
「信頼性」は非常に重要です。 そして今や、ベストエフォートを前提としていたインターネットの信頼性までもが重要視されています。しかし残念ながら、インターネットは市場から求められている信頼性を担保できるよう構築されていません。
グローバルに拡がるユーザー、リモートワーカー、SD-WAN移行のバックボーン、これらすべてに共通するものはなんでしょうか? その答えは「インターネット」です。我々はこれまで以上にインターネットに依存しているわけですが、障害発生時に必要なデータを収集し可視化、さらにインターネット規模で根本原因を特定できていますか?
多くの人にとって、インターネットは管理するには複雑すぎ、可視性を維持するには大きすぎ、監視するには広すぎる「ブラックボックス」になっています。 つなぐという当初のネットワークのビジョンがインターネットに成長するにつれて、プロバイダ間の可視性と実行可能性のバランスが徐々に崩れてしまいました。
ユーザーの書き込みやツィートからの障害検知。次のステップは?
実データに裏付けされたThousandEyesのインテリジェンスデータセットであるInternet Insights™は、インターネット規模でネットワークの障害を特定します。
DowndetectorあるいはTwitterからの検知のように、あるレベルの人数からの書き込みやツィートを待つ必要はありません。あるいは根本原因が見つからないまま大量の書き込みやツイートにただただ直面する心配も必要もありません。原因特定の時間を節約し、プロバイダーへのエスカレーションと顧客への通知までのステップを迅速化します。 さらに、より品質の高いプロバイダーの選択も可能になります。 そして、「この問題は自社が原因なのか、それともインターネット障害の影響を受けているのか?」がすぐにわかります。
リアルタイムの実データに基づいた監視
まずInternet Insights™は、サービスプロバイダーのネットワークが宛先のサービスに到達する終端ポイントを特定します。 次に、ThousandEyesの監視テストからのトラフィックが障害の影響を受けた際には、Internet Insights™により、その事象がより大きな障害の一部であるかどうか、宛先の可視性への影響、さらにその他のネットワークパスも影響を受けているかがわかります。
ThousandEyesから個別に設定されたエンドツーエンドの通常監視テストでは、ターゲットの稼働/非稼動、およびトラフィックがネットワーク上でどのパスをたどったかを知ることができます。 ただし、トラフィックが停止した場合、それがある特定の障害によるものなのか、他のトラフィックも影響を受けたのかを指し示すことはできません。しかし、Internet Insights™であればそれが可能になります。 プロバイダーネットワークの障害は、顧客や従業員に対するサービスまたはアプリケーションに多大な影響を与えます。
自社だけの問題ではなく、インターネット全体の問題だった。
