
インターネット障害は、ビジネスに大きな混乱をもたらします。障害によりユーザーがアプリケーションやサービスにアクセスできなくなると、企業の収益と評判に大きな損害を与えます。Webサービスの事業者は、複数のインターネットサービスプロバイダー(ISP)に加えて、CDN・DNS・DDoS緩和・パブリッククラウドといった大規模で複雑なエコシステムに依存しています。これらのサービスはユーザーに優れたデジタルエクスペリエンスを提供するために相互で連携していますが、その反面短時間の中断でも大きな影響を与える可能性があります。
さらに、個々の企業も自社サイトへの外部からの接続や、ビジネスに不可欠なクラウドサービス等、インターネットへの依存度が高まっています。アプリケーションが自前のデータセンターでのみホストされ、オフィス間が主にMPLSのようなキャリア閉域網のみで接続されていた時代から、SD-WAN等の導入が進むにつれて、閉域網サービスはインターネットVPNに取って代わるか、ハイブリッド環境になりつつあります。その結果、インターネットは事実上、企業のバックボーンとなり、ビジネスにとって非常に重要な存在となりつつあるのですが、「ベストエフォート」の概念で構築・運用されてきたトランスポートであるが故に予期せぬ結果をもたらす可能性もあります。
昨年もThousandEyesは、企業と利用者側の両方に大きな影響を与えた複数のインターネット大規模障害についてレポートしてきました。
2019年の大規模インターネット障害
ここからは、昨年起こった大規模障害について振り返ってみましょう。
2019年5月13日―チャイナ・テレコムの障害により、世界にもたらすその影響力が明らかに(英語リンク)
