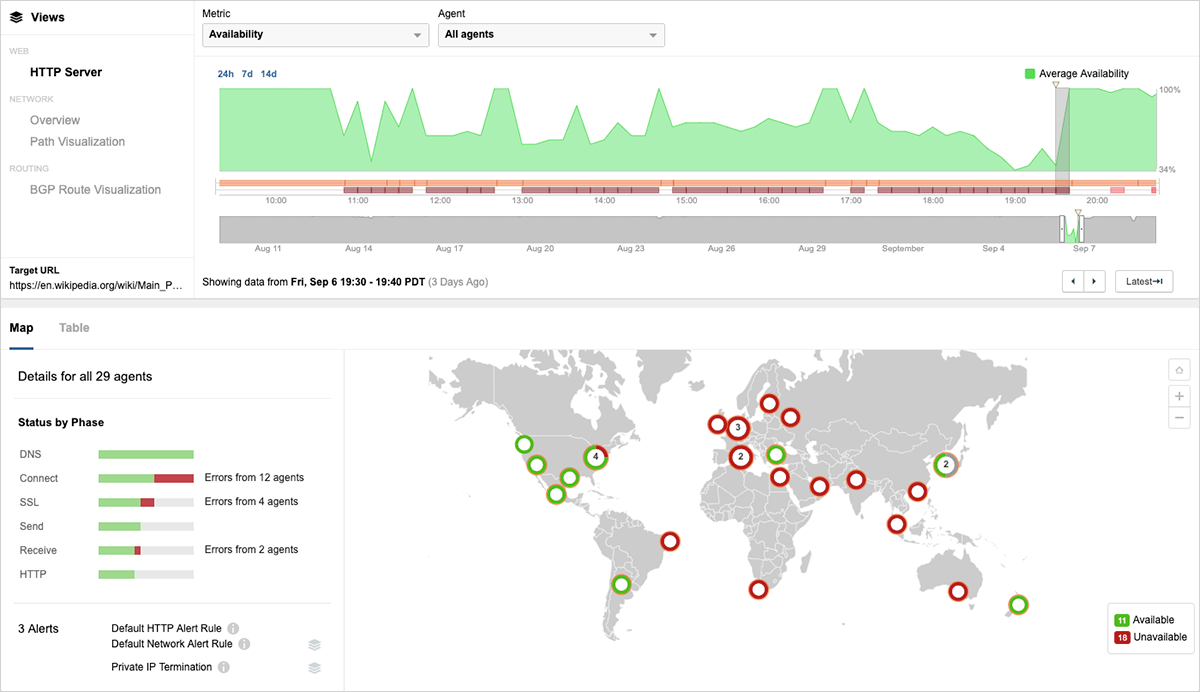
可用性の損失は深刻でしたが、ユーザーへの影響はそれだけではありませんでした。ウィキペディアのサーバーに接続できたユーザーも、HTTP応答時間(ユーザーブラウザーに配信される最初のバイトまでの時間)が劇的に増加しました。 図4は、攻撃がおよそ午前10時(PDT)に開始される前に、ウィキペディアの平均HTTP応答時間が353ミリ秒であったことを示しています。香港の監視エージェントの応答時間は146ミリ秒でした。 図4の左下にある応答時間の円グラフは、通常動作時には、接続 (Connect) 時間が応答時間全体で最小のフェーズであることを示しています。Connectの世界平均が62ミリ秒、DNSで88ミリ秒、SSLネゴシエーションで128ミリ秒、サーバーレスポンス待ちで63ミリ秒です。 図4の上部にある時系列グラフを読むと、9時間の障害発生時に複数の監視ポイントで平均応答時間が急上昇していることがわかります。
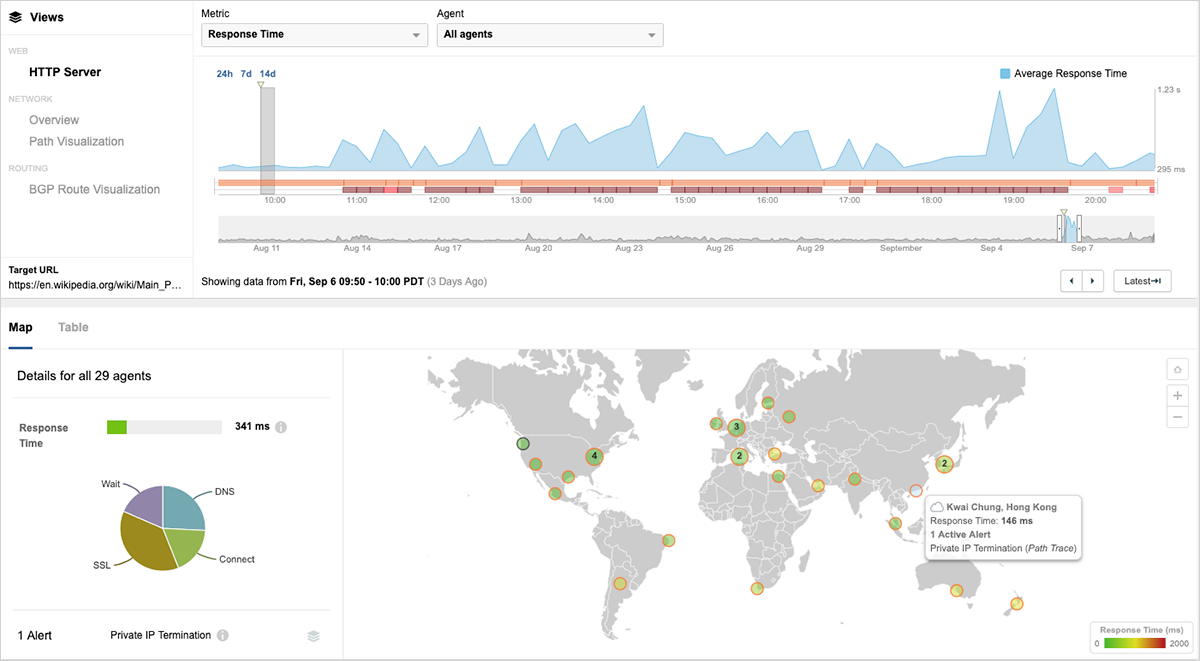
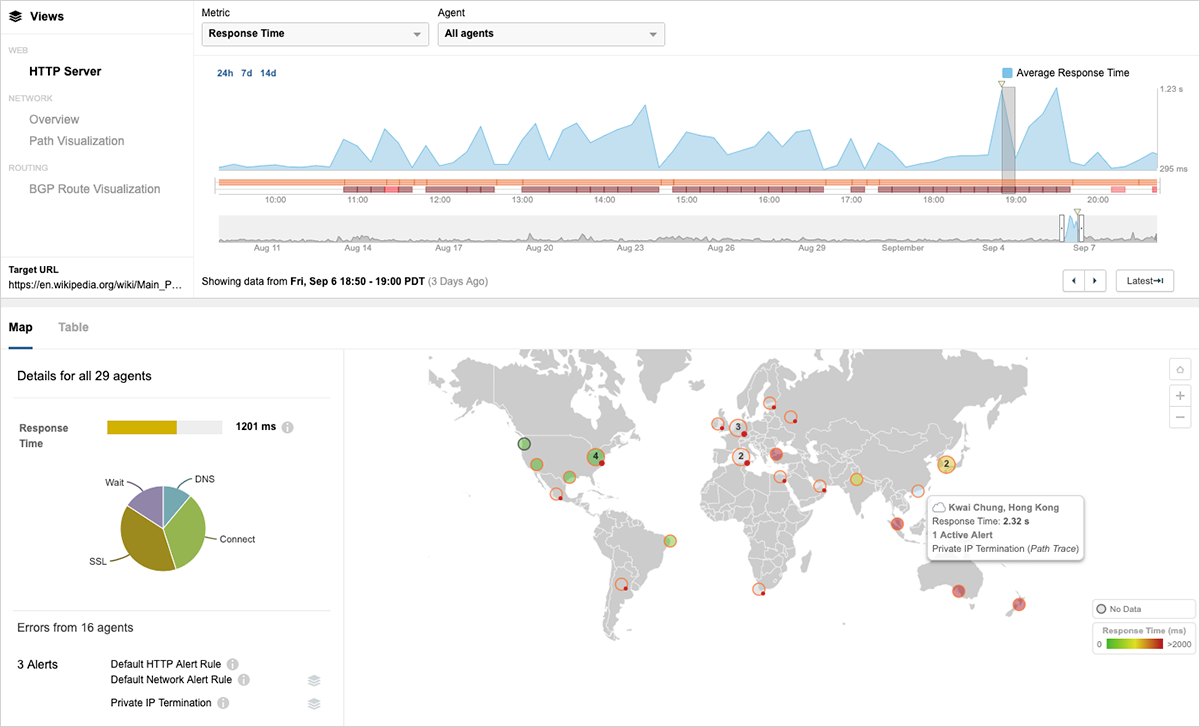
