On Tuesday, December 7, 2021, multiple Amazon services and other services that rely on them were impacted by an outage event that in total, lasted more than 8 hours. The incident affected everything from home consumer appliances to various business services. Then, on Friday, December 10th, another ~hour-long ‘aftershock’ service disruption occurred, though to much less attention than the original Tuesday incident. While the goal of the Internet is to decentralize and make network services resilient, the heavy use of cloud services across all industries still reveals the fragility and increasing complexity of today’s digital ecosystem.
ThousandEyes observed the entirety of both incidents, the first of which occurred over two overlapping phases, each with slightly different characteristics. The first phase of the December 7th outage began at approximately 15:35 UTC (7:35 am PT), when multiple Amazon sites and services began to show significant performance degradation. While site loading appeared to mostly normalize by 16:50 UTC (8:50 am PT), soon after, ThousandEyes observed AWS API service failures that caused API transactions to experience dramatically higher completion times or simply time out.
The impact of this second wave of the Tuesday outage lasted for over 7 hours, not fully resolving until approximately 0:44 UTC (4:44 pm PT). Then, on Friday, December 10th, yet another large scale outage impacted various AWS services, with AWS servers returning errors for over an hour. In this post, we’ll unpack both phases of the initial incident plus take a look at the separate December 10th incident, and highlight critical lessons that can help organizations have better outcomes when the next, inevitable outage comes their way.
December 7, 15:32 UTC – The Outage Begins
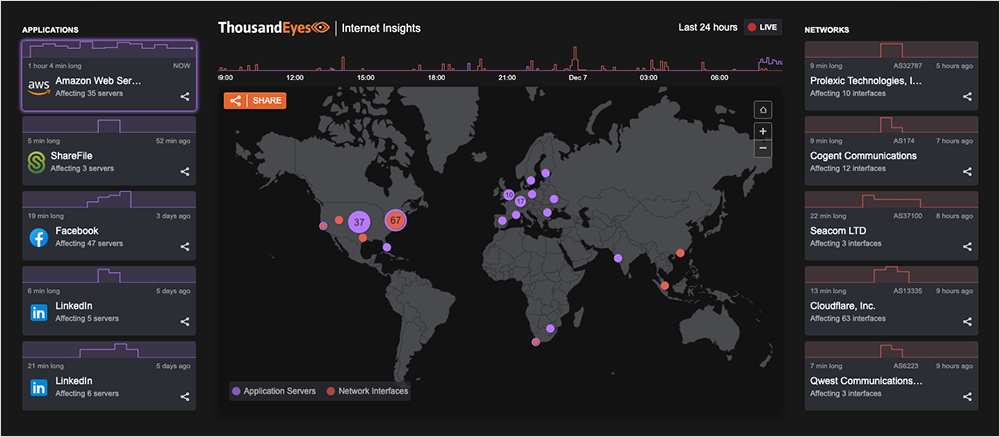
By about 15:40 UTC, within minutes of the start of the outage, it was clear that something big was happening within AWS. ThousandEyes alerts were coming in across many different Amazon sites and services, and our real-time Internet Outage Map was blinking big purple circles where AWS web servers were failing to respond to users.
At the same time, Internet Insights, which aggregates application and network telemetry from vantage points all over the globe, was reporting a significant outage event, impacting users in many different countries and regions.
The issue preventing availability of the various impacted sites appeared to be internal to AWS, which was further validated by looking more closely at tests to AWS sites, which confirmed time outs and service unavailable responses.
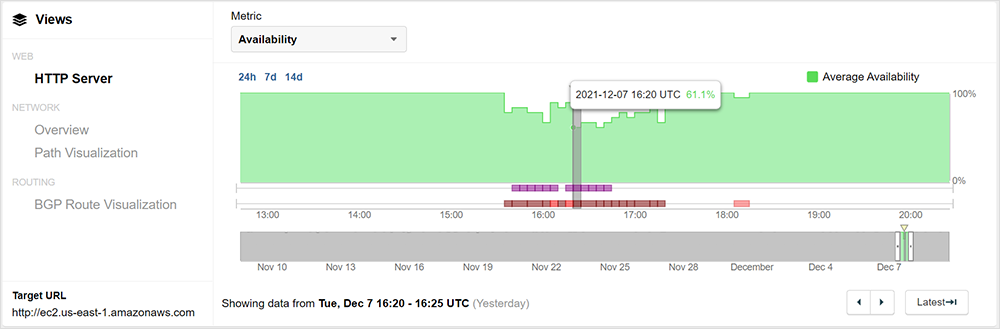
In the example below, Amazon’s Elastic Compute Cloud (EC2) service in their US-EAST-1 region shows timeouts starting at 15:35 UTC.
