Ob Sicherheit, Netzwerk oder Helpdesk – IT-Fachbereiche wie auch die zugehörigen Rollen verändern sich rasant. Anstelle der klar voneinander abgegrenzten Silos, die das Bild in der Vergangenheit prägten, treten heute hybride Arbeitsmodelle und diverse Abhängigkeiten von Dritten. Daher wird es immer wichtiger, diese Verflechtungen anhand stärker integrierten Daten und präziserem Kontext nachvollziehen zu können. Denn erst so lässt sich die nahtlose, konsistent hochwertige Digital Experience gewährleisten, die Kunden und Belegschaft gleichermaßen benötigen.
Umso mehr freuen wir uns, auf der Cisco Live in Amsterdam eine ganze Reihe von Innovationen für genau diese Anforderungen vorstellen zu können. Ganz im Zeichen einer hochwertigen Digital Experience in jedem beliebigen Netzwerk wird es damit möglich, sämtliche User verlässlich zu managen – ganz gleich, welche Geräte sie nutzen und wo sie sich befinden. Alle Einzelheiten haben wir im Folgenden für Sie zusammengefasst. Über die Links können Sie dabei auch direkt die Highlights aufrufen, die für Sie besonders relevant sind.
Tiefergehende Einblicke für das Management der Remote-Belegschaft
-
Cisco Secure Access Experience Insights: Einblicke in Faktoren mit Einfluss auf die Netzwerkperformance für Security-Teams durch Integration von ThousandEyes mit Cisco Secure Access
-
Metriken zu Systemprozessen für ThousandEyes Endpoint: Vereinfachtes Remote-Troubleshooting durch Transparenz über Interaktionen zwischen Geräten und Applikationen
Effizientere Testeinrichtung
-
Erweitertes API-Monitoring: Benutzerfreundliche Einrichtung von API-Tests für umfassende Einblicke bei minimalem Konfigurationsaufwand
-
Vorlagen für Endpoint-Tests: Vereinfachte Endpoint-Konfiguration anhand einer breiten Auswahl App-spezifischer Vorlagen
Differenzierter Datenzugriff
-
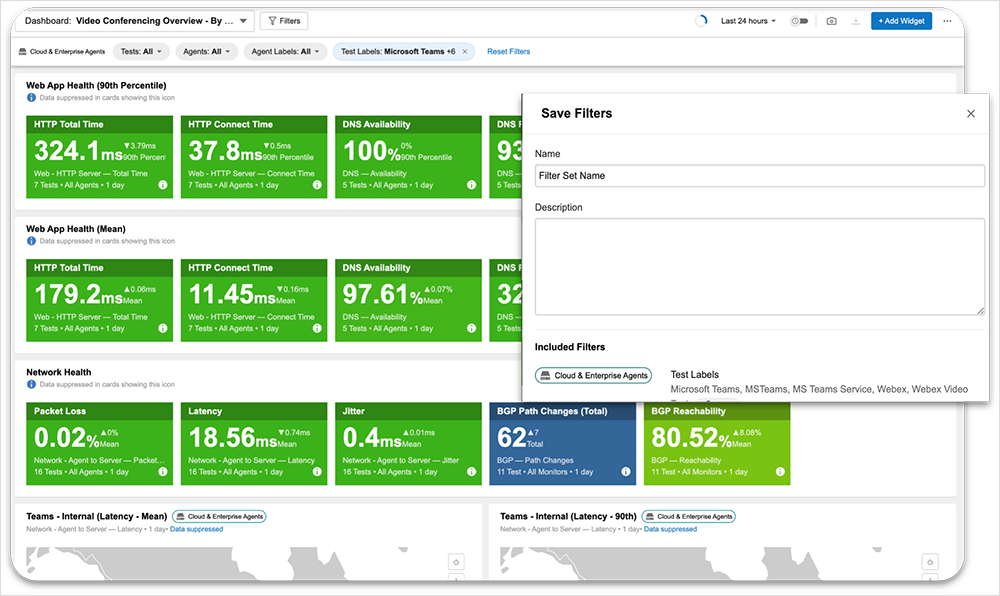
Dashboard-Filter: Mehr Effizienz für Betriebs- und Monitoring-Abläufe durch unkomplizierte, flexibel konfigurierbare Filter
Tiefergehende Einblicke für das Management der Remote-Belegschaft
Cisco Secure Access Experience Insights
Experience Insights erweitert Cisco Secure Access um essenzielle Funktionen, die ITOps-Teams eine schnellere Diagnose und Behebung von Konnektivitäts- und Performanceproblemen ermöglichen. Hierzu integriert das Feature die Power von ThousandEyes für Digital Experience Monitoring direkt in unsere Lösung für den Secure Service Edge (SSE) — ein entscheidender Aspekt für das Management der Digital Experience sowohl innerhalb als auch außerhalb des Unternehmensnetzwerks.