チャイナ・テレコムのネットワークで発生したグローバル規模の障害は、今後も起こりうるインシデントの前兆であると言えるでしょう。また、チャイナ・テレコムが及ぼす影響範囲が中国本土をはるかに超えるという教訓も明らかになりました。
2019年5月13日、約5時間、チャイナ・テレコムのバックボーン全体で重度のパケットロスが発生し、主に中国本土のネットワークインフラに影響を与えましたが、同時にシンガポールのネットワークとロサンゼルスを含む米国の複数のポイントにも影響を与えました。その結果、100以上のサービスが中断し、Apple、Amazon、Microsoft、Slack、Workday、SAPなどの米国ブランドのサービスにも大きな被害をもたらしました。
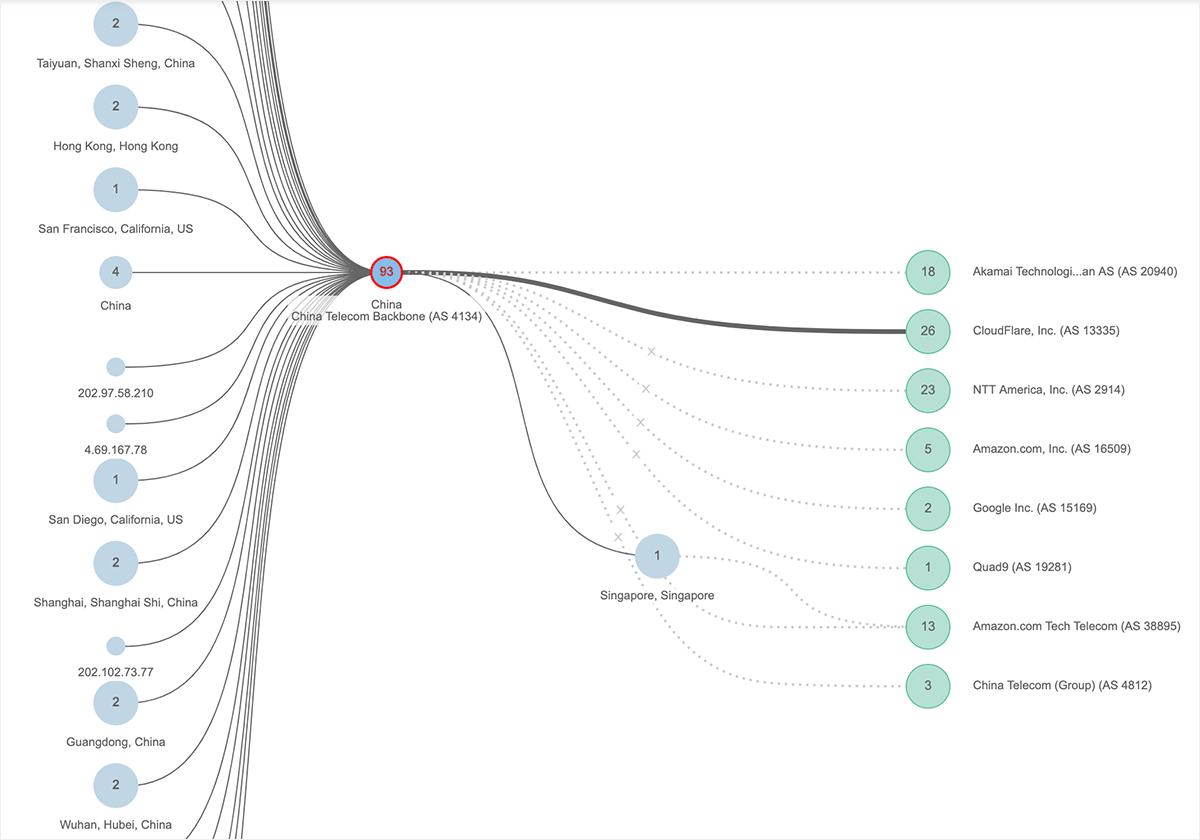
このインシデントにより、中国のインターネット環境における現実と、多くの人が気付いていなかったグローバルレベルのインターネットへの影響度が明らかになりました。具体的には、中国のインターネットユーザーに適用されている検閲ポリシー(Great Firewall)が、実際には中国の国境をはるかに超えて、ポリシーが全く異なる国へも影響を与えたのでした。
2019年6月2日― Google Cloud Platformで起きた障害から学ぶこと ~マルチリージョン、マルチクラウド環境の整備(日本語リンク)
2019年6月2日、Google Cloud Platformにて、米国西部、東部、中央部でホストされているサービスの一部に影響を与える重大なネットワーク障害が発生。最終的にサービス停止は4時間以上続き、YouTube、G Suite、Google Compute Engineなどのさまざまなサービスへのアクセスにも影響を及ぼしました。これは、ビジネス顧客にとって重要なサービスで発生した顕著なインシデントでした。 