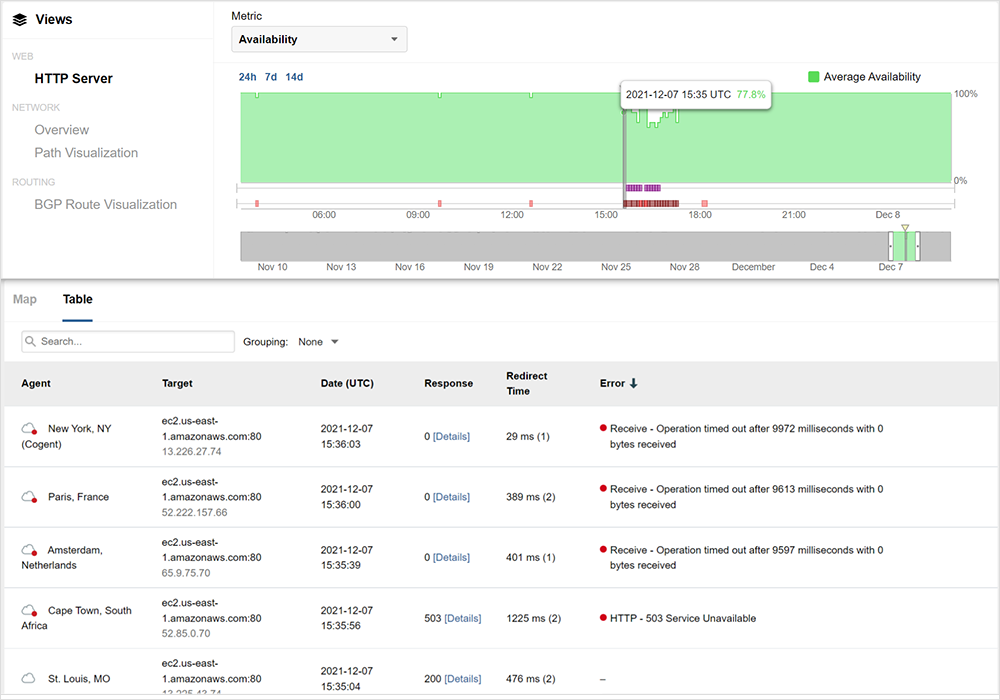
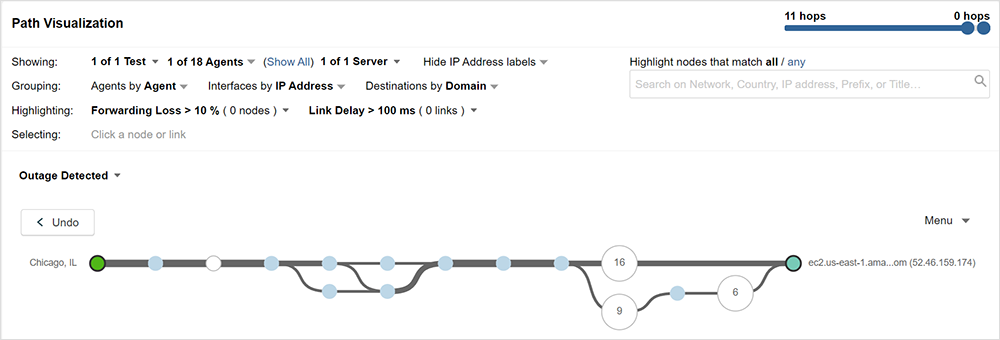
The 503 response shown in figure 3 is a status code provided by the web server (or a proxy on its behalf) to indicate that the web server cannot handle your request at the moment. The good news about this status code is that if you received it, your network traffic is reaching the destination web server and it is functioning enough to send this response. The bad news is that there’s little you can do to affect this outcome beyond just retrying. These errors indicate that the problem is not on the network path between source and destination. That is also evident when looking at the network paths to AWS, which at the time of the outage were healthy, with no increase in packet loss or latency, as seen in figure 3, between a vantage point in Chicago and EC2.
Interestingly, not all users experienced a similar impact across AWS sites. Even at the height of impact, there was still a 61% success rate for EC2 in US-EAST-1, with many users able to reach the service as usual.
However, other sites, such as AWS console, were more broadly impacted, with most users experiencing significant performance issues, including failure to load the site.
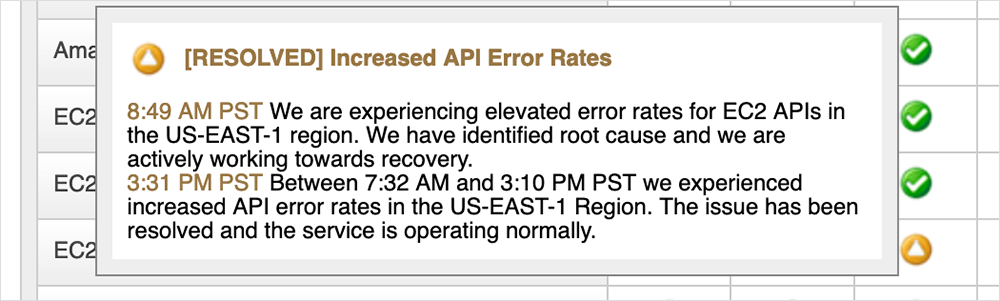
Overall, the first phase of the outage was that of a degraded condition, rather than a “hard down”. In a status update released later that day, Amazon confirmed that an increase in API error rates in US-EAST-1 impacting multiple services, including EC2, DynamoDB, Connect, and others, were behind the issues that morning, which aligns with the degraded conditions seen above. Figure 5 shows an update at 23:31 UTC (3:31 pm PT) that acknowledges the start of the issue to be 15:32 UTC (7:32 am PT). The issue was also said to persist until later that afternoon, although the most severe effects for users connecting to the front door of many AWS sites largely dissipated by 17:00 UTC.
Why would an increase in API error rates cause such widespread impact across AWS? To understand this, it’s helpful to understand the role of APIs, in particular within an environment such as AWS.
The Role of APIs in Service Health
APIs are not a new idea, and in fact have been around for decades. APIs enable different applications to talk to one another, exchanging data, triggering additional actions to occur. They ultimately facilitate an enhanced and more comprehensive and flexible set of solutions for users, customers, and partners of digital services. When we use cloud services, we are not using one application but rather many smaller applications working in concert. APIs therefore provide the essential gateways between many diverse, specialized applications.
Today however, the argument can be made that APIs are more critical than in times past. With cloud-delivered services, core functionality of applications often will not work when even one API of a dependent service is unavailable. Cloud separates the individual pieces of infrastructure and software into specialized apps, to handle things such as storage, compute, database, security, network, web, load balancing, and everything else. In other words, a bigger solution is split into various individual software pieces, which now require APIs to stitch everything together into a seamless solution.
Monitoring each service API and ensuring that you’re catching any granular degradation of the individual pieces is of the utmost importance in guaranteeing the performance and availability of these complex applications that we all rely on today.
So clearly API health is critical to the functioning of a service and if invokes to backend systems are seeing errors and higher latency, this degradation is likely to carry over to users, as is evident in the above examples.
December 7, 17:02 UTC – The Outage Continues
At about 17:00 UTC, services leveraging AWS API Gateway began to experience notable latency spikes, timeouts and errors.