Es werden relevante Daten zur Endpoint Performance erfasst, welche den ITOps-Teams dabei helfen, schnell die Ursachen für Probleme auf Nutzerseite zu identifizieren – unabhängig davon, ob diese in ihren Geräten oder dem zugrunde liegenden Netzwerk liegen. Experience Insights erweitert Cisco Secure Access durch Kontextinformationen, die aufzeigen, wie End User Geräte die Leistung von Apps beeinflussen. So können sie in Troubleshooting-Szenarien Leistungsabfälle in lokalen Netzwerken oder App- und Systemprozesse identifizieren, die verfügbare Ressourcen übermäßig beanspruchen. Möglich wird dies durch detaillierte Einblicke in die Hardwareauslastung sowie umfassende Statistiken zu lokalen Netzwerken und wichtigen Collaboration- und SaaS-Applikationen.
Innerhalb von Secure Access erhalten Admins eine Dashboard-Übersicht, die neben dem allgemeinen Status von Geräten auch wichtige Netzwerk- und Gerätemetriken direkt einsehbar macht. Fehlfunktionen oder Überlastungen einzelner Geräte lassen sich so schnell ausmachen und beheben.
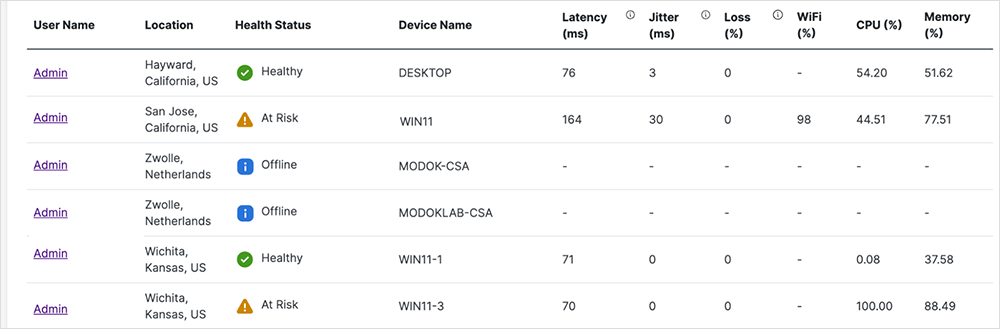
Unter „Common SaaS Applications Performance“ (Performance gängiger SaaS-Applikationen) wird der Zustand von Geräten mit dem Status wichtiger Applikationen in Zusammenhang gesetzt. Testergebnisse, die ThousandEyes über seine globalen Beobachtungspunkte für gängige SaaS-Applikationen ermittelt, werden dazu in einer korrelierten Ansicht zusammengeführt, mit deren Hilfe IT-Teams App-bezogene Performanceprobleme effektiver erkennen und beheben können. Details zur Server- bzw. HTTP-Konnektivität ermöglichen dabei eine umfassende Diagnose der Ursache – ganz gleich, ob ein Problem lokal verortet ist oder auf einen globalen Ausfall zurückgeht. Durch Eingrenzung der Daten nach Region lässt sich dabei auch bestimmen, ob nur einzelne oder mehrere Bereiche betroffen sind.
