This is the Internet Report: Pulse Update, where we review and provide an analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read our full analysis below or tune in to our podcast for first-hand commentary.
Internet Outages & Trends
HTTP 403, 503, and 504 status codes dominated the last few weeks as multiple companies experienced application degradations and outages. These incidents at companies like Okta, Twitch, Reddit, and GitHub leave important lessons for IT teams on how to navigate similar issues and minimize downtime for users.
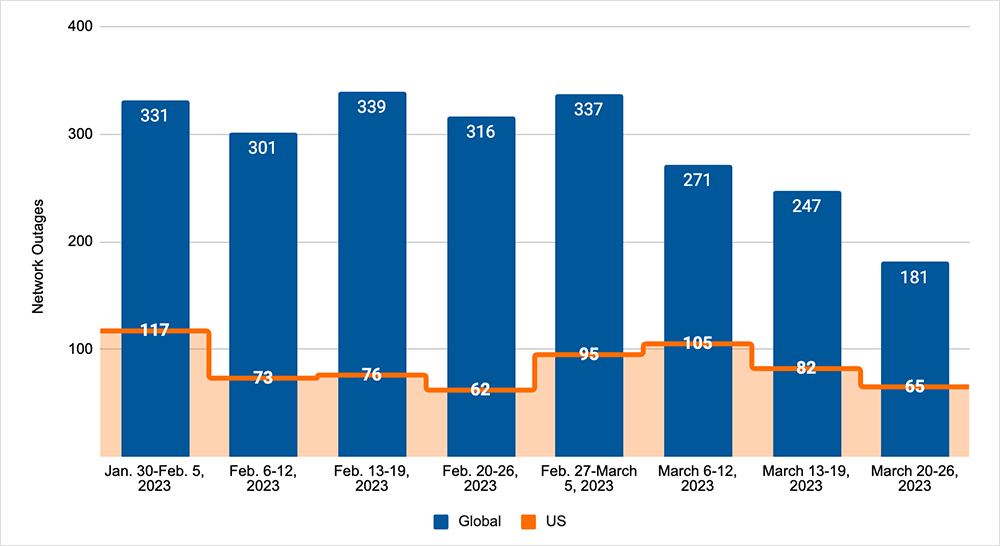
Looking at overall outage trends, we also saw global and U.S. outage numbers continue the downward trend seen over the previous two weeks, with global outages dropping 33% over the two-week period, and U.S. outages dropping 38%. U.S.-centric outages accounted for 34% of all observed outages. See the By the Numbers section below to learn more.
Read on for our analysis of these events and global outage trends, or use the links below to jump to the sections that most interest you.
Okta Disruption
On March 12, Okta users in some geographies, including North America, experienced problems accessing their corporate applications when Okta’s single sign-on (SSO) service encountered issues.
The problems initially manifested as 504 gateway timeout errors in one “cell” (Okta groups its public-facing infrastructure as a series of cells, isolated from one another). These issues were fixed after 30 minutes, but then the same cell—and others—started presenting 403 forbidden errors in response to user authentication requests.
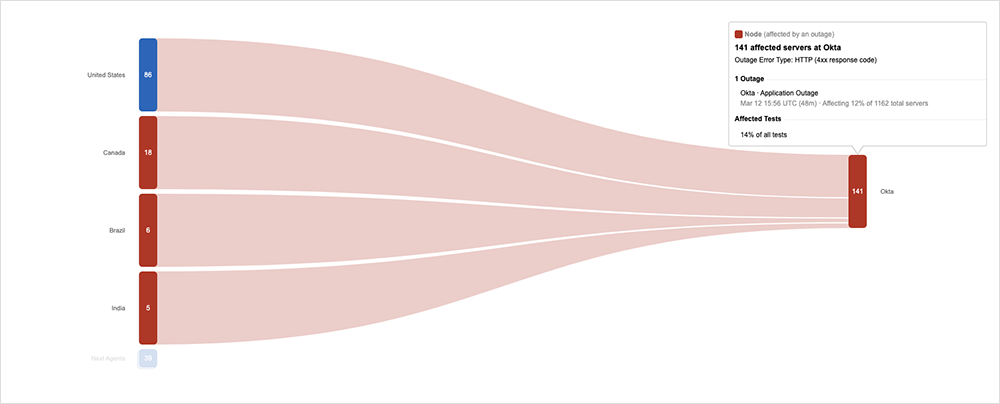
According to a post-incident report, a bug in Okta’s internal tooling prolonged the 403 issue. The bug caused network rules implemented as part of a fix to be “incorrectly set to block requests,” manifesting as 403s on the front end.
While users could still sign in and access their Okta dashboard, some visual elements of the application did not appear like they normally do, impacting the usability of the application. A subset of the application’s icons that are usually displayed on the page didn’t render properly. As a result, users didn’t have full access to some of the applications they normally use during their workday.