応答時間が急上昇した時点へ時間軸をスライドすると、図5に示すように、まったく異なる状況が見られます。この時点(午後6時50分)で、平均応答時間は1.201秒に増加しており、これは通常時の3.5倍に当たります。詳細を調べると、香港からの応答時間が2.32秒に急増し、通常の16倍近くになっていました。 もちろん、ウィキペディアへのアクセスには、オンラインゲームをプレイしているときほど応答時間の増加が影響を与えることはありませんが、それでもページ表示を待つ利用ユーザーはイライラしていることでしょう。
ネットワークレイヤでのDDoS攻撃の確認
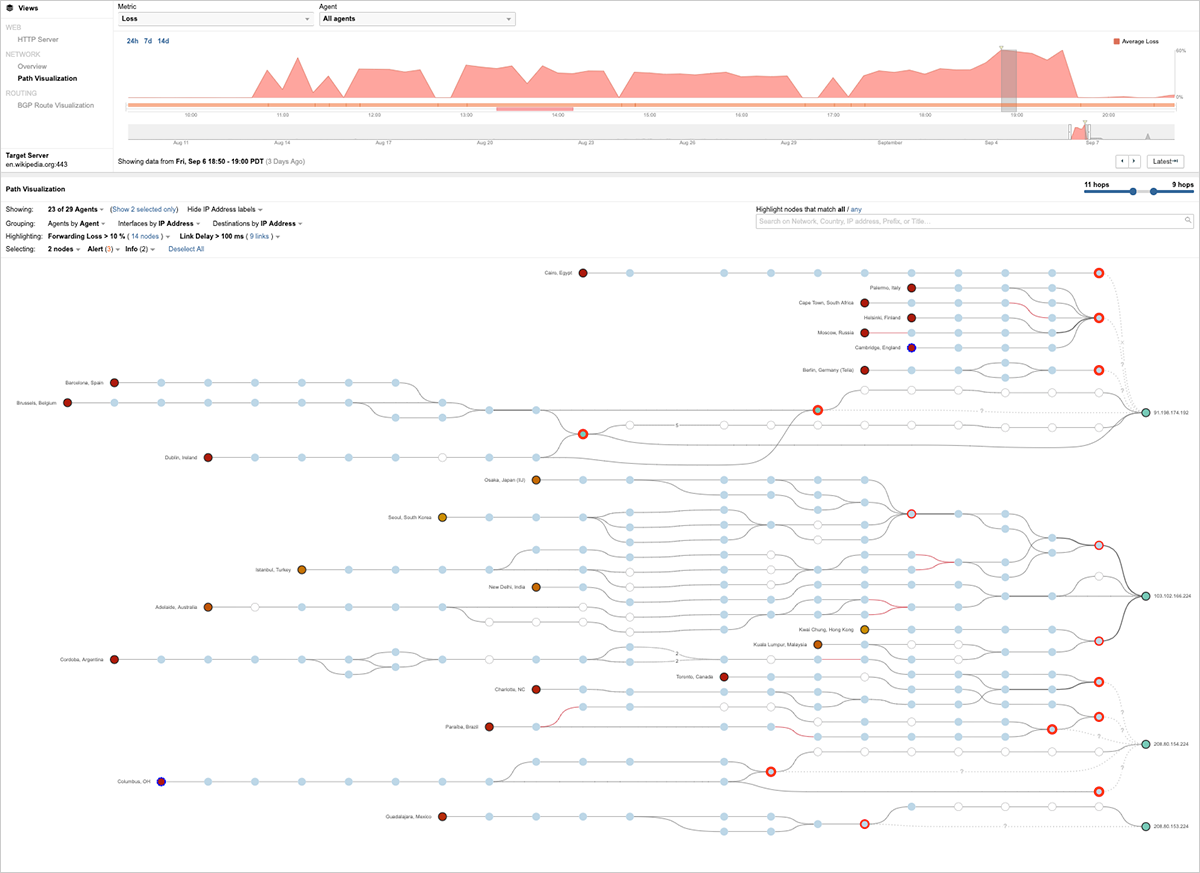
これまで、HTTPサーバーレイヤーの可用性とパフォーマンスについて見てきましたが、ThousandEyesの監視エージェントはネットワークレイヤーの監視も実行し、DDoS攻撃の影響が実際に見られる場所になります。下段の図6は、イベント発生時のパケットロスのグラフ(すべての監視エージェント平均で最大60%のパケットロスを確認)を含むパスの可視化ビューを示しています。またその下のネットワークビューでは、左端の監視エージェントから複数のネットーワークノードを経て右端の緑色のノードで示されたウィキペディアの各国サイトへのパスが可視化されています。