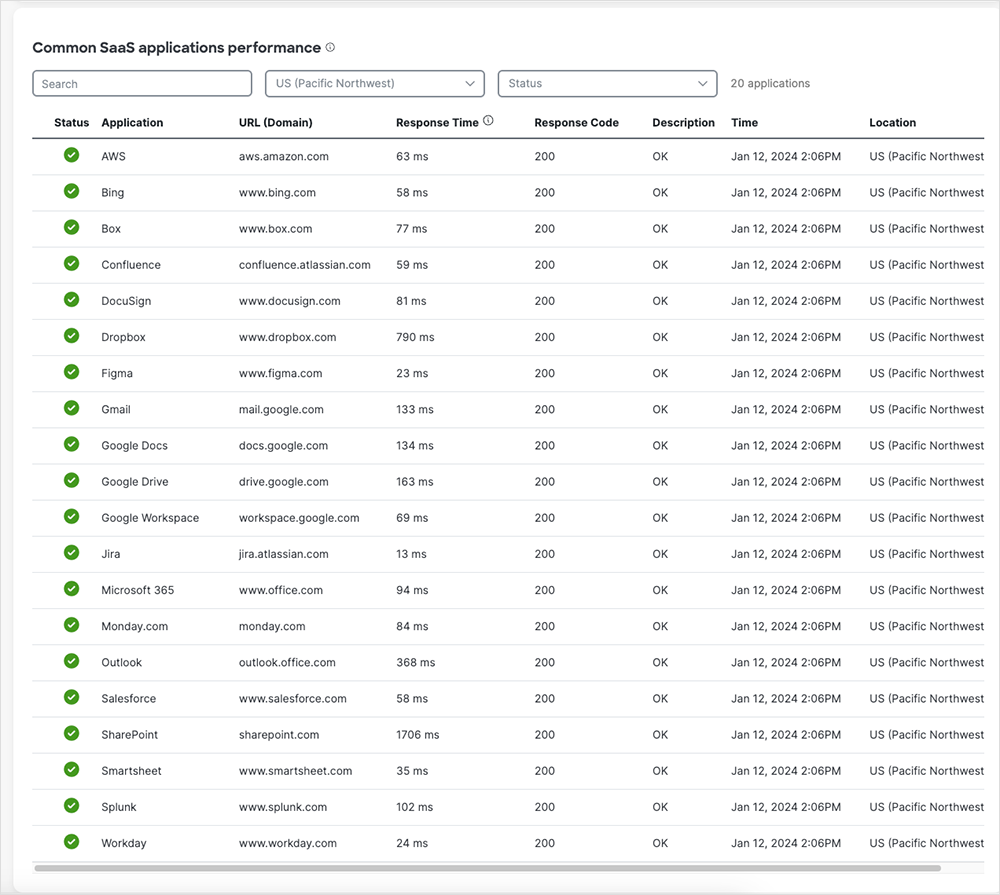
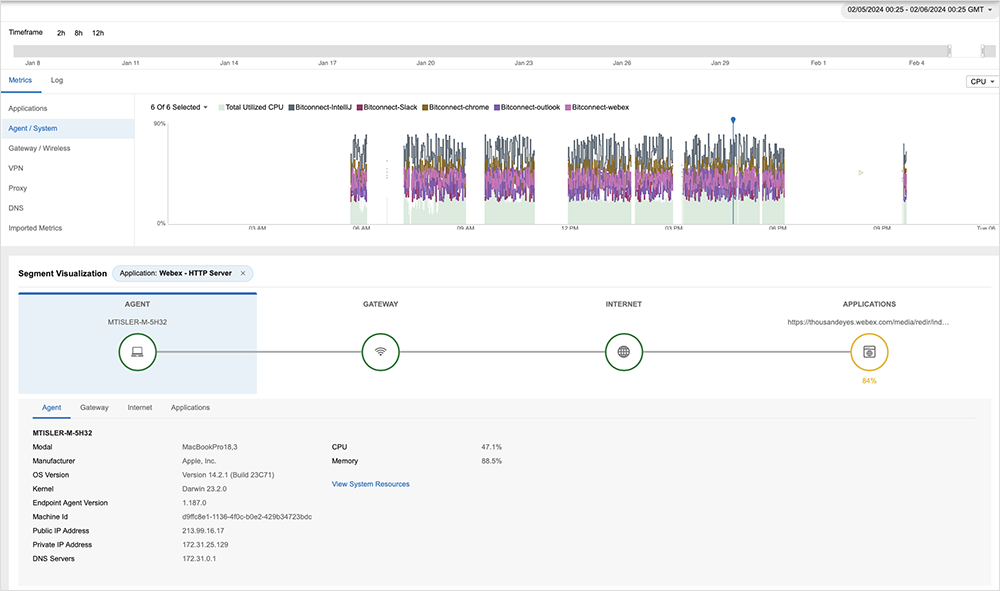
Zur weiteren Analyse einzelner Geräte bietet Experience Insights eine detaillierte Ansicht zur Performance sämtlicher Systeme, für die das Feature das Monitoring durchführt. Neben User- und Gerätedetails umfasst diese eine umfassende Aufschlüsselung von Performancedaten, darunter CPU- und Arbeitsspeicherauslastung, Verbindungsgeschwindigkeit und Pfad des lokalen Netzwerks sowie Metriken zum Verbindungsweg vom Client zum Secure Access Gateway bis zur Applikation.
Performancedaten zu kritischen Collaboration-Applikationen wie etwa Webex by Cisco sind dabei sowohl nach dem aktuellen Status quo als auch im Zeitverlauf einsehbar. Für detaillierte Netzwerkeinblicke