Looking at a ThousandEyes API test configured to talk to an API endpoint leveraging AWS’ API Gateway, we can see that beginning at approximately 17:12 UTC, AWS API transaction times suddenly jumped from a healthy half a second or so to a response time of over 3 seconds. As Amazon explains, the AWS API Gateways “act as the "front door" for applications to access data, business logic, or functionality from your backend services.” Put more simply, the API Gateway is your entry point for nearly everything you do when interacting with the Amazon Cloud for your cloud-hosted applications.
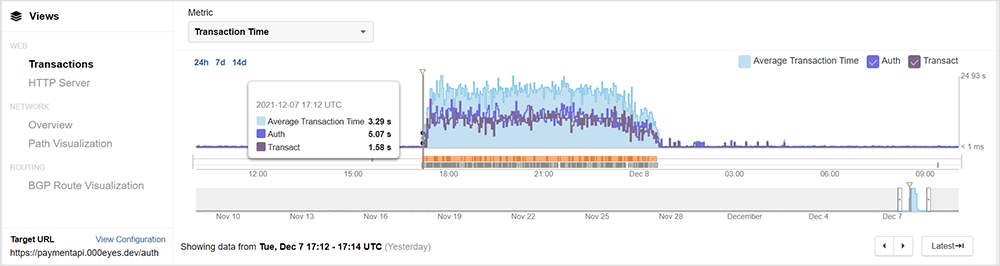
Jumping ahead to the midst of the outage, response times worsened and timeouts increased.
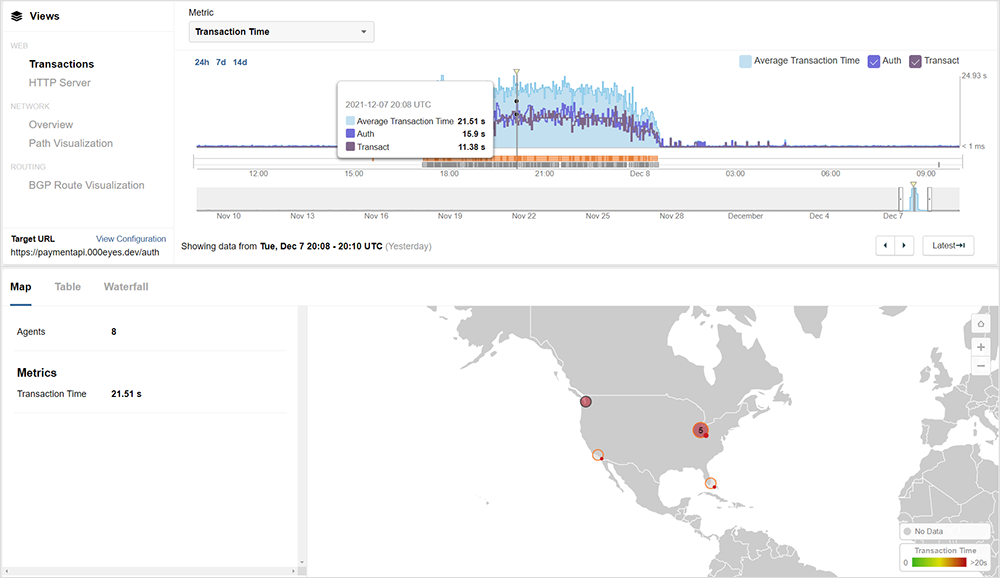
Once again, packet loss to the API endpoint did not appear to be a cause. While intermittently we saw some loss, it did not correlate to the problem and in fact there was none at all at the peak of the outage. We also saw healthy latency and jitter metrics, which corresponds with what Amazon ultimately reported, specifically that the issue was due to impaired performance of their API Gateway service in US-EAST-1.
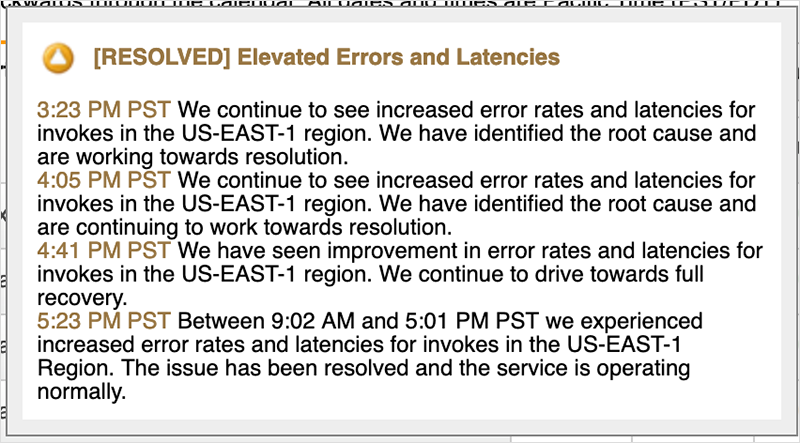
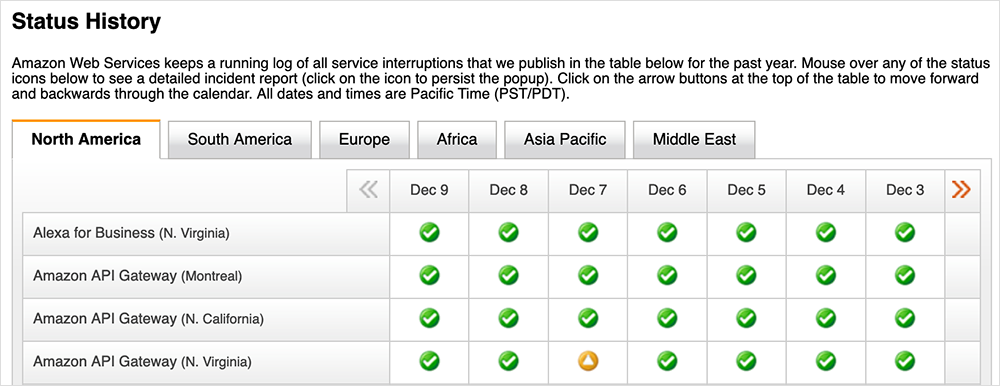
By around 01:00 UTC on December 8 services were essentially back in business and things were returning to normal. Everything was once again a healthy green.