91.198.1764.192はウィキペディアオランダのサイト、103.102.166.224はウィキペディアシンガポール、そして208.80.154.224は米国バージニア州のウィキペディアです。
左側のエージェントと右側の監視ターゲットとの間のパスにあるノードは個々のルーターホップであり、多くのノードが赤で囲まれているのがわかります。赤い円の太さは、17% から100%のパケットロスの量を示しています。これらのルーターの一部はウィキメディアによって運用されていますが、多くはNTTやTeliaなどのアップストリームISPによって運用されています。サイトがDDoS攻撃を受けている場合には、このように複数のルーターノードにて大量のパケットロスが検知されます。これは、悪意のある偽トラフィックの洪水がルータというパイプを詰まらせ、Wikipediaサーバーに到達しようとする正当なユーザーのパケットの「サービスが拒否」されるからです。 その結果、HTTPレイヤでも可用性の損失や応答時間の増加が見られます。
BGPから見た復旧への道
DDoS攻撃は珍しいことではありません。 実際、シスコ社の調査では、2020年までに年間1,700万回のDDoS攻撃が発生すると予測されており、ウィキメディアは、図7のブログで共有しているように、複雑化する脅威環境への対応を継続的に行い最適化していくと宣言しています。

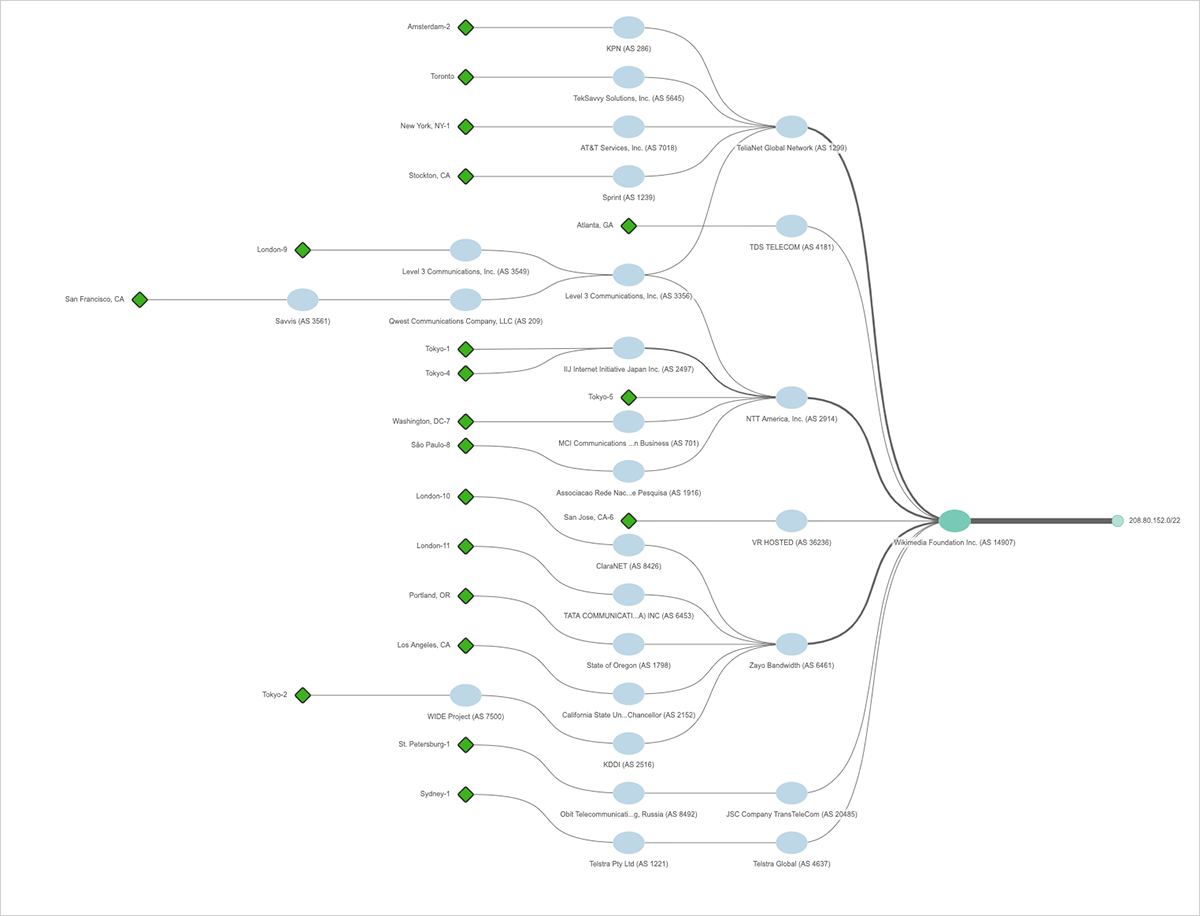
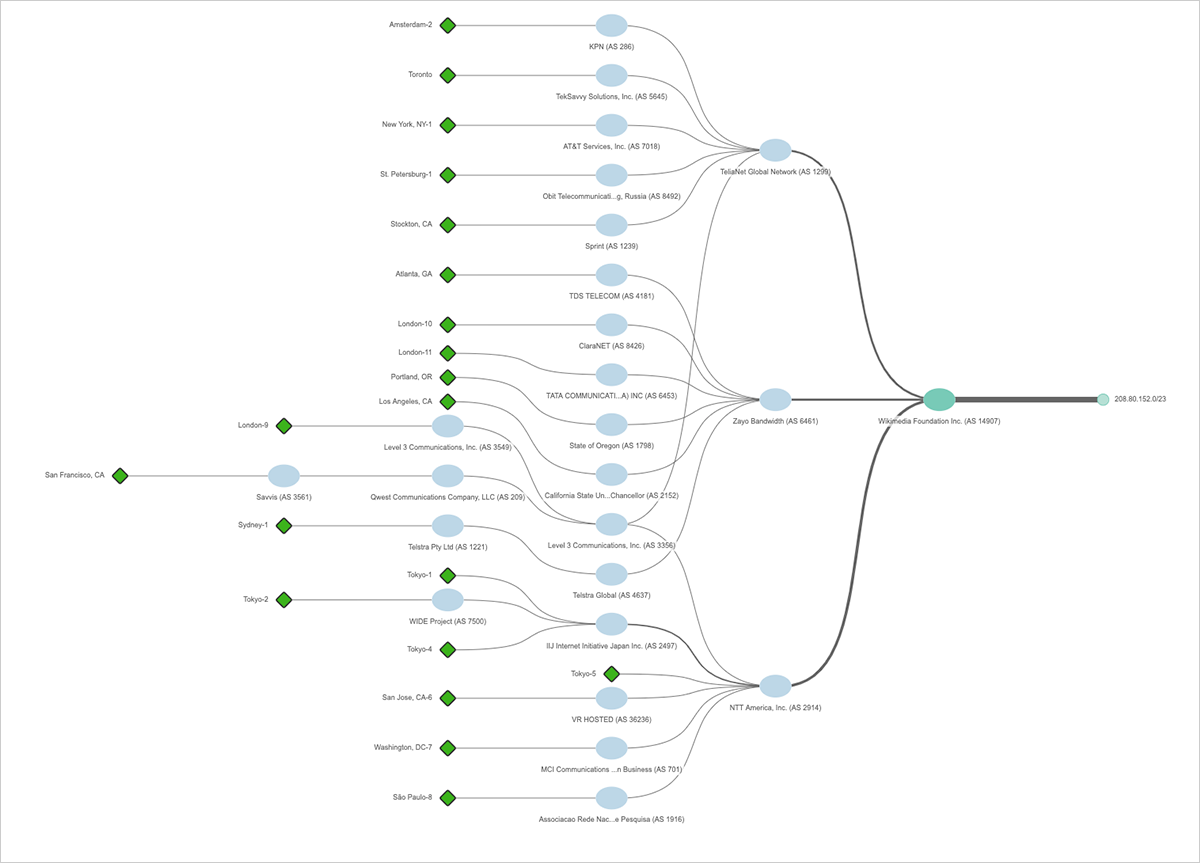
攻撃を受けてまもなく、ウィキメディアはバージニア州のサイトと他のインターネット接続間にCloudflareを挿入し始めました。 BGPルーティングレイヤービューをさらに掘り下げていくことで、このアクションをキャッチすることができました。 図8では、1024の個別のIPアドレスを含む大きなネットワークアドレス(またはプレフィックス)208.80.152.0/22を使用して、米国のウィキメディアサイトがインターネットにアドバタイズされたことがわかります。 ウィキメディアのインターネット・ネットワーク(自律システム)AS 14907は、Telia、NTT America、Zayo、Telstraなどの7つのアップストリームISPとピアリングされており、208.80.152.0 / 22はこれらのネットワークを通過するASパス経由で到達可能です。