kann zudem direkt in die ThousandEyes Plattform gewechselt werden. Diese Möglichkeiten zur tiefgehenden Analyse sind für ITOps-Teams ungemein wertvoll, da sie damit schnell feststellen können, ob Probleme auf Geräte oder das Netzwerk zurückgehen.
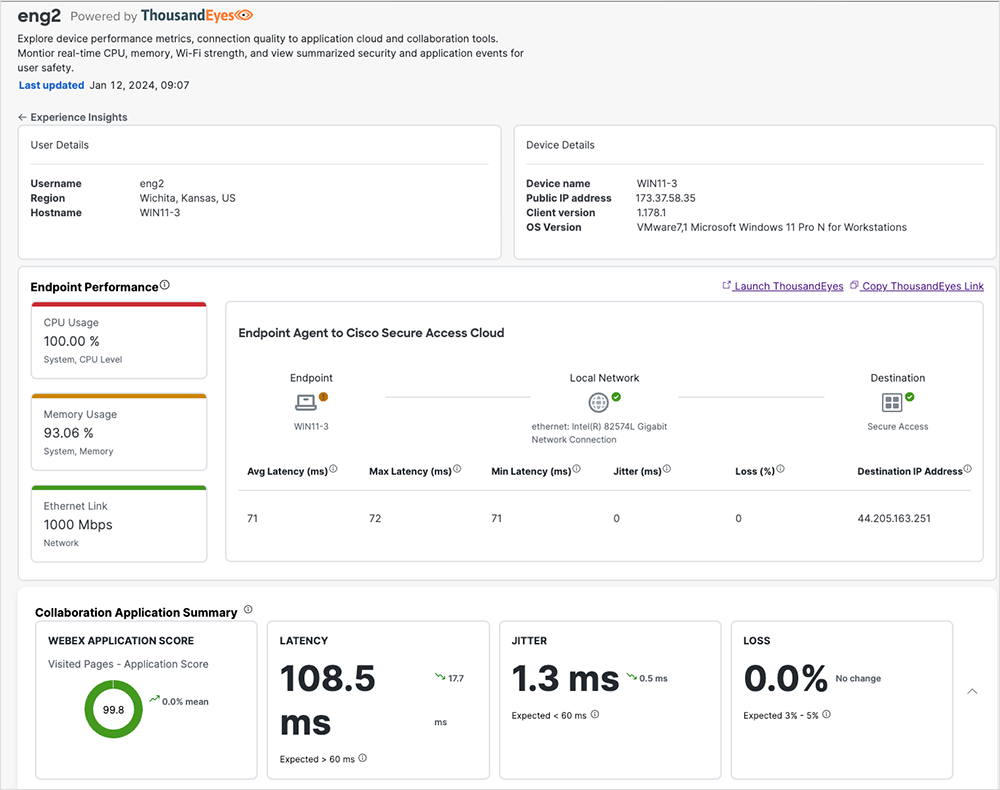
Durch diese komplett integrierte Sicht auf die Endpoint-Performance vereinfacht Experience Insights nicht nur die Abläufe in der IT, sondern trägt auch zu einer noch gezielteren Optimierung der End User Experience bei. Im Einklang mit dem SSE-Framework vereinfacht die Lösung das Management von Cisco Secure Access und sorgt dafür, dass für User stets ein verlässlicher und effizienter Zugriff auf wichtige Applikationen und Services gewährleistet bleibt.
