This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for firsthand commentary.



Internet Outages & Trends
Over a two-day period last week, Meta, Comcast, and LinkedIn all experienced different issues that had widespread impacts on users, services, and applications. Meta experienced issues with its log-in process, Comcast dealt with 100% packet loss in part of its backbone, and LinkedIn worked its way through a backend issue.
In today's digital era, network and digital service providers are required to frequently change their systems in order to maintain them, update their security, and promote business growth—along with a number of other reasons. However, making changes to a digital system is never risk-free. Even the most robust system can be vulnerable to disruptions and errors—and it only takes one element within the service delivery chain to fail for the complete functional performance of a service to be impaired.
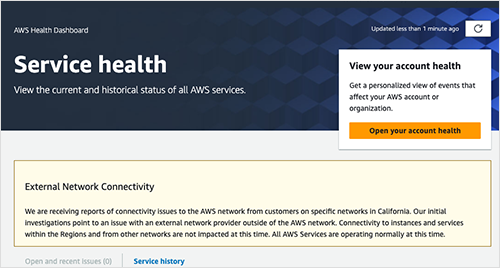
In this new reality, it’s important to have a full and independent view of end-to-end service delivery so that faults can be efficiently discovered and the responsible party can be identified. This allows the issue to be quickly resolved or an alternate workaround process to be executed. This was particularly important in the Comcast outage, which impacted the reachability of many applications and services, including Webex by Cisco, Salesforce, and Amazon Web Services (AWS). Without proper visibility into the end-to-end environment, some users initially suspected that AWS was the cause, prompting AWS to post a message on its status page suggesting that the issue was caused by an external network provider.
These recent outages emphasize the importance of having a backup solution and resiliency process in place should an outage occur—and ensuring the backup can scale to meet the sudden spike in demand.
Read on to learn about these incidents, as well as other recent disruptions at Discord and DIRECTV, or use the links below to jump to the sections that most interest you:
Meta’s Authentication Problems
On March 5, 2024, Meta experienced an unexpected interruption to some of its services, including Facebook, Instagram, Messenger, and Threads. While the services appeared to be reachable—displaying a basic login page with company branding—many users reported that they couldn’t see or access anything beyond that.
According to reports, some Facebook users initially experienced login issues. When users tried to re-enter their credentials, the site reportedly declared their correct password as “invalid.” Meanwhile, some Instagram users weren’t able to refresh their feeds at all, according to reports.
Anecdotal user posts on several forums suggest that impacted users responded to the disruption in different ways. One Facebook user, for instance, suspected that their credentials had been compromised, causing them to attempt to reset their passwords and consider running a device scan to check for the presence of malware. Likewise, some Instagram users may have tried to mitigate the issue by uninstalling and reinstalling the app or rebooting their devices because they believed the issue lay with the handset or data network.
At around 3:17 PM (UTC) (7:17 AM [PST]), Meta confirmed that it was experiencing issues with its login services. The problem was likely caused by a failure in one of the dependencies that the login system relies on. Authentication is a crucial step in accessing a service. A failure at this step can impact the entire application delivery chain, causing major disruptions for users.
ThousandEyes observed a gradual recovery of impacted Meta services from 4:50 PM (UTC), and the majority of regions were able to access the services by 6:40 PM (UTC). At 7:27 PM (UTC), Meta officially announced that the issue was fully resolved.
Comcast Outage Impacts Many Apps and Services
On March 5, at approximately 7:45 PM (UTC) (11:45 AM [PST]), ThousandEyes began observing outage conditions in parts of Comcast’s network, which impacted the reachability of many applications and services, including AWS, Salesforce, and Webex by Cisco.
According to ThousandEyes’ analysis of the incident, the outage appears to have impacted traffic as it traversed Comcast’s network backbone in Texas, including traffic that originated in other regions like California and Colorado. The onset was sudden. Traffic traversing the affected infrastructure saw an immediate drop off—100% packet loss—with no apparent ramp that might indicate congestion or other stress conditions in the network.