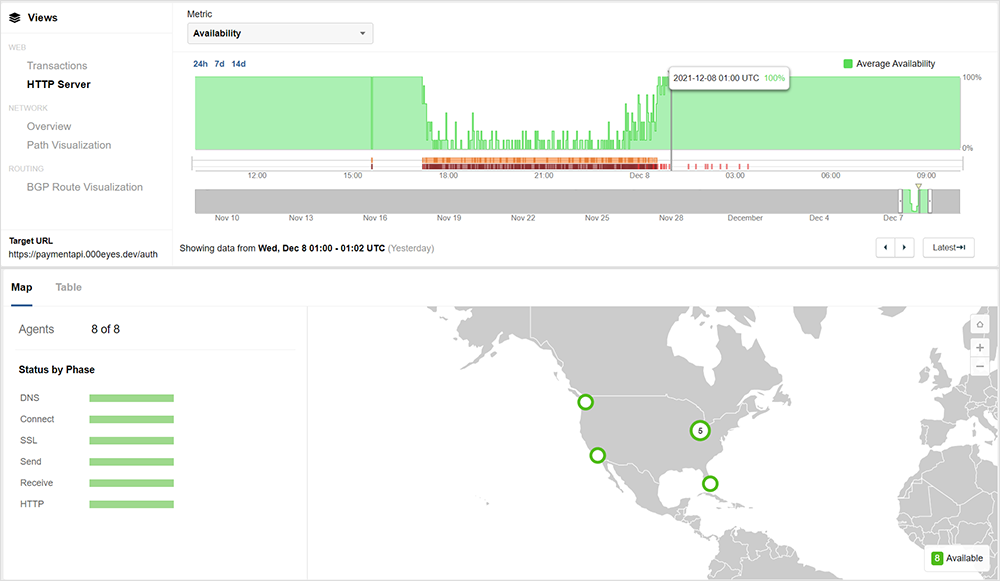
December 10, 13:05 UTC – Outage Aftershock
While all was well in the immediate aftermath of the incident, with December 8th and 9th fairly quiet, on early December 10th another major AWS incident caused significant disruption to multiple services. Once again, ThousandEyes observed the incident and its scope, showing the incident begin at approximately 13:05 UTC and lasting more than an hour before resolving at approximately 14:30 UTC.
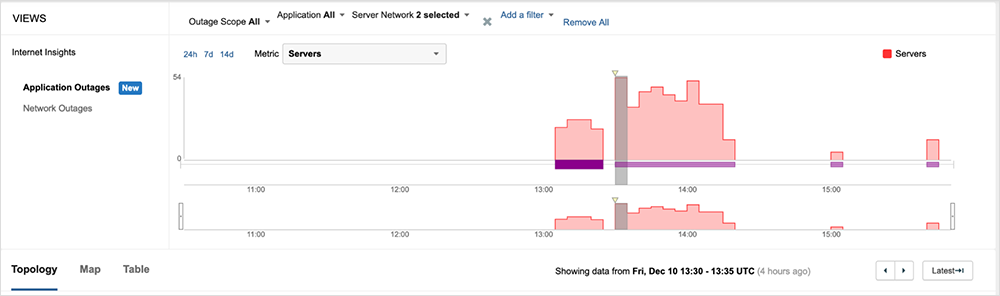
During the incident, service availability appeared to briefly return, before again failing, with AWS servers returning 500 server errors, as seen in the figure below.
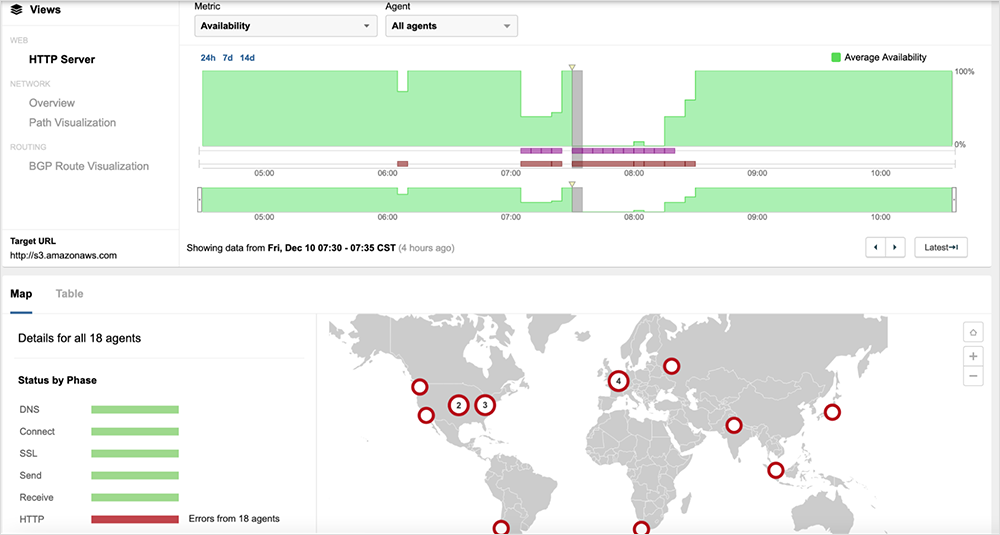
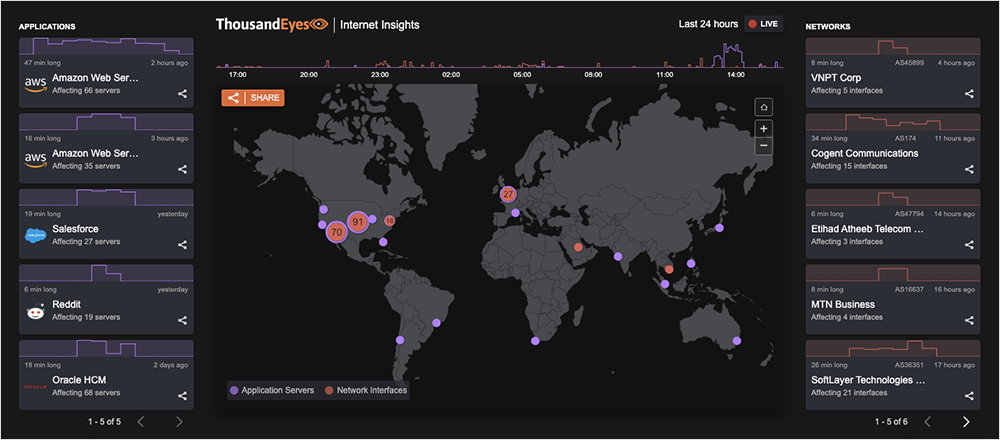
While ThousandEyes customers can see how the latest outage impacts their own environments, the free ThousandEyes Internet Outages Map also caught this incident:
AWS status page
Early in the December 7th outage, many users were taking to social media, and media reports began to emerge of a major AWS incident. Teams responsible for impacted services were deep in investigation mode, seeking the source of the issue – was it internal, an ISP, further into the Internet, or with Amazon? For nearly an hour, the AWS status page showed no issue with any AWS service.