Weitere Informationen darüber, wie Experience Insights die Power von ThousandEyes in Cisco Secure Access bringt, finden Sie im Blog von Joe Vaccaro, Head of Product bei ThousandEyes.
Metriken zu Systemprozessen für ThousandEyes Endpoint
Der ThousandEyes Endpoint Agent liefert Daten zur Netzwerk- und Systemperformance. Diese sind unerlässlich für das Verständnis der User Experience und dafür, Problemen bei der Interaktion zwischen Geräten und SaaS-Applikationen sowie externen Netzwerken auf den Grund zu gehen. Diese Einblicke werden nun um gerätespezifische Metriken zur Ressourcennutzung und -zuweisung ergänzt: Anhand detaillierter Daten zur CPU- und Arbeitsspeicherauslastung jeder einzelnen Applikation lässt sich feststellen, welche Programme oder Prozesse zu Überlastungen führen.
Wie in Abbildung 4 gezeigt, werden diese Daten zusammen mit Netzwerkmetriken sowie dem Pfad zur Applikation dargestellt. Dank dieser detaillierten Kontextansicht lässt sich schnell ermitteln, ob ein Problem vom Netzwerk oder der lokalen Applikation ausgeht.
Effizientere Testeinrichtung
Erweitertes API-Monitoring
API-Monitoring mit ThousandEyes wird um eine neue Testvariante erweitert, die speziell auf API-Endpoints ausgelegt ist. Damit gehen wir direkt auf das Feedback unserer Kunden ein, demzufolge hier Bedarf im Hinblick auf Troubleshooting- und Betriebsprozesse für ITOps-, SRE- und NOC-Teams bestand. So ermöglicht dieses Feature eine eindeutige Korrelation von User Experience und Problemen, die auf das App-Backend zurückgehen. Außerdem wird die Identifikation kritischer API-Endpoints erleichtert, die noch nicht durch das Monitoring abgedeckt werden.
Die API-Tests sind zudem enorm vielseitig: SRE-Teams können ihre Implementierung via Terraform oder als Teil einer Pipeline zur App-Bereitstellung vornehmen, in NOC-Umgebungen lassen sie sich für Dashboard-Monitoring einbinden. Dabei kann die Performance-Ermittlung an allen der über 200 globalen Beobachtungspunkte unserer Agents erfolgen. Admins erhalten damit eine weitere enorm nützliche Ressource für Network Assurance.
Probleme mit der API-Funktionalität, die sich auf die Performance auswirken, lassen sich mit dieser neuen Testvariante leichter identifizieren. Die Einrichtung erfolgt dabei ganz ähnlich wie bei anderen ThousandEyes Tests: Zunächst navigieren User zu „Test Settings“ (Testeinstellungen) und wählen „API“ als Testvariante aus. Über den API Step Builder sowie anhand von Vorlagen für Testszenarien können sie dann mehrere Einzelschritte für verschiedene Anfrage-URLs ergänzen und Werte aus früheren API-Antworten in darauffolgenden API-Anfragen verwenden. Einen zentralen Aspekt bildet zudem die Sicherheit: Dank Integration mit unserem Anmeldedaten-Repository und spezieller Verarbeitung von API-Secrets und -Authentifizierung bleibt die Sicherheit und Verlässlichkeit dieser Tests für API-Monitoring stets gewährleistet.