Googleは数日後に公式報告書を発行しました。 ThousandEyesの有利な点は、リアルタイムで障害状況を確認することができ、後日より詳細な情報が公開される前に、障害特性やその影響範囲を効果的に知ることができるのです。
午前9時頃、ThousandEyesが運用するグローバルモニターから、GCP us-west2-aにホストされているサービスへのアクセスにて100%のパケットロスを検知しました。 さらにus-east4-cを含むGCP US Eastやその他のサイトでも同様のパケットロスが検知されました。
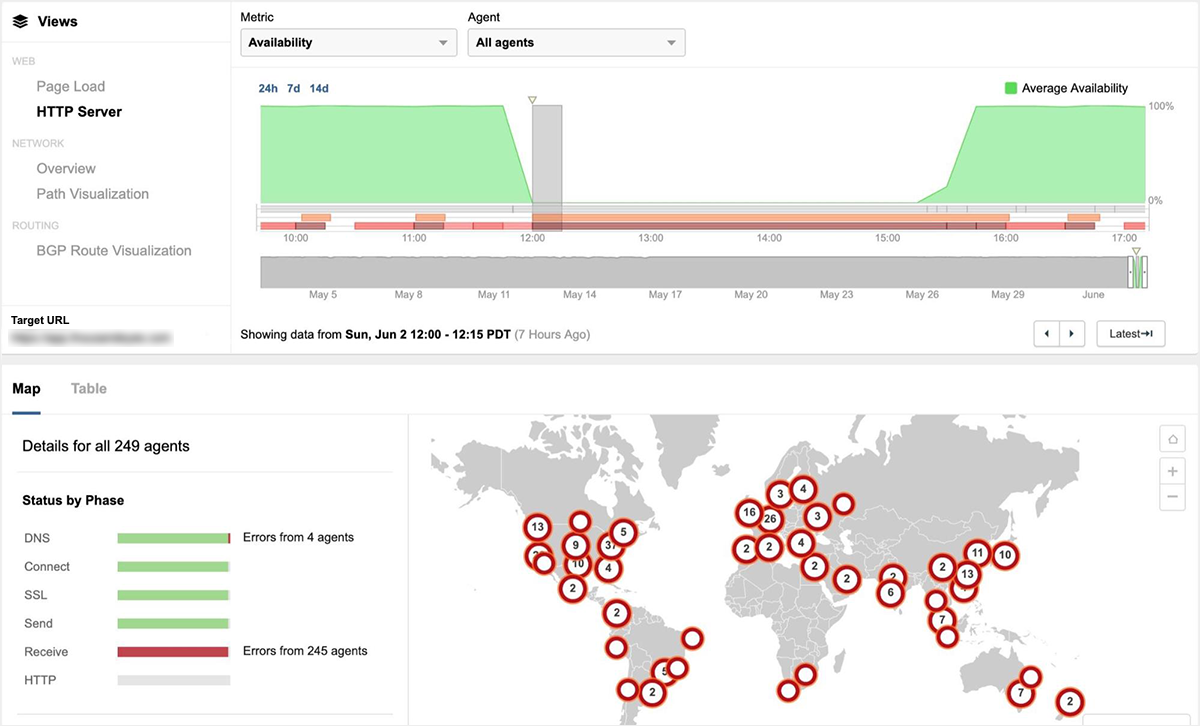
Googleのネットワークの一部が完全に利用できなくなった障害の原因は、後にGoogleのネットワークコントロールプレーンが誤ってオフラインになったためと判明しました。さらに、障害発生中には、一連の自動化されたポリシーの利用により、ネットワーク障害の影響を受けていないエリアから到達できるサービスと到達できないサービスを監視していたことも明らかにしました。
このようなクラウド障害から学ぶ最も重要なことの1つは、今後も起こりうる障害の再発から自身を守るために、クラウドアーキテクチャがマルチリージョンやマルチクラウドベースであったとしても、サービス継続のための十分な対策を講じることです。
2019年6月6日-一連の不幸なイベントにより、多くのユーザーが WhatsApp(SNS)にアクセス不可(英語リンク)
2019年6月6日、世界中の多数のユーザーがWhatsAppサービスにアクセスできなくなりました。 ThousandEyesは、アクセス不可の原因が100%のパケットロスであることをすぐに確認できました。そしてさらなる分析により、このパケットロスの根本的な原因は、トラフィックがチャイナ・テレコム(Facebook関連のトラフィックを転送しないサービスプロバイダー)に経路変更される大規模なルートリークであると判断しました。