The first acknowledgement of the issue was posted at approximately 16:40 UTC, over an hour after the onset of the incident. Now, the reality is that operators of large scale services will be focused on identifying and resolving incidents that emerge, and a cogent statement on the impact and scale of an incident can be difficult to produce while identification and remediation efforts are underway. Subsequently, status pages may take time to be updated to reflect issues. Which is all the more reason why visibility that is external to the service is critical to getting timely understanding that can prevent wasted troubleshooting and enable operations teams to take steps to avoid further impact on their own services.
A Web of Interdependencies
One of the founding principles of the early Internet design was decentralization – by design, a single fault would not be able to take out everything. In a way, today’s reliance on large cloud providers removes the benefits of decentralization; we rely on the scalability, cost effectiveness, and flexibility of today’s SaaS and Cloud offerings yet we are potentially putting all of our eggs into one basket. This same statement applies to CDNs, as seen with the recent Akamai outage from this past summer.
Yet we desire to not only use, but to expand our usage of these services. There’s a lot of benefit in the flexibility and power to deploy quickly that one gets with providers such as Amazon Web Services, Google Cloud Platform, or Microsoft Azure. And then there’s the benefits of SaaS offerings – not having to maintain the hardware, the software and updates, the network security, and all of the rigorous testing needed to run this stuff ourselves.
Furthermore, this complexity is not slowing down. Customer needs are continually evolving and the market is responding accordingly. Cloud deployments have most definitely changed the game, but also added this additional complexity. Now more than merely compute, storage, network, and security, Amazon Web Services lists an impressive 200+ different services as part of their cloud offering.Yet, we have within this architecture layers of dependency upon dependency. A failure in some fundamental service (especially at the network layer) can impact multiple other services, potentially resulting in a cascading failure with wide impacts.
Understanding the fault lines in your application architecture, factoring in resilience, and knowing early when you need to act, are all critical steps to ensuring that incidents such as this have less of an impact on your services.
Lessons and Takeaways
Where do we go from here? We are not giving up our reliance on, and enjoyment of, these cloud and SaaS solutions. The complexity is sure to not only continue but to continue expanding. Such complexity affects not just the ability of businesses to operate, but even touches the average consumer. This single internal disruption, in the example of Amazon’s reported event on December 7, prevented people from voice activating their smart home-enabled lights and even affected flight bookings and many other seemingly commonplace activities.
All of this speaks to the need for independent visibility and verification. In the analysis above, we clearly can see the scope of the incident — in real time — while updates from Amazon were slower to appear. We also could quickly attribute the issues to the AWS environment and understand which specific services were impacted. Ultimately, every team responsible for service assurance needs to know who to call to fix their problem (or what to do to fix it themselves) and validate when the problem has truly cleared. In other words – is it internal, an ISP, something beyond them but still on the Internet, or with the actual application or service itself? Full visibility, end-to-end, and at every layer, provides the insight needed to successfully operate the sites and services that we all need and enjoy.
[Dec 8, 11:15 am PT]
After AWS mitigated the cause of the outage, ThousandEyes began seeing full resolution between approximately 00:40 UTC and 00:50 UTC on December 8. Below we see that we have greatly improved numbers of successful HTTP responses at around 00:40 UTC.
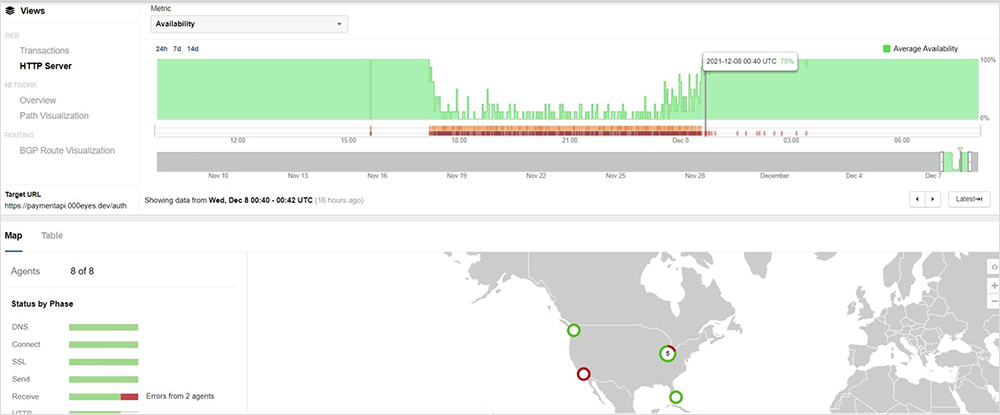
By 00:44 UTC, API transaction times have finally gotten back to times similar to those seen before the incident. While there were a few brief spikes in application response times beyond the 00:44 UTC mark, these later responses are still successful, within a healthy range, and the incident has cleared.