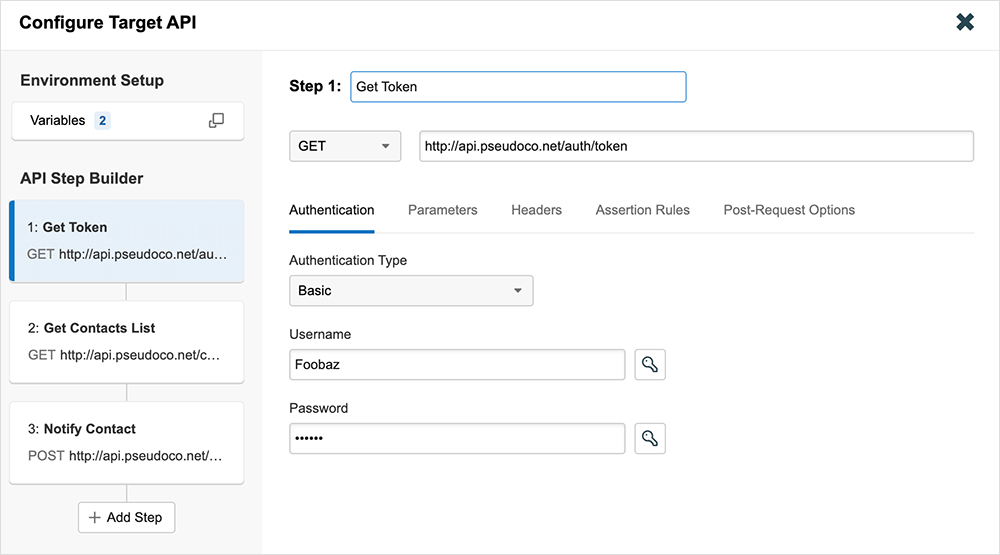
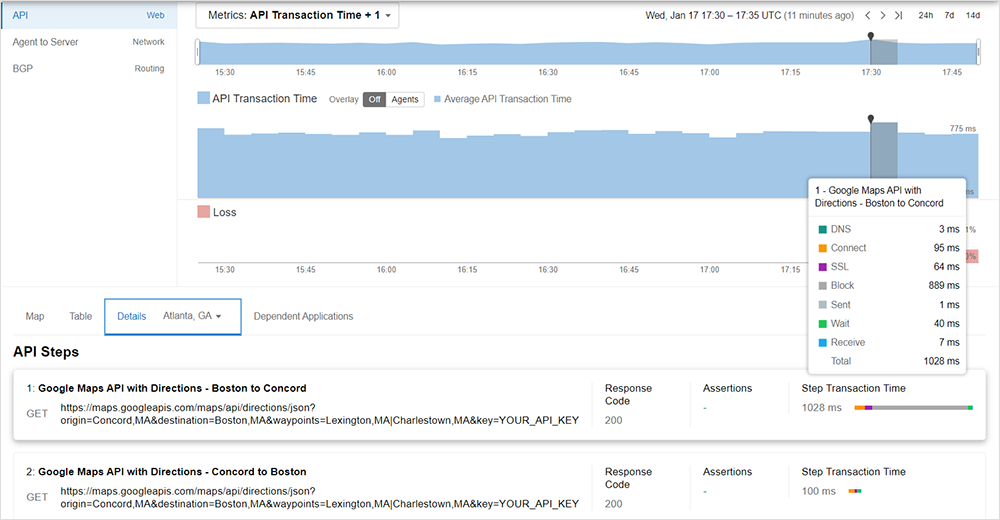
Tests für API-Monitoring können flexibel entsprechend dem gewünschten Grad der Komplexität angepasst werden. Tests mit mehreren Einzelschritten liefern ITOps-Teams dabei die Einblicke, die sie in ihr API- und App-Ecosystem benötigen. Nachfolgend zeigt ein einfacher API-Test mit zwei Schritten dies beispielhaft anhand von zwei separaten URL-Anfragen. Untersuchen lässt sich hier anhand von Abschlussraten, ob die entsprechende API wie erwartet funktioniert.