昨年の6月に大規模なBGPルートリークがインターネットに広範な障害を引き起こしたことを覚えているでしょうか?障害発生から数時間、インターネット全体でこの障害の影響を受けました。 当初、DiscordのようなアプリケーションプロバイダーやCloudflareのようなCDNプロバイダが障害の原因と疑われました。一方、サービスプロバイダーであるVerizonからの障害情報はなく、後にサービス障害の原因となったBGPルート・リークの主な伝播者であることが判明しました。
多くの関係者にとって、6月24日の障害への対応は大規模な避難訓練となりました。顧客からアプリケーションにアクセスできないという苦情を受け取ったサービスデスクでは対応に追われました。多くのサポートチームが、この解決できない問題をトラブルシューティングするために動員されました。彼らが言えたことは、「アプリケーションは問題ありません」、あるいは「Cloudflareのようなプラットフォームがダウンしている」といったことでしょう。そして、結果的には両方の結論が間違っていたと言えるでしょう。今までの監視では「自社固有の問題なのか?」といった質問に明確に答えることができませんでした。
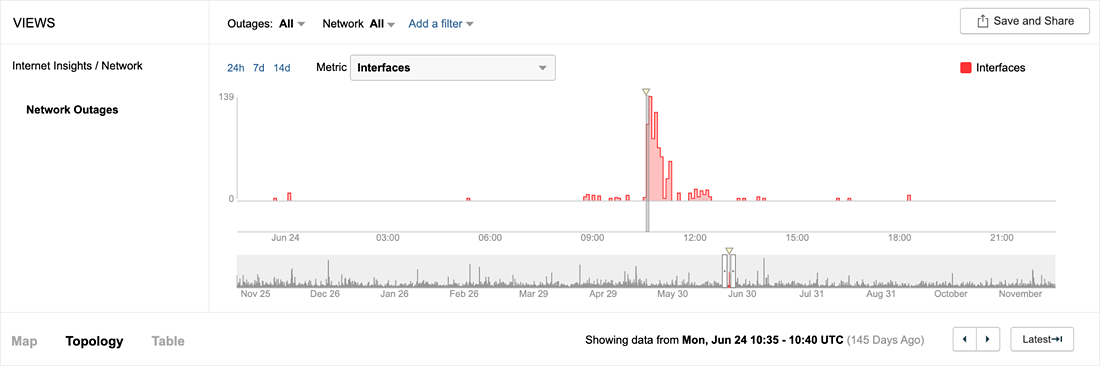
Internet Insights™は、障害検知から、個別のネットワークへの影響度および影響範囲をリアルタイムで特定できます。障害タイムラインには、検知されたすべての障害が表示され、顧客から報告された問題の発生時間にさかのぼり状況をすばやく確認できます。また、プロバイダー、ロケーション、あるいは影響を受けた監視テスト別の便利なフィルタリング機能により、イベントとの関連付けと必要のない情報の削減が容易になります。図1に示すように、10:35 (UTC)のタイムラインでは障害発生が確認できます。
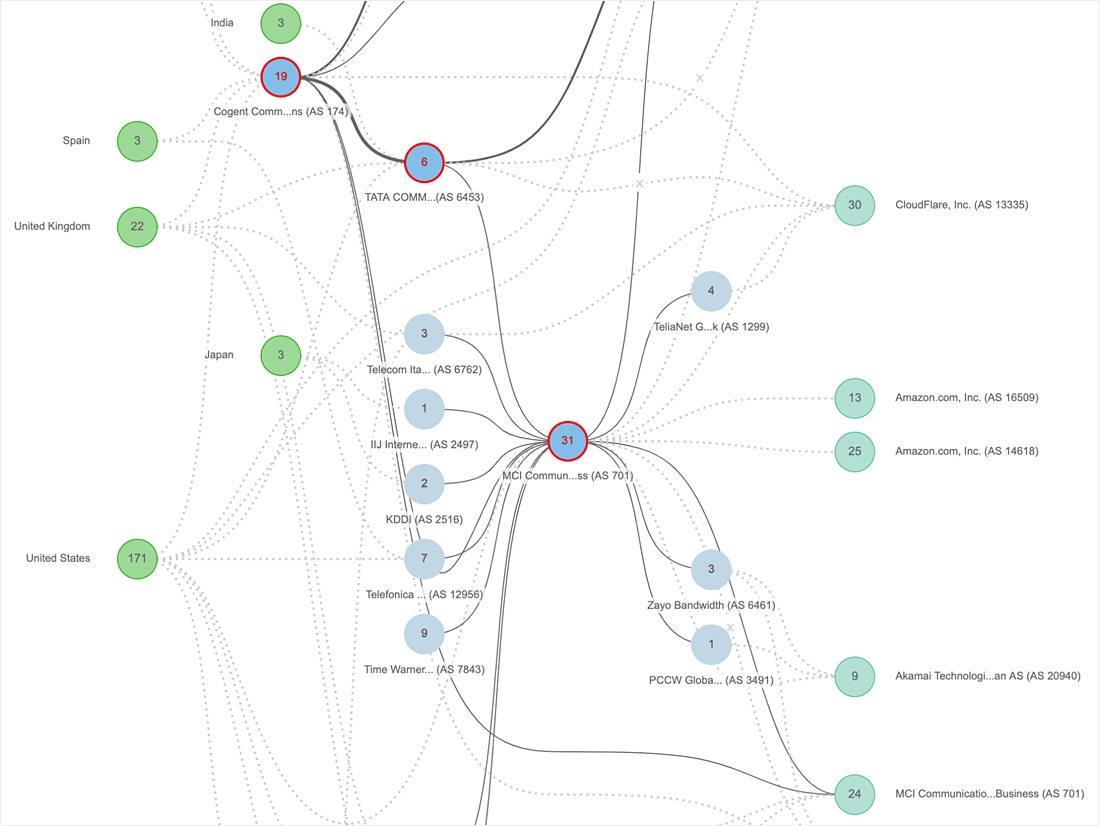
トポロジビュー(図2)は、数多くのデータを個別に調べることなく、障害の原因となっているネットワークの状態を確認するのに役立ちます。 ネットワークの障害は、マップ上で詳細なメタデータとして表示することもできます。 またInternet Insights™では、ワークフローをシンプルにし、「MCI Communications Services、Inc. d / b / a Verizon Business(AS701)」のように障害の震源地を強調表示するようにしました。左側には、影響を受けたテストトラフィックのソースであるエージェントの場所が表示され、右側には、トラフィックの宛先であるインターフェイスに関連したネットワーク(サービスやアプリケーションなど)が表示されます。 中央には、トラフィックが通過したサービスプロバイダーネットワークと、影響を受けたネットワークホップのインターフェイスが表示されます。
結局のところ、この障害はBGPオプティマイザであるNoction社からの意図しないリークが、Verizon社の顧客企業向けデュアルホームネットワークを通して送信されたことが原因でした。これは、本来インターネットに送信されるべきではなかったルートです。 この結果、Cloudflareだけでなく Google、Amazon、Facebook、その他数百のネットワークが影響を受けました。 Cloudflareは、障害の原因として広く知れ渡りましたが、単なる副次的な被害者だったのです