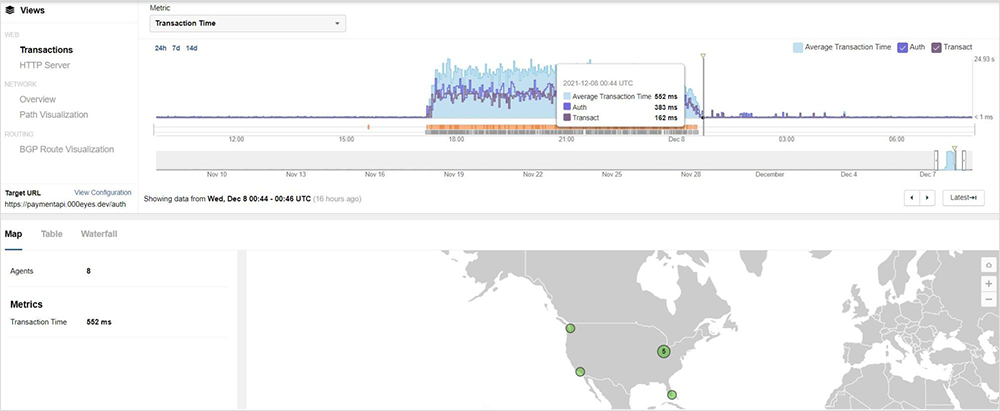
[Dec 7, 2:40 pm PT]
While the broad outage across many AWS services appeared to resolve at approximately 16:50 UTC, some services that rely on AWS APIs (including IAM API) continued to be impacted, and while availability appears to be increasing, issues persist as seen in below image.
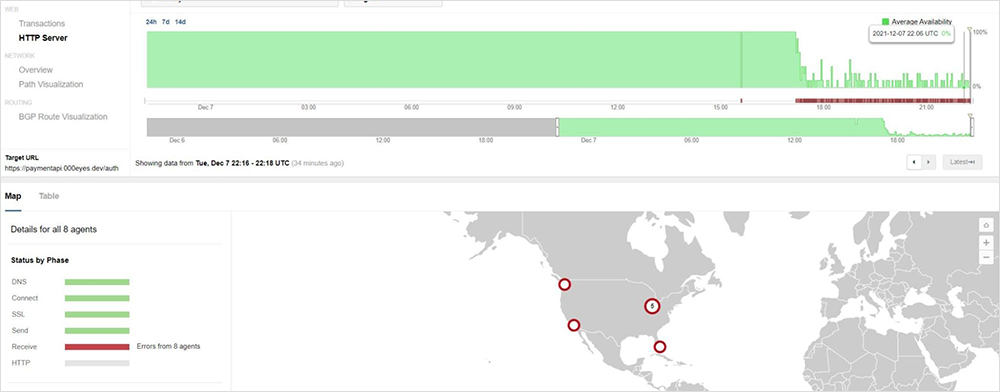
Corresponding with the HTTP timeouts, we see greatly increased transaction times of between 20-30 seconds, as well as transaction timeouts, as shown below.
Live link to view the AWS API service issue in ThousandEyes here. No login required.
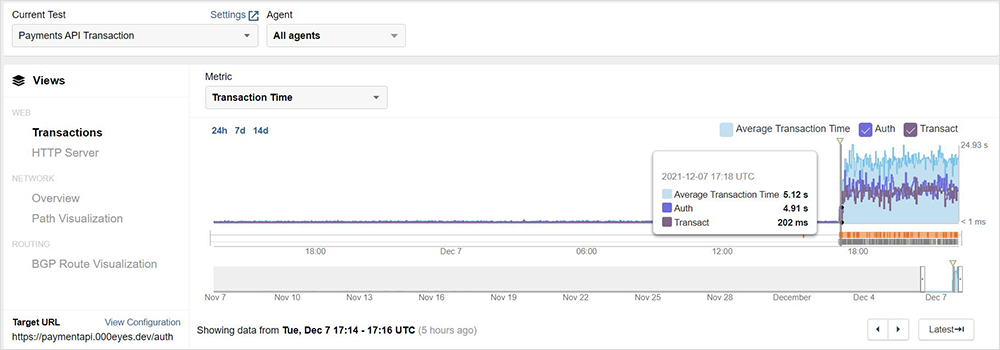
[Dec 7, 1:15 pm PT]