Ebenfalls lässt sich ermitteln, ob die API langsamer arbeitet als erwartet. Hierzu werden die zugehörigen Transaktionszeiten erfasst und detailliert nach Prozessen wie DNS und SSL aufgeschlüsselt. Wie auch bei anderen Tests in ThousandEyes können die Szenarien für API-Monitoring zur Weitergabe als URL oder Sharelink gespeichert werden. Dies erleichtert es, bei Troubleshooting-Aktivitäten über mehrere Teams hinweg zusammenzuarbeiten oder etwa auch Provider miteinzubeziehen.
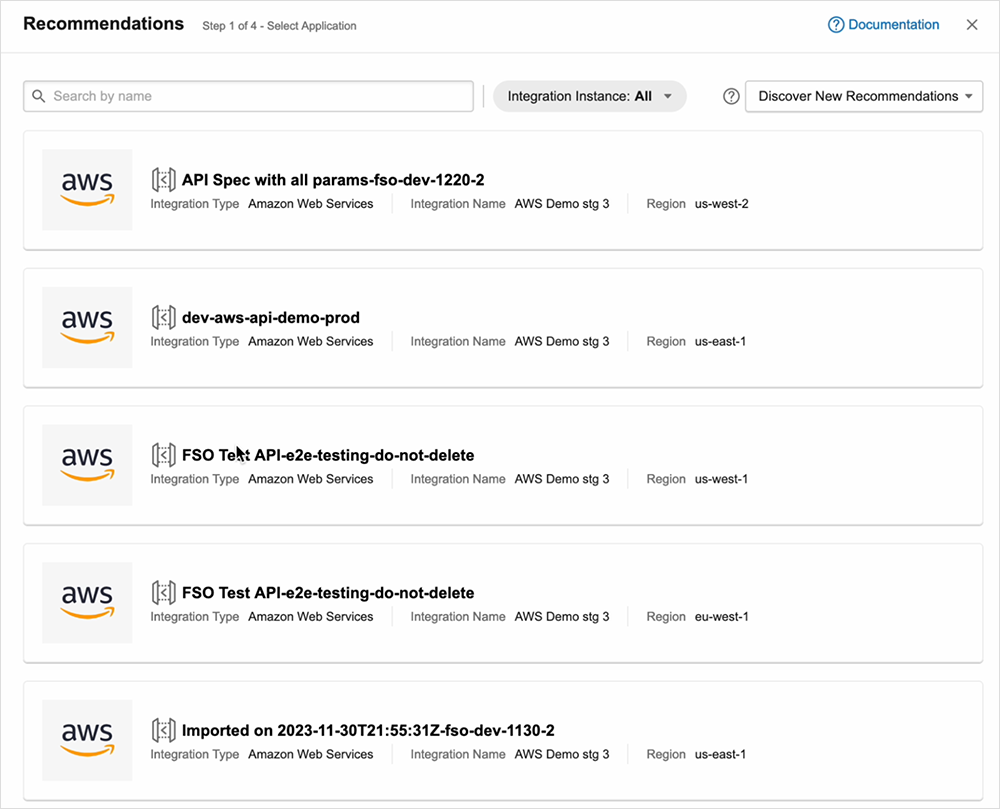
Eine weitere Neuerung sind Testempfehlungen für AWS API-Gateways. User erhalten damit ohne Umschweife Aufschluss über wichtige APIs, die in ihren Cloud-Umgebungen gehostet werden, und können direkt Tests für ihr Monitoring implementieren. Hierzu werden AWS API-Gateways automatisch über das AWS-Konto erfasst und auf Grundlage der aktiven API-Konfiguration die jeweils passenden Testszenarien vorgeschlagen.