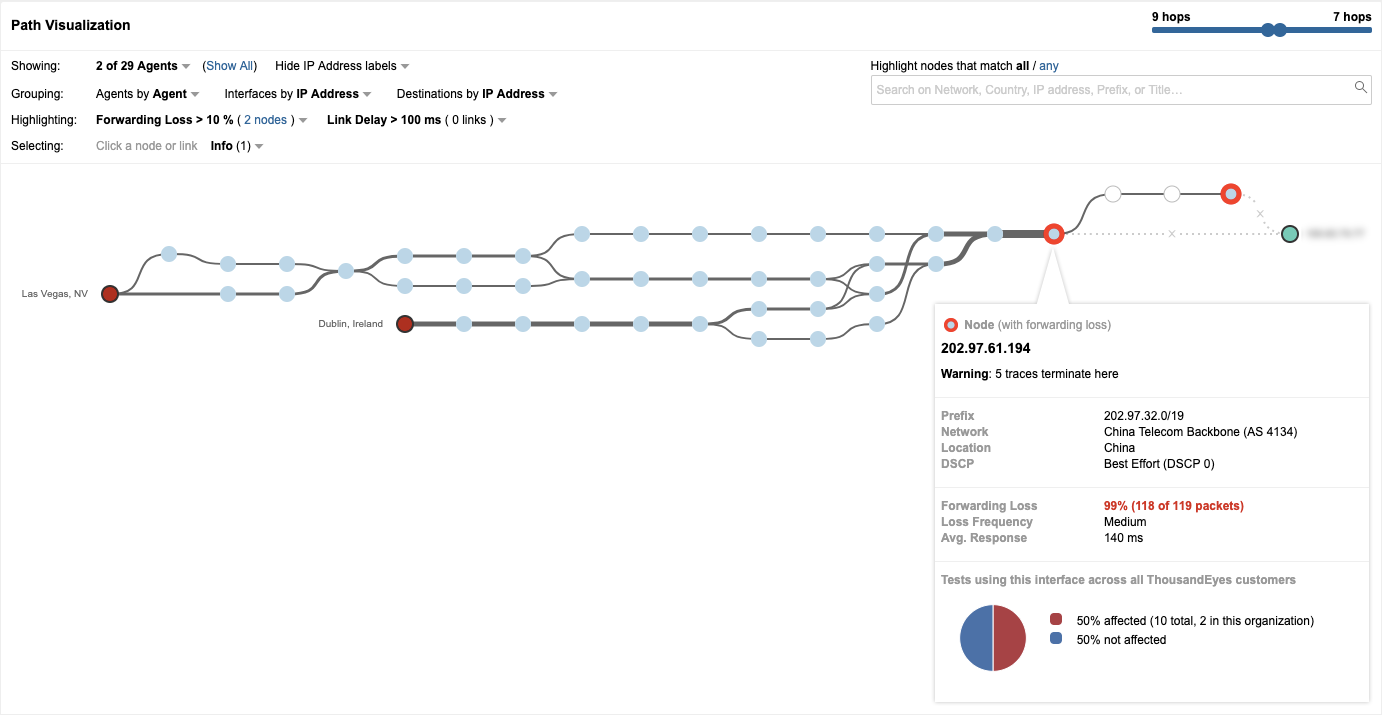
このインシデントは、Safe Hostと呼ばれるスイスのコロケーション事業者が、WhatsAppを含むその他何千ものIPプレフィックスに到達するための最適パスは「ネットワークAS 21217経由」と広報したことが発端でした。 この広報された経路はチャイナ・テレコムにより受信され、Cogentなどその他のISPを介してさらに伝播されました。その結果、トラフィックがCogentにルーティングされ、最終的にチャイナ・テレコムに渡されたユーザーは、WhatsAppサービスに完全にアクセスできなくなりました。
そもそもチャイナ・テレコムが検閲により遮断しているサービスへのルートを何故受け入れたのか理由は不明ですが、この障害から学んだ教訓は、インターネットの世界では、BGPルートリークは珍しい事象ではないということです。脆弱な相互接続によるエコシステムで形成されるインターネットを利用する場合、その仕組みを理解し、あるサービスプロバイダーの「ミス」が別のプロバイダーに連鎖的な影響を与える可能性があることを常に想定する必要があります。残念なことに、BGPルートリークやその他のインターネットの弱点に関連するビジネスリスクは、企業とサービス事業者の現状を考えると、さらに大きなものになっていくでしょう。
2019年6月24日―CDN利用者に大打撃を与えたインターネットルーティング障害の真相(日本語リンク)