およそ午後8時30分(PDT)に、BGPの監視エージェントは、より細かい2つの新しいサブネットワークルートが208.80.152.0/22より優先されるようにアドバタイズされたことを検出しました。プレフィックス1つは208.80.152.0/23であり、図9に示すようにウィキメディアによってアドバタイズされました。このプレフィックスは、アップストリームISPとしてTelia、Zayo、NTT Americaを介してインターネットから到達可能です。 もう一つのプレフィックス208.80.153.0/23は、図10に示すようにCloudflareによってアドバタイズされました。各/ 23は512個の個別のIPアドレスを表し、Wikimediaは実質的に大きなプレフィックスを分割し、半分をCloudflare経由、もう半分をそのままインターネット経由での接続としました。
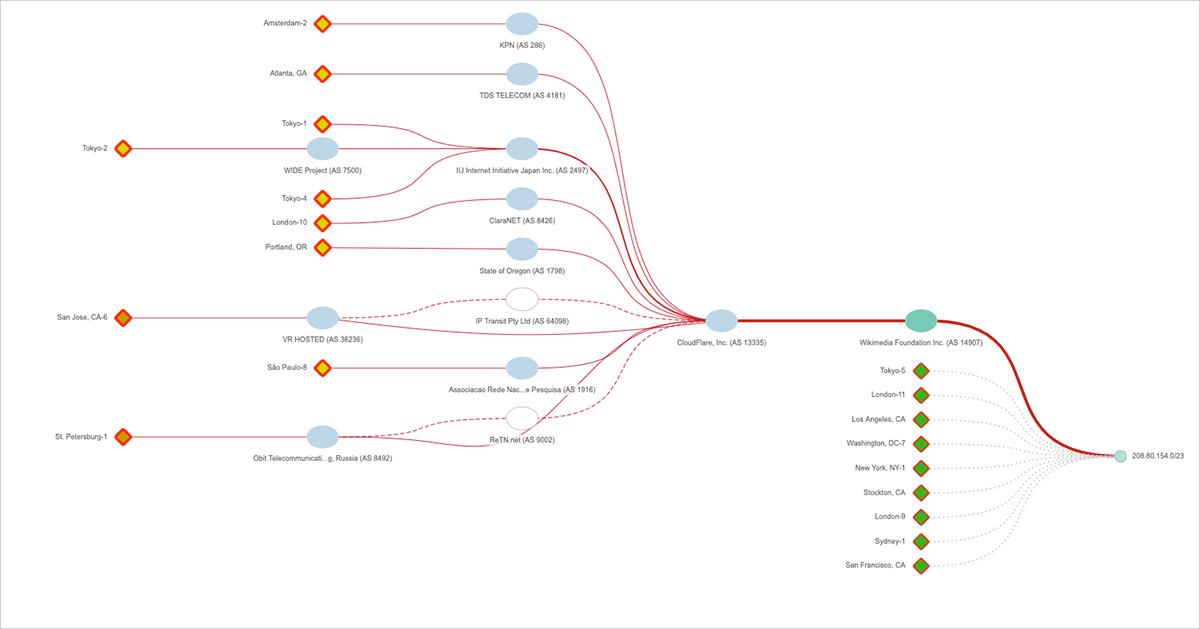
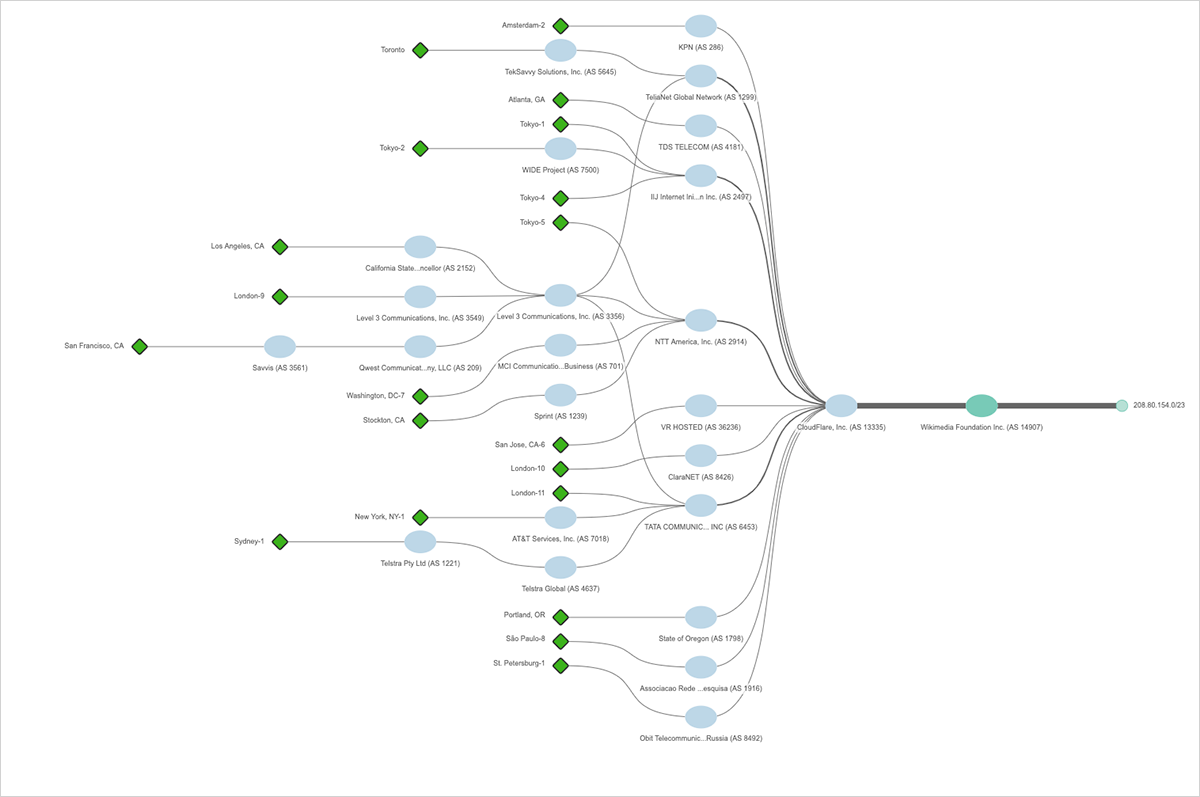
上記の図10では、複数の赤線によりルート変更があったことがわかります。赤い点線はルーティングパスが消された場所を示し、赤い実線は新しいルーティングパスが確立された場所を示します。