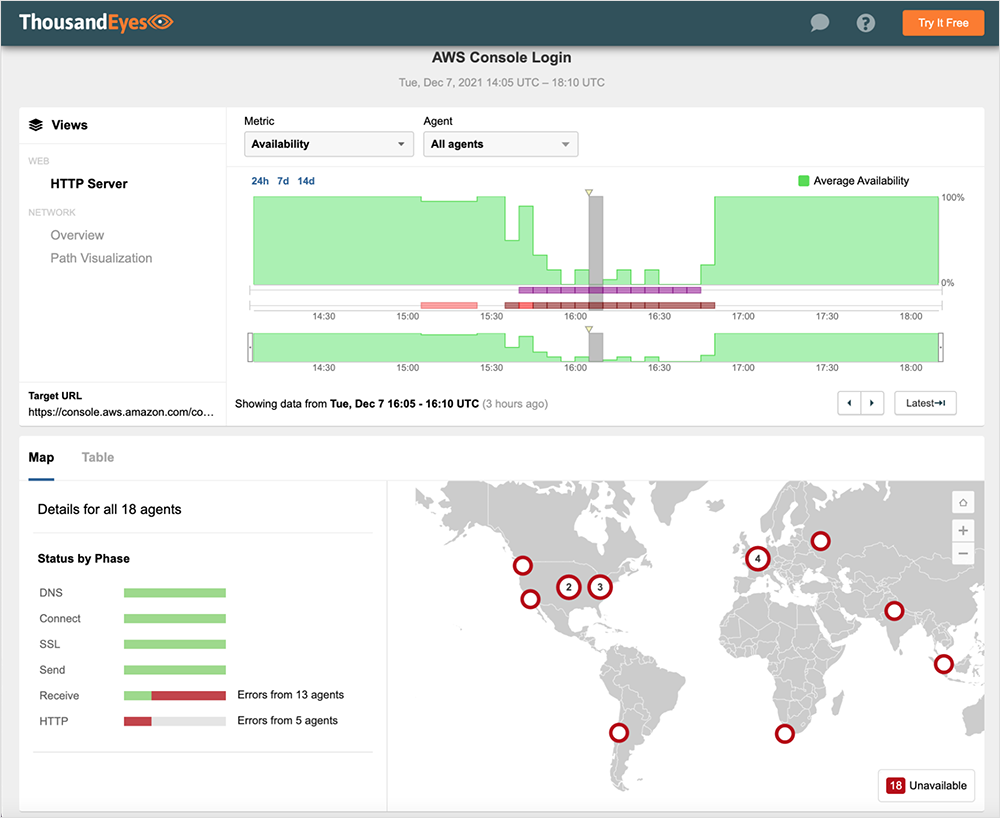
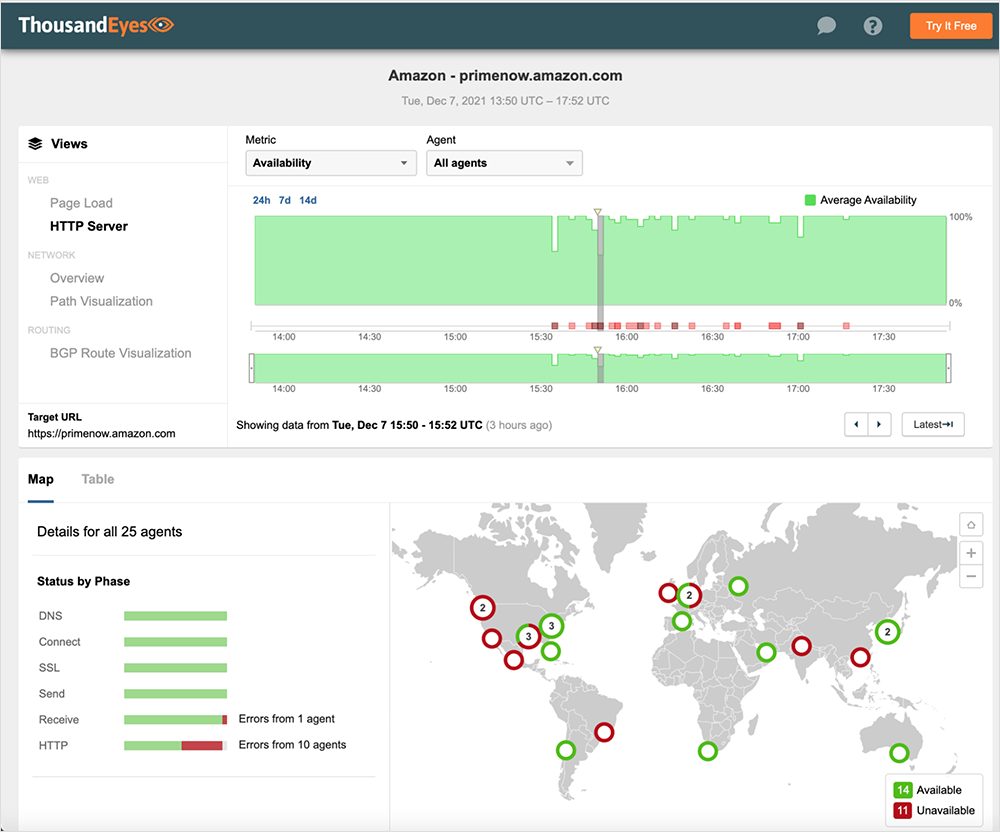
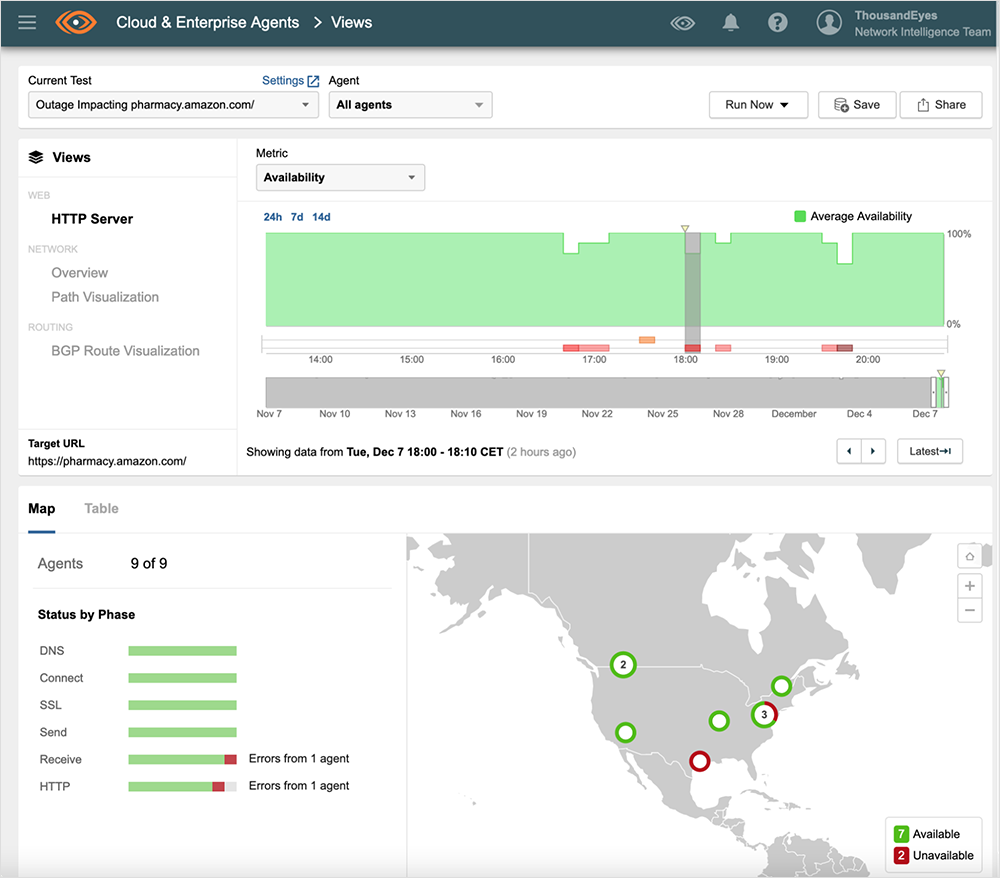
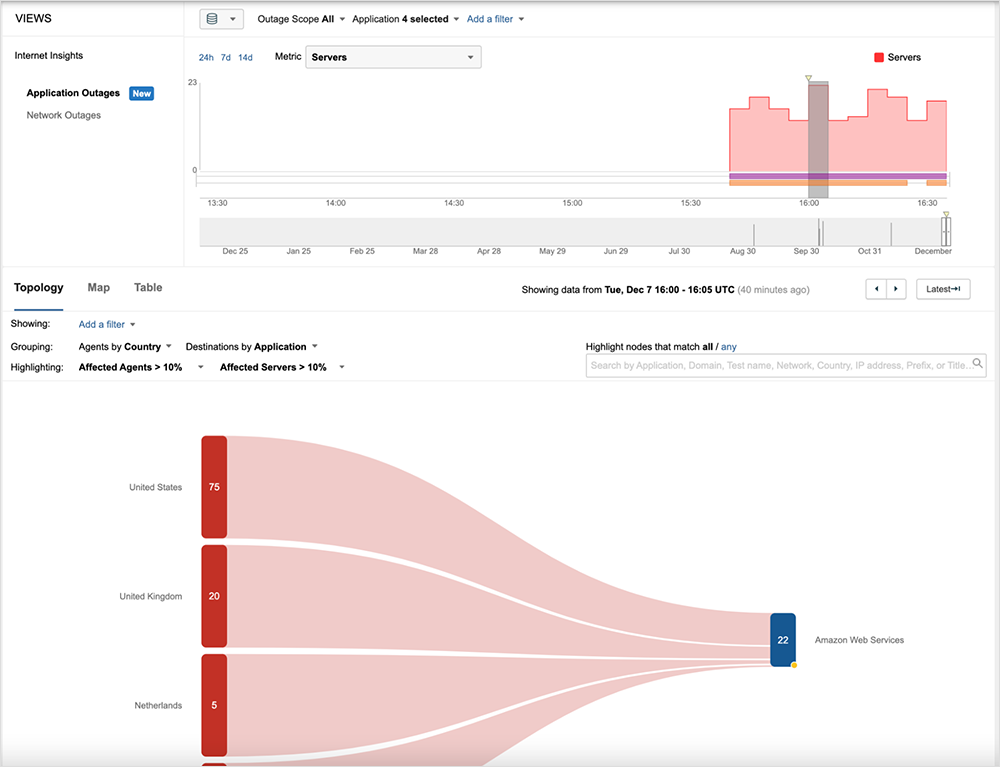
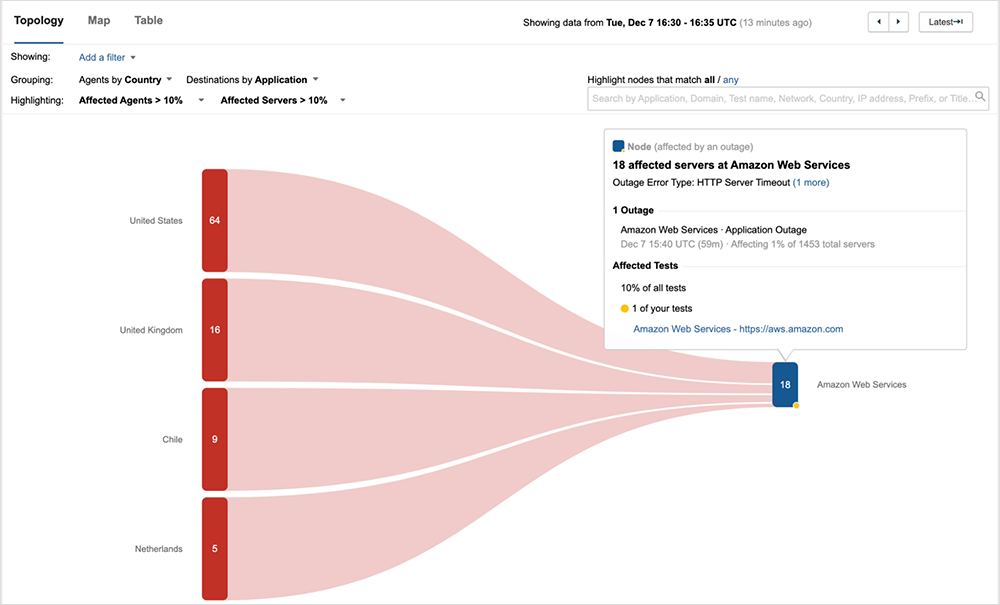
Several AWS services were impacted, including, but not limited to AWS Console, Amazon Prime Now, and Amazon Pharmacy. We also saw widespread impact to Amazon’s EC2 service across multiple regions, including in the U.S., Europe, and APJC, although the user impact varied depending on user IP address. Amazon’s S3 service also appeared to be impacted. Both of these services are dependencies for many non-Amazon apps and services, so collateral impacts may be broad. We will follow up shortly with further details on EC2 and S3 service impacts.
AWS Console
Live link to view the AWS Console outage in ThousandEyes here. No login required.
Amazon Prime Now
Live link to view the Amazon Prime Now outage in ThousandEyes here. No login required.
Amazon Pharmacy
Live link to view the Amazon Pharmacy outage in ThousandEyes here. No login required.
[Dec 7, 9:00 am PT]
[Dec 7, 8:45 am PT]
An Amazon Web Services outage started on Dec 7, 2021 at approximately 15:40 UTC and is ongoing, impacting users in various regions across the US and parts of Europe. Check out the live Internet outage map: www.thousandeyes.com/outages/