WhatsAppユーザーに影響を与えた大規模なルートリークのわずか数週間後、インターネット上でさらに別のルーティング関連のインシデントが発生し、被害ははるかに大きなものでした。
2019年6月24日、2時間近く、重大なBGPルーティングエラーが、ゲームプラットフォームDiscordやNintendo Lifeなど、CDNプロバイダーのCloudflareが提供するサービスにアクセスしようとするユーザーに影響を与えました。 ThousandEyesの分析により、重大なBGPルートリークが複数のプロバイダーからのさまざまなプレフィックスに影響を与えていたことがわかりました。そして、DQEとVerizonの両方の顧客であるAllegheny Technologiesを通じて伝播されたルートリークの発生源は、トランジット・プロバイダーのDQEであることが判明しました。さらに残念なことに、Verizonがルートリークをさらに伝播し、その影響を拡大してしまったのです。
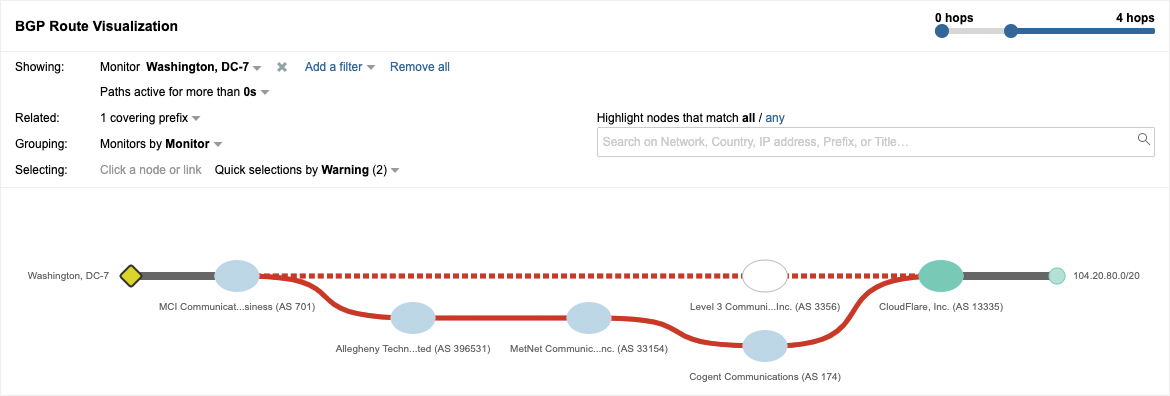
CloudFlare のCDNを介して提供されるサイトは、ほぼ2時間の間影響を受けました。この大きなインターネットの混乱は、Cloudflareのグローバル・トラフィックの約15%に影響を与え、Discord、Facebook、Redditなどのサービスに影響を与えました。ルートリークは、一部のAWSサービスへのアクセスにも影響しました。
インシデントの根本的な原因は、BGPオプティマイザーソフトウェアの使用に起因するもので、DQEの内部ネットワーク内でのみ使用されることを意図したCloudflareサービスへのルートが、誤って顧客のいずれかにリークしてしまったのです。