Wichtige API-Endpoints werden automatisch ermittelt, ebenso wie die für die einzelnen APIs unterstützten Testmethoden sowie die erforderlichen Parameter und Header. Dies erleichtert es SRE- und ITOps-Teams enorm, umfassendes Monitoring wie auch die zugehörigen Tests zu automatisieren. Von der Erfassung von APIs, die in der Cloud gehostet werden, bis hin zur Implementierung von Testszenarien für ihr Monitoring erfolgt der gesamte Prozess damit komplett nahtlos.
Verbesserungen bei Testeinstellungen für Endpoint Agents
Auf der Seite „Test Settings“ (Testeinstellungen) steht nun ein Assistent zur Verfügung, mit dem sich die Einrichtung synthetischer Tests für ThousandEyes Endpoint Agents noch einfacher gestaltet. Monitoring für gängige SaaS-Applikationen kann damit anhand von Vorlagen eingerichtet werden, in denen alle nötigen Domains und Einstellungen bereits definiert sind. Ebenfalls beinhalten diese zertifizierten Vorlagen Best Practices, die User durch die optimale Testkonfiguration und Monitoring-Strategie für jede Applikation führen. Möglich ist dabei auch die Erstellung benutzerdefinierter Vorlagen für weitere Applikationen. So lässt sich ein Fundus eigener Konfigurationen anlegen, um schnell und einfach zusätzliche Tests durchzuführen.

Differenziertes Daten-Monitoring
Dashboard-Erweiterungen
Die Erfassung von Daten anhand der ThousandEyes Tests ist das eine. Doch erst durch Visualisierung dieser Metriken in Dashboards wird es Ops- und Service-Desk-Teams möglich, über verschiedene Standorte, Applikationen und User hinweg ein klares Bild über die Performance zu erhalten. Neben einer allgemeinen Übersicht können sie dabei auch spezifische Details zu einzelnen Usern oder Geräten einsehen und so potenzielle Probleme effizienter identifizieren und beheben. Anhand zwei neuer Features im ThousandEyes Dashboard gestaltet sich dies nun noch benutzerfreundlicher und besser skalierbar für größere Teams.
So werden jetzt weniger Schritte benötigt, um auf Testdaten aus beliebigen Widgets im Dashboard zuzugreifen. Ein Beispiel wären Performancemetriken, die auf Verlust oder Latenz hindeuten: Durch Klicken auf die entsprechenden Metriken erhalten User eine erweiterte Ansicht mit Details, etwa auch zu historischen Daten. In den neuen Multiservice-Ansichten lassen sich zudem Ergebnisse aus mehreren Dashboard-Widgets in einer einzelnen Seite zusammenführen. Dies liefert eine umfassende Sicht auf sämtliche Performancefaktoren, über die Zusammenhänge leichter erkennbar werden.
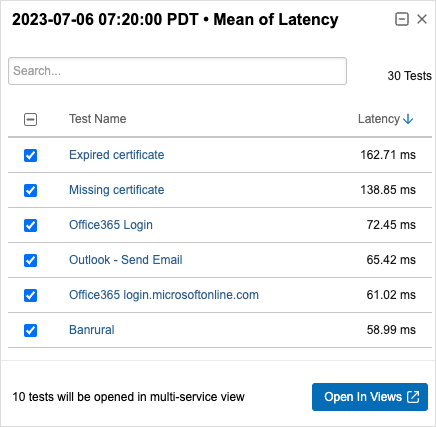
Zur Vereinfachung von Troubleshooting und Untersuchungen stehen Filter für das Dashboard zur Verfügung, anhand derer Admins flexible Datenansichten konfigurieren können. So können sie etwa ein Dashboard einrichten, in dem sich ein spezifischer Datenbestand zu einem Standort, einer User-Gruppe oder einem Service ausleuchten lässt. Speichern können sie diese Filterkonfigurationen ebenfalls, sodass sukzessive eine Bibliothek wichtiger Services entsteht, die einen schnellen Zugriff für Untersuchungen ermöglichen.