The disruption was officially categorized as a “service degradation,” not a full outage. The application remained available and accessible, even if it did not function fully as intended for a subset of users. In total, this 403 problem lasted for an hour, according to the post-incident report, which matched ThousandEyes’ observations.
Given the critical “front door” nature of the Okta service, the incident has given users—and Okta itself—some pause for thought on redundancy. A post in the Okta Developer Community forum notes that it’s possible “to run multiple authorization servers in the same organization,” which “could be used for failover if one authorization server went down”; although, this wasn’t the intended purpose of the capability.
More interestingly, Okta flagged the possibility of a future product enhancement to enable automatic failover between cells: “I think there is an interest[ing] product enhancement out of your question, which is how Okta could allow you to have the same organization in multiple cells, and if one goes down, we can elegantly funnel traffic to the other cell. It definitely seems feasible and would be a value-add for customers needing automatic failover and redundancy.”
Degradations and outages are often triggers for architectural rethinks. That certainly seems to be the case here—and enterprise users of Okta who were affected by this degradation will no doubt watch this space with interest.
Twitch Outage
On March 3, some Twitch users experienced issues accessing video-on-demand streams via the service. The issues, in Twitch’s words, “prevented some services from loading.” Impacted users would have been presented with a timeout and a black screen when trying to access streams.
The cause of the issues wasn’t publicized, and the incident wasn't acknowledged on the service’s official status page, making it hard to ascertain the root cause.
Reddit Outage
On March 14, starting at approximately 19:05 UTC, ThousandEyes observed an outage
impacting global users of Reddit, a popular online platform that’s home to thousands of communities. Network paths to Reddit’s web servers, hosted on CDN provider Fastly, were clear of issues and the site was reachable.
However, users experienced content loading issues and received HTTP 503 service unavailable errors, which indicate a backend or internal app problem.
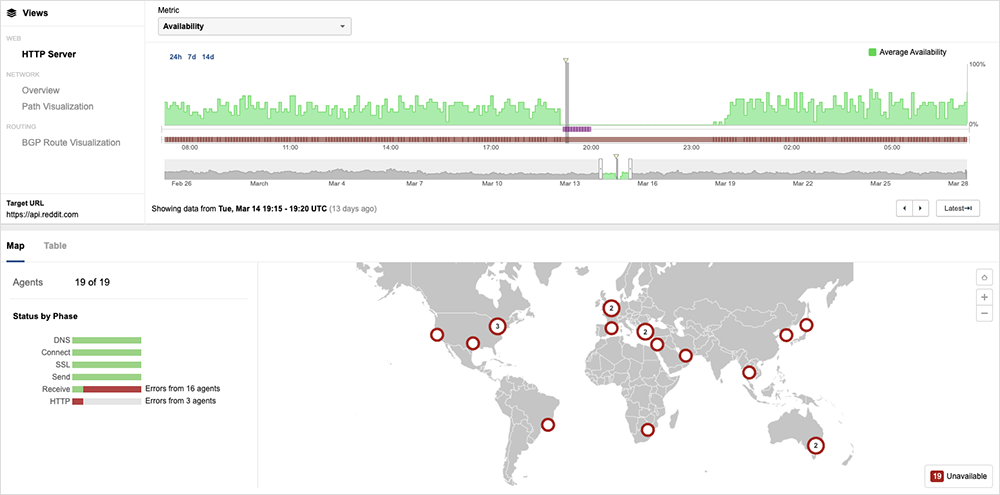
Reddit’s official status page recorded a total outage duration of five hours. Again, the nature of the root cause was not disclosed.
GitHub Outage
Finally, on March 15, GitHub users were presented with “5xx errors” when trying to use Actions, Packages, and Pages—GitHub’s platforms for CI/CD and for hosting and managing packages and websites, respectively.
The way the problems manifested caused some customers to initially hypothesize on social media that it was a cloud infrastructure outage. However, further inspection and problem tracing identified GitHub as the responsible party, once again highlighting the importance of having good independent visibility into complex cloud-native environments so your team can quickly discern the source of an issue and respond accordingly.
Unlike the Okta incident where users could still access the service to some extent, GitHub users were unable to reach the services altogether. GitHub confirmed that users’ requests were simply timing out. The outage lasted around 80 minutes, and while there’s no official explanation for what caused the problems, GitHub did provide regular status reports during the degradation and outage event.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (March 13 - March 26):
- Global outages continued the downward trend seen over the previous two weeks, dropping initially from 271 to 247, a 9% decrease when compared to March 6-12. This downward trend continued the next week with global outages dropping from 247 to 181, a 27% decrease compared to the previous week (see the graph below).
- This pattern was reflected in the U.S., with outages decreasing over the past two weeks. In the first week of this period, outages dropped from 105 to 82, a 22% decrease when compared to March 6-12. This was followed by another drop from 82 to 65 the next week, a 21% decrease.
- U.S.-centric outages accounted for 34% of all observed outages, which is slightly larger than the percentage observed on February 27 - March 5 and March 6-12, where they accounted for 33% of observed outages.