このインシデントにより、インターネットサービスの提供状況を劇的に変えることがどれほど簡単なことかを思い知らされました。クラウド中心の世界では、企業がユーザーに確実にサービス提供するためには、インターネットの可視化が必要になるのです。
2019年7月4日― 7月4日に影響を受けたAppleサービス(英語リンク)
2019年7月4日、午前9時 (太平洋標準時) 直前、AppleのウェブサイトとApple Payなどのサービスの一部に接続していたユーザーは、90分以上にわたって重度のパケットロスの影響を受けました。この問題により、多くのユーザーがAppleに正常に接続できなくなりました。 ThousandEyesのルート可視化により、パケットロスがBGPルートのフラップによって引き起こされたことがわかりました。 なおBGPのルートフラップは、経路の広報と撤回が短時間に頻繁に繰り返される際に発生します。
Starting just before 9am PDT ThousandEyes tests detected that users connecting to https://t.co/oWmaAu38BU and Apple services, such as Apple Pay, began experiencing significant packet loss, which would have prevented many of them from successfully connecting to those services. pic.twitter.com/djA5DKACb4
— ThousandEyes (@thousandeyes) July 4, 2019
アップルのサービスは多くのインターネットユーザーにとって非常に重要ですが、休日の早い時間での障害だったことで、実際のところ少数のユーザーからの苦情で済ませることができました。このインシデントから得られる教訓は、障害は可能な限り早い段階で解決する必要があるということです。重度の障害でも、タイミングと内容によっては気付かれない場合がありますが、さもなければ、大きな騒動を引き起こすことになるでしょう。
2019年9月6日―ウィキペディアを襲ったDDoS攻撃を解析(日本語リンク)
2019年9月6日、大規模なDDoS攻撃により、Wikipediaサイトへのアクセスが9時間近く中断されました。DDoS攻撃は、ターゲットのWebインフラに極度の負荷をかけることにより、サービスプロバイダーネットワーク内で輻輳を引き起こし、パケットロスを発生させます。これらの現象の過程は、Wikipediaが攻撃を受けた際にThousandEyesにより記録されていました。
インシデントの過程で、世界各所からのHTTPサーバーへのアクセスのアベイラビリティが大幅に低下し、HTTP応答時間が劇的に増加しました。その結果、多くの地域のユーザーは、Wikipediaサーバーとの継続的なインターネット接続を確立することができませんでした。また、ThousandEyesが世界各国で運用する監視エージェントからは、最大60%のパケットロスを測定しました。これが、ウィキペディアのサイトへのアクセスをさらに妨げる要因となりました。
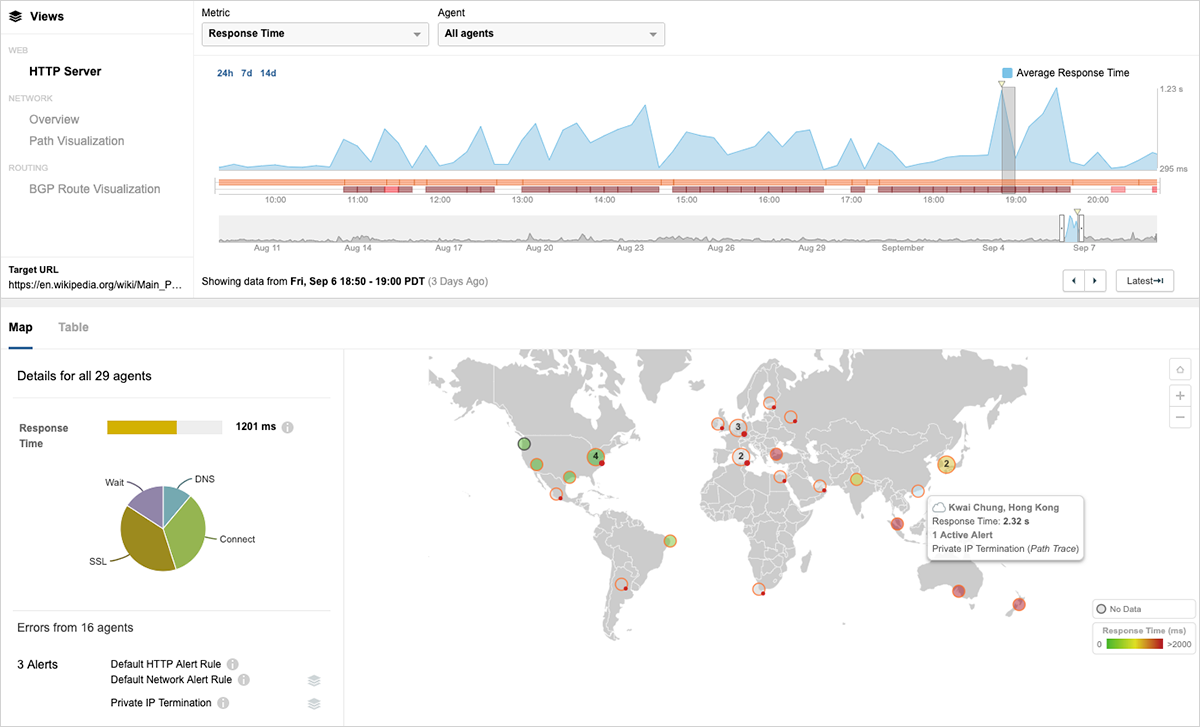
DDoS攻撃はインターネットで仕掛けられる非常に残念な現実ですが、組織はこれらのイベントの範囲、影響、および動作を可視化し、DDoS緩和の対策が効果的であるかを常に検証できる必要があります。
ビクトリーロード ~ 被害者から勝利者への道