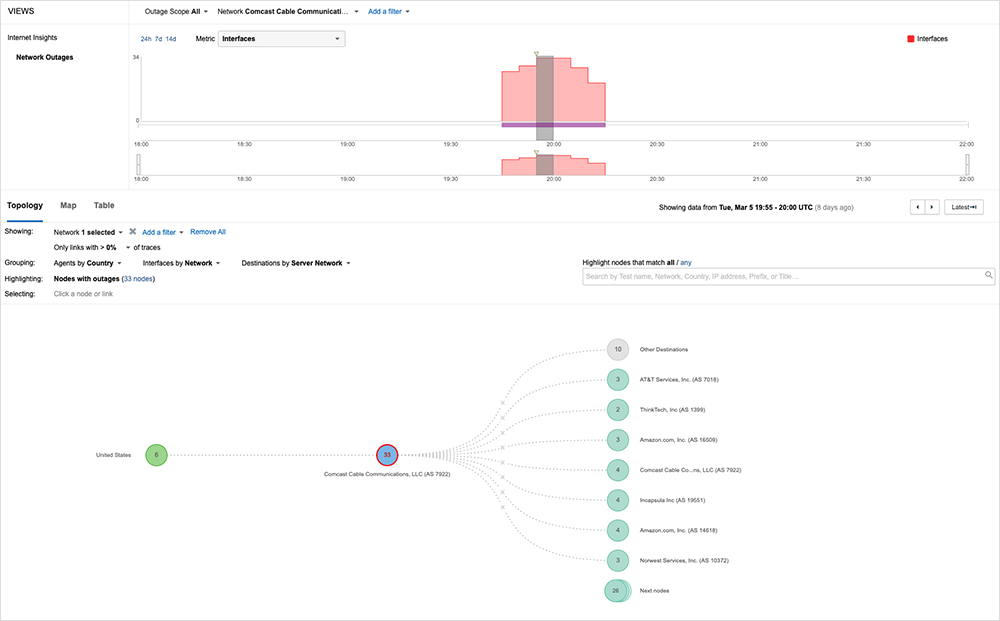
Comcast's network is architected in a hierarchical structure, with different regions having a semi-autonomous design. End users connect to aggregation routers (ARs), while external networks connect through PE routers. The spine routers (CS) handle all traffic, and the core routers (CR) provide connectivity between each of Comcast's regional networks. The CR routers sit at the top of the hierarchy.
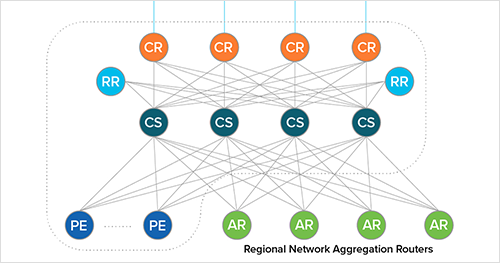
Comcast's network is likely designed with redundancy measures in place to ensure traffic automatically fails over to alternate paths in case of an issue affecting a portion of the network. Although the Houston PoP was not entirely incapacitated, my guess is that Comcast could potentially have used other paths between the U.S. East and West regions to route around the Houston portion of the network. However, it remains unclear why this failed to happen in this case.
During the outage, only certain services that required traversal across Comcast's backbone were impacted. This led to reports of issues reaching specific applications, leading to the initial conclusion that multiple services were experiencing simultaneous outages. For example, the Webex collaboration service was mistakenly assumed to be down due to how it's architected. Salesforce was also impacted, and its users also connect to a specific data center where their instance is hosted.
Figure 5 shows that traffic to Salesforce originating in Dallas, Texas, was subsequently dropped in Houston. Only minutes before the incident, connectivity to Salesforce was functioning as expected. Traffic was successfully