重要なアプリケーションやサービスのクラウド移行により、実質的なインフラ構築と運用の負荷を軽減することができます。しかし一方、クラウドは、インターネットとの接続性が非常に複雑であるため、予測が困難な事象が頻繁に発生しています。不運にもその事象により自社のサービスに影響が及んでしまった場合には、その現実を思いしらされます。
2019年6月2日の午後12時頃(米国西海岸標準時)、ThousandEyesはGoogleのネットワーク障害を検知、Google Cloud Platformの米国の一部の地域でホストしている社内サービスに影響が生じました。最終的にサービス停止は4時間以上続き、YouTube、G Suite、Google Compute Engineなどのさまざまなサービスへのアクセスにも影響を及ぼしました。以下は、ThousandEyesから見えた世界と、クラウドに移行する際のレジリエンスと可視性についてどのように考えるべきかをまとめたものです。
障害発生初期
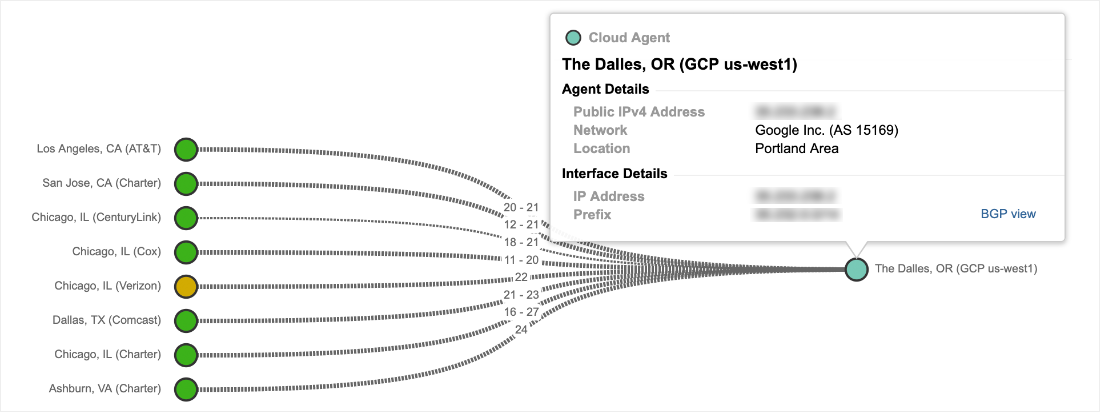