多くの企業にとってインターネットは「ブラックボックス」であり、ITおよびデジタル運用チームは、重度の障害が発生すると多くの場合、原因の特定や迅速な対応ができなくなります。ISP間の相互接続により形成されるインターネットの脆弱な性質により、障害を避けられないのが現実ですが、これらの障害を可視化することで、インシデントの解析からエスカレーション・解決に要する時間を大幅に短縮でき、顧客とのコミュニケーションを改善できます。
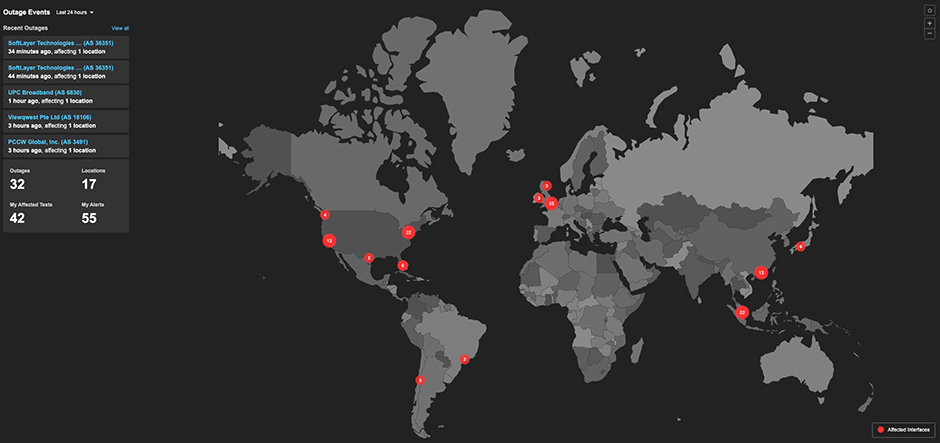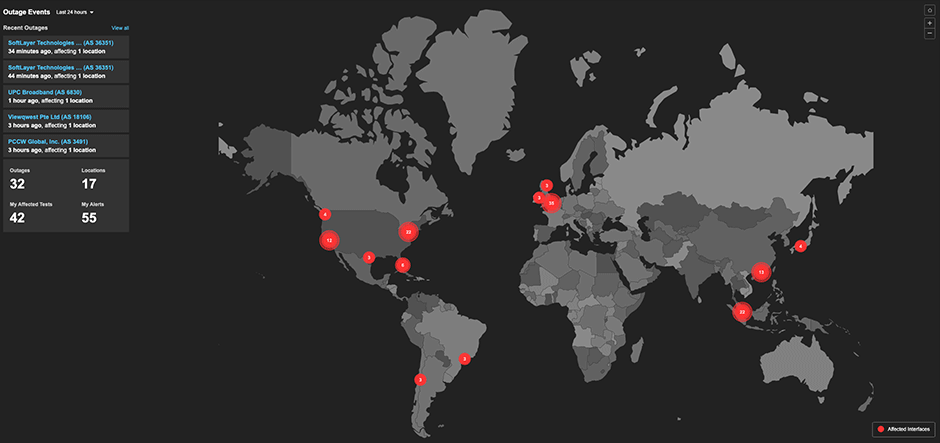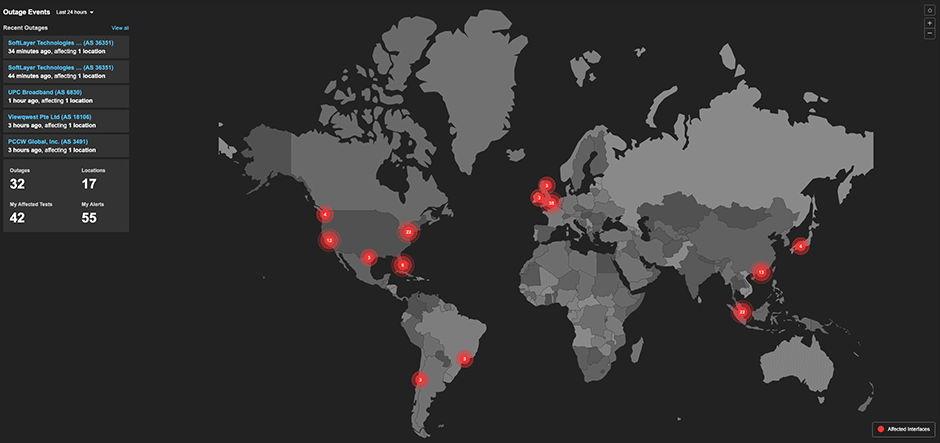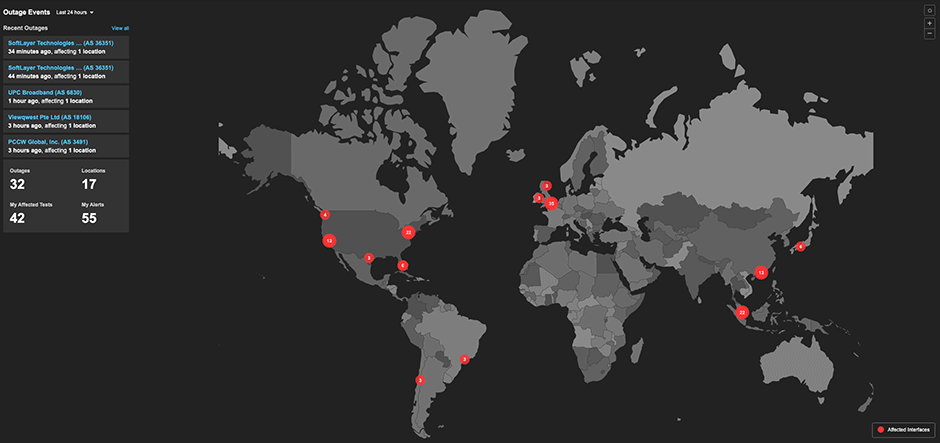
インターネットの予測不能性が組織にもたらすリスクを理解された今、ThousandEyesをお試しいただく絶好のタイミングです。 当社が最近リリースしたInternet Insights™サービスは、何十億/日ものインターネット測定から得られた集合知を活用して、インターネットの健全性を可視化します。
Internet Insights™は、障害発生時に特定のサービスプロバイダーと場所を特定して問題の切り分けを行い、NOCスタイルのダッシュボード、およびタイムラインとインシデントビュー上でこれらの障害状況を表示します。SNS上での書き込みではなく、実測データに基づいた障害状況の可視化は、運用チームが進行中のインシデントのトラブルシューティングを行うのに役立つだけでなく、ネットワーク管理者や企画担当者がプロバイダーの信頼性を長期にわたって理解するのにも役立ちます。
ご質問等ございましたら、お気軽に japan@thousandeyes.com までお問い合わせください。