少々複雑なビューですが、すべての新しいパスがCloudflareを通過し、ウィキメディアのネットワークとその他のインターネット接続の間にCloudflareの大規模ネットワークが挿入されたことを示します。 Cloudflareは、他のサービスに加えCDNおよびDDoS緩和サービスを提供しており、大規模攻撃に対する保護強化を進めています。ウィキメディアのアドレス空間の一部のみが切り取られたという事実は、この動きがおそらく少し実験的な方法で実行された可能性があることを意味し、おそらくA / Bテスト(どちらが良い成果を調べるテスト)の一種だったと考えられます。それでも、図11に示すように、午後10時PDTまでに、208.80.154.0 / 23はCloudflareによって完全にフロントエンドとなりました。
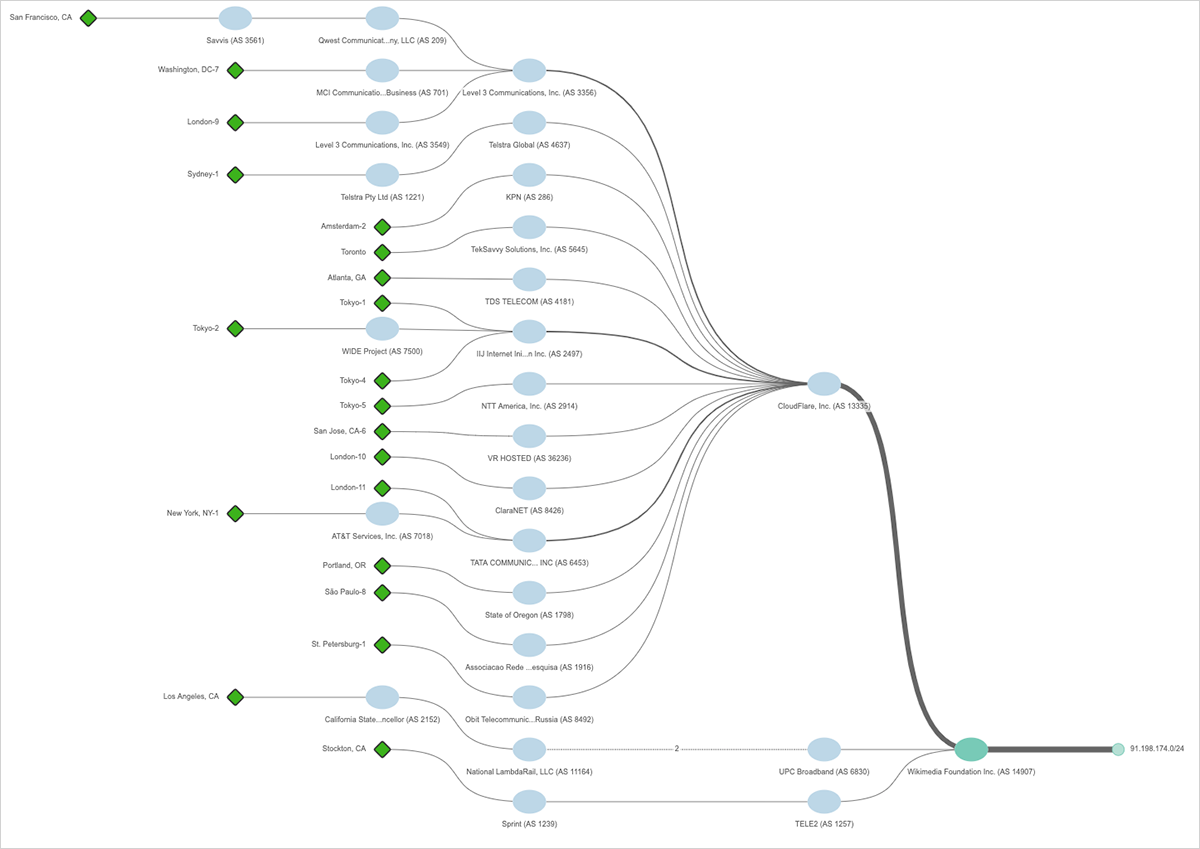
さらにウィキメディアは、オランダのプレフィックス(91.198.174.0 / 24)のASパスを午後9時45分からCloudflare経由で到達できるようにするプロセスを開始し、その後の2日間でパスを段階的にシフトし、図12に示すパスの図のように、ほとんどのパスがCloudflareのネットワークを通過するようになりました。
運用チームはどう対処すべきか?