障害検知から切り分けまで
障害アラート:エージェントのインストールやテストの実行に必要なインフラがない場所のネットワーク障害発生時でも、障害解析は可能です。障害アラートは細かく焦点を絞ることができ、重大度、場所、影響を受けるエージェントテスト、特定のプロバイダー、その他の条件によって障害データをフィルタリングできます。また、障害アラートは、電子メール通知や、たとえばSlackを介した障害通知などの統合をサポートしています。これらの情報を活用して、主要顧客への状況報告を促進したり、サービスプロバイダーとの改善活動を進めることができます。
障害スナップショット:ThousandEyes製品の最大の魅力のひとつであるスナップショット共有機能は、問題発生時のビューを関係者全員に容易に共有でき、Internet Insights™でも同様に利用可能です。障害スナップショットでは、Internet Insights™ビューだけでなく、影響を受けた個別のテストデータを1つのリンクでキャプチャして共有できます。
障害履歴:1年間分のデータから、過去の障害を分析し、プロバイダーごとに過去の障害を相関させて、長期にわたるパフォーマンスを確認できます。障害が一時的なものか、あるいはパターン化された現象の一部かを確認できます。プロバイダーを変更すべきか、新しい回線を契約すべきか、Internet Insights™のデータが役立ちます。
インターネットヘルス・ダッシュボード
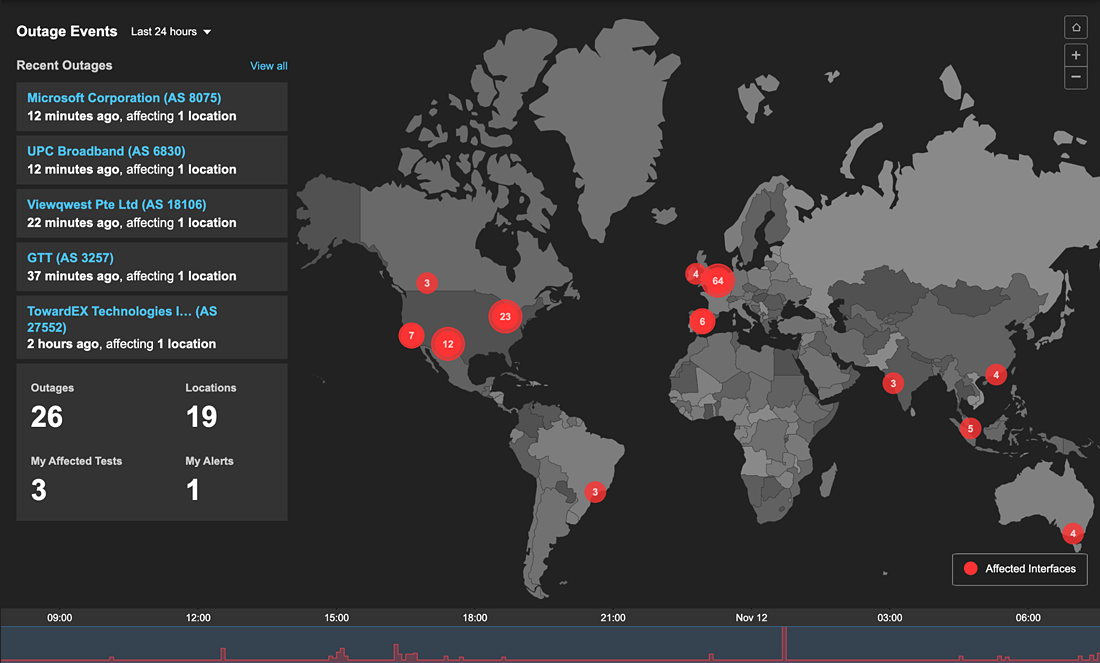
Internet Insights™のダッシボード(図3)は、最近発生あるいは進行中のプロバイダーネットワーク障害を表示したいわば「インターネット世界天気図」です。 一目で、NOC、サービスデスク、その他のチームは、インターネット障害の影響を受けている顧客や従業員にすばやく対応したり、問題をサービスプロバイダーにエスカレーションすることが可能になります。 [ダッシボード]ビューから[タイムライン]ビューまたは[トポロジ]ビューまで簡単にクリックで移動して、顧客が契約するサービスプロバイダーのフィルタリングや、根本原因と思われるネットワークにドリルダウンできます。
Internet Insights™の次のステップは?
Internet Insights™の旅は、まだ始まりに過ぎません。 ThousandEyesのインテリジェンスデータセットは、可用性、パフォーマンス、グローバルのルーティング変更、ハイジャック、リーク等に関連する様々な疑問に答える鍵を握っています。
我々の信念は「事前対策のアプローチ」であり、インターネットをただ監視するだけでなく、インターネット規模でデジタル体験を管理するプラットフォームを提供します。インターネットのような集合型のネットワークに真の改善をもたらすには、実データを元にした可視性を備えたアプローチをとる必要があると考えています。