ThousandEyesは、6月2日午後12:00過ぎに発生したGCPでの障害時に、ユーザー側で受けた影響とマクロ的なネットワーク側への影響の両方を検知しました。それとほぼ同時に、ソーシャルメディアとDowndetectorでも、ユーザーからの最初の投稿が開始されていました。図1は、CDNのエッジネットワークを介して配信されているコンテンツ(GCP us-east4-cのGCEインスタンス上にホスト)へのアクセスを監視していた図ですが、ThousandEyesが170都市に配置した249のグローバル監視エージェント(クラウドエージェント)から見た障害状況を示しています。
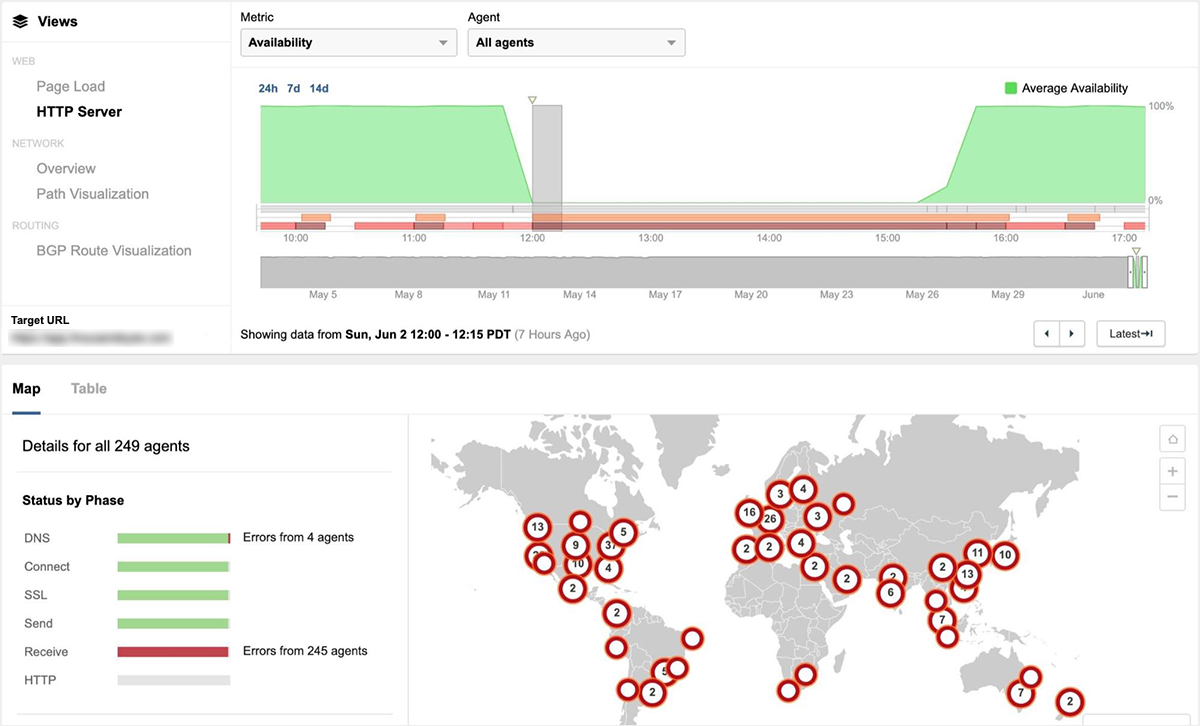
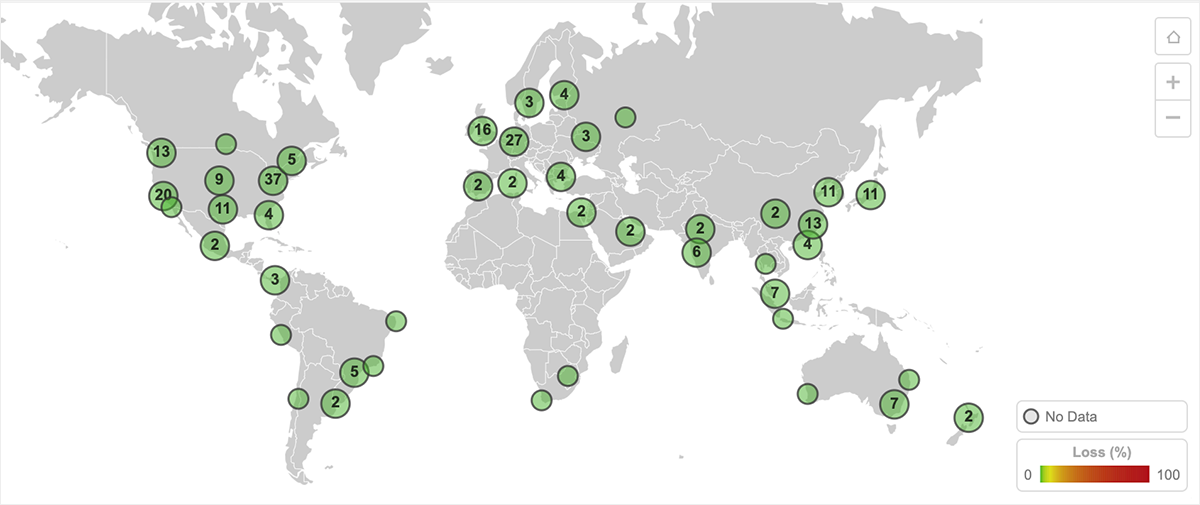
図2は、世界各国からGCP us-west2-aにホストされているサイトにアクセスした際のパケットロス(100%)を示しています。
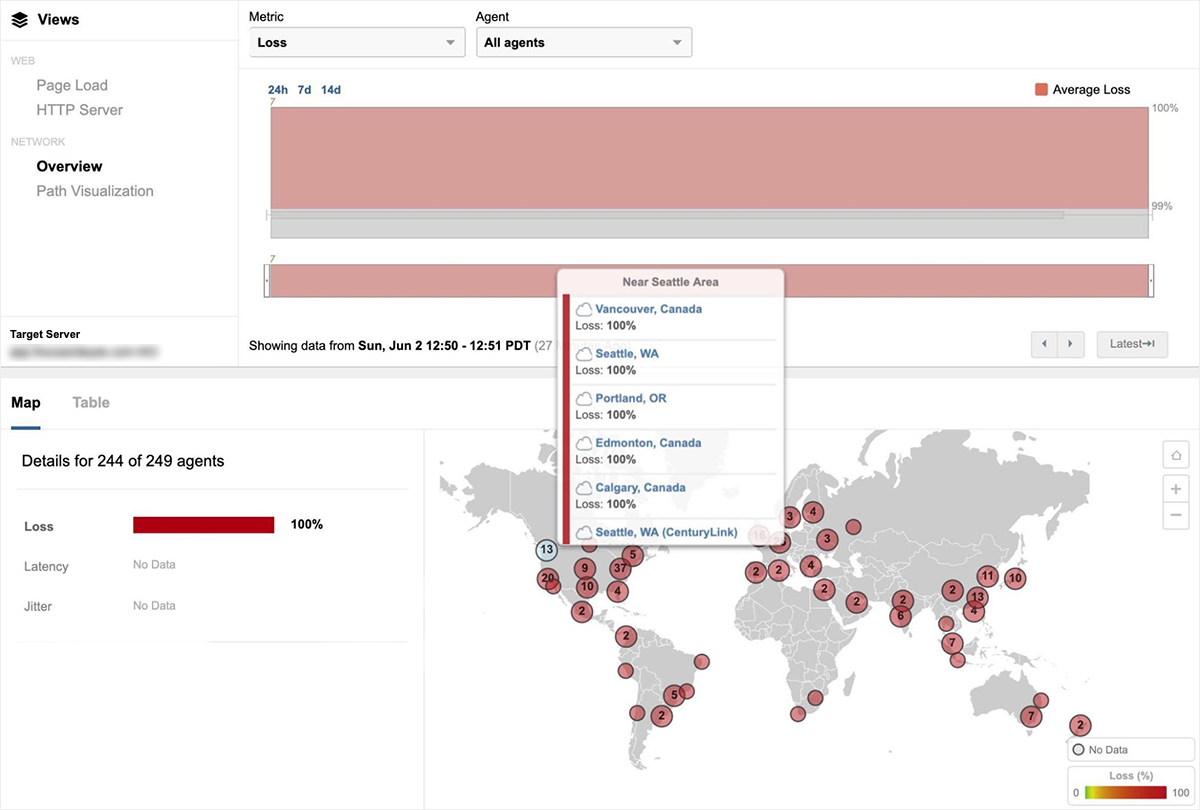
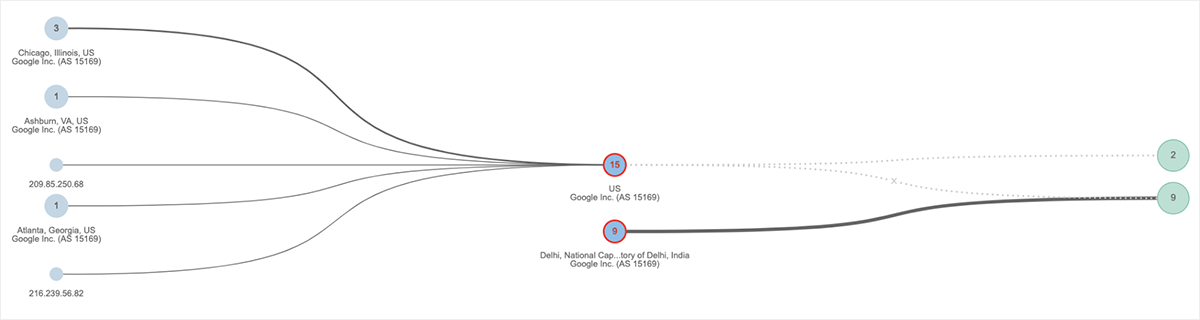