前述したように、DDoS攻撃を受けることはデジタルビジネスを行う上で悲劇です。世界最大のメディアサイトの1つであるウィキペディアが影響を受けたように、あなたのビジネスも影響を受ける可能性があります。もし非営利のウィキメディアとは異なり、収益目的としてデジタルビジネスが展開されている場合、予防的な対策を講じることは非常に需要です。
ただし、ここでの教訓は、DDoSの準備だけではありません。混乱が何であれ、顧客、パートナー、およびユーザー間で共有されるデジタル目標に妥協は許されません。 DDoS対策を実施している場合でも、ユーザーエクスペリエンスがどのように提供されているかを知ることはミッションクリティカルであり、ビジネスに関わるあらゆる観点から確認する必要があります。 ThousandEyesは、複数の監視エージェントとマルチレイヤ監視機能により、Webシナリオベースのトランザクション、HTTPサーバーの可用性とパフォーマンス、ネットワークパス、インターネットルーティング、さらにはインターネット障害の自動検知機能を提供します。これにより夜間にインターネット上で起こりうるあらゆる予測不可能な事象にさえも対応することが可能になるのです。
最後に、今回学ぶべきことは、これらの事象がビジネスに直結するウェブやその他のデジタル資産だけに留まらないということです。 Gartnerの調査によると、大企業は現在、ビジネスに不可欠な多数の重要なクラウドおよびSaaSを利用しています。SalesforceのようなSaaSを例に取ると、シュナイダーエレクトリックのようなメーカーでは、45,000人の従業員に加え数十万人の顧客やパートナーもそのプラットフォームを介してビジネスをしています。通常時のアプリケーションのユーザー体験値を知ることで、それが有用なベースライン(基準値)となり、問題が発生しているときだけでなく、自社ネットワークまたはインターネット(あるいはどこのネットワークまたはクラウドドメインか?)のどこで問題が発生しているのかを把握できます。さらに、問題の種類(DNS、Connect、SSL、あるいは待機時間-図1を参照)をよりよく理解できすることができます。そしてこれらの情報が無い場合、問題を解決したり、従業員や顧客とコミュニケーションをとったり、適切な内部チームや外部プロバイダーにエスカレーションすることもできません。つまり、このような自社インフラの内部や外部からのマルチレイヤの可視性がなければ、事象の手がかりさえつかむことができず、クラウドベースやクラウドファーストのITモデルを推進することはできないのです。