さらにマクロレベルでも、Ashburn、Atlanta、Chicagoなど、米国東部のネットワークの問題を確認することができました。 例として、図3にGoogleネットワークのトポロジマップを示します。 左側の水色のノードは、Googleにホストされている一番右側の2つのドメインにアクセスする送信元インターフェイスの数を示しています。 これらの2拠点間にある15のインターフェース上で、ソースインターフェースからサービスドメインへの到達を妨げる深刻なパケットロスが発生しています。 興味深い補足として、図3のトポロジマップの下段では、インドのGoogleネットワークでもネットワーク接続の問題が発生していることがわかります。
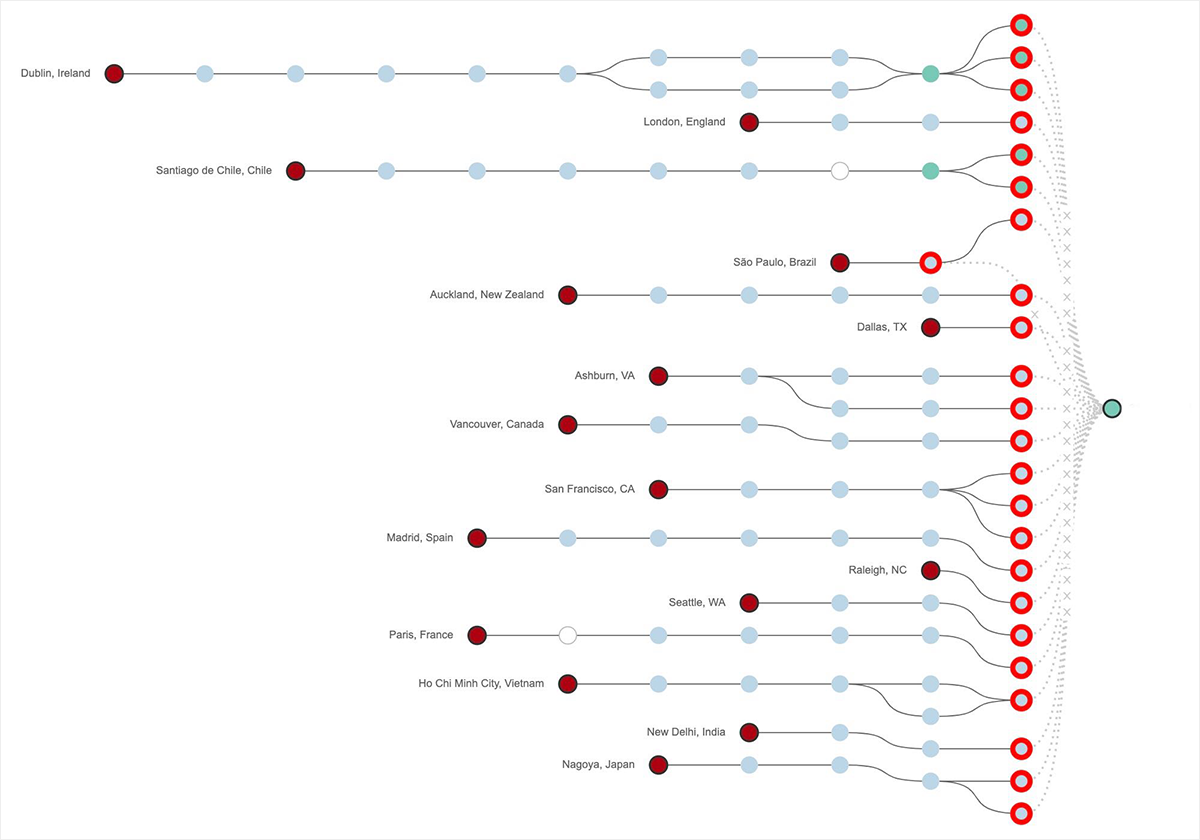
下の図4に示すように、パスの可視化により右側のGoogleのネットワークエッジでトラフィックが落ちていることがわかりました。 実際、4時間以上のサービス停止のうち3.5時間の間、GCP us-west2-aにホストされているサービスへのアクセス上で100%のパケットロスが検知されました。 また、us-east4-cを含むGCP US 東部のその他のリージョンにホストされているサイトでも同様のロスが見られました。
ただし、本障害の影響を受けた全てのリージョンでの現象が一様なわけではありません。 たとえば、下の図5は、GCP us-west1にホストされている別のサービスが、この障害の間も問題なく利用可能であることを示しています。
さらに、米国だけでなくヨーロッパや他の地域でも、ほとんどのGCPリージョンで障害の影響を受けませんでした。 たとえば、図6は、オランダにあるeurope-west4リージョンが、障害発生中も到達可能なままであったことを示しています。 緑色のステータスは、ThousandEyesのグローバル監視エージェントがそのリージョンへのアクセス中にパケットロスを検知していないことを示しています。
Googleによる分析
Googleは早い段階でこの問題を認識しており、図6に示すように、午後12時25分にGoogle Compute Engineでの問題発生を発表しました。その後、午後12時59分にサービスの影響がより広範なネットワークの問題に関連していると更新しました。 午後1時36分までに、Googleはこの問題を米国東部で発生した重度のネットワーク輻輳に関連していると発表しました。この発表は初期の段階で見られたパケットロス増加の現象と一致しています(図2参照)。

サービス復旧
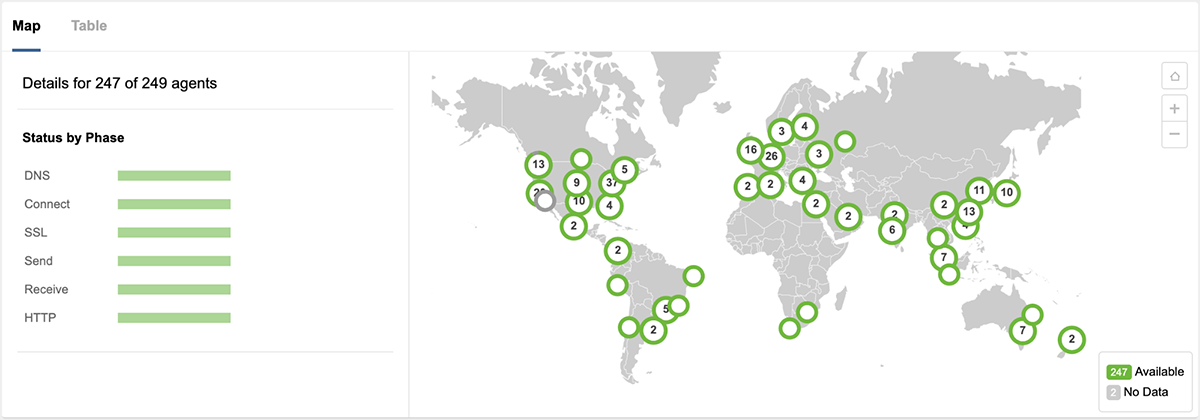
午後3時30分ごろから、図8に示すように、GCP us-west2-a上のサービスへのアクセスにおいて、パケットロスの緩和とサービスへの到達性の改善が見られ、さらに次の1時間にわたって復旧に向かいました。
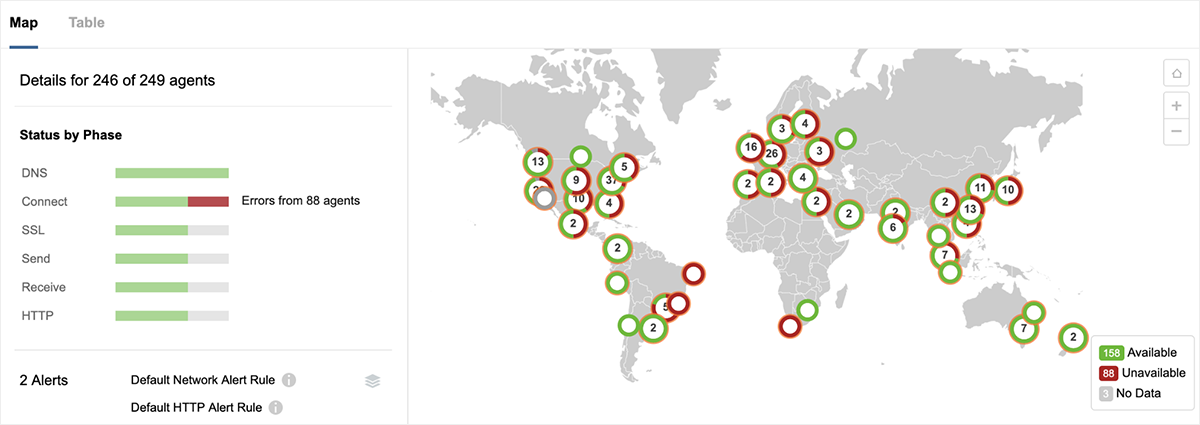
図9に示すように、サービスは午後4時45分までには完全に復旧したようです。
午後5時9分、Googleは、図10に示すように、影響を受けたすべてのユーザーについて、午後4時の時点でネットワークの輻輳問題が解決されたと発表しました。そしてこの問題のさらなる内部調査も約束しました。

クラウドユーザーが取るべきアクション
今回の事象のように、クラウド障害が及ぼす影響はアクセス先やホスト先によって様々です。クラウド障害事例から学ぶサービス継続のための最も重要な対策の1つは、将来の再発回避のために、クラウドアーキテクチャを、マルチ・リージョンベースでもマルチ・クラウドベースでも十分なレジリエンスを備えているかを確認することです。システムをオンプレからクラウドに移行したとしても、ITインフラやサービスの停止を常に想定することが必要です。
クラウドとインターネットは、大規模なインフラである上、複雑で無数に相互接続されているため、その構造の性格上予測不能になりがちです。クラウドはビジネスのあらゆるシーンで、ITを実行するための有効な手段であることは間違いありませんが、万全な準備無くして利用するにはリスクがあります。ビジネスを支えるインフラやソフトウェア、そしてネットワークの複雑さと多様性が増していることを考えると、その時その時の事象を瞬時に把握し、迅速に解析を行うためのタイムリーな可視性が必要です。
ただし、だからと言って、FAANG (Facebook/ Amazon.com/Apple/Netflix/Google) のような巨大企業規模のインフラ・エンジニアリングチームが必要というわけではありません。ThousandEyesのような可視化ソリューションの導入により、自社インフラのみならずインターネットを超えたクラウドインフラからSaaS、サードパーティーAPIプロバイダの監視が可能になります。
なお、その後のGoogleからの説明につきましては下記の記事をご参照ください。https://japan.zdnet.com/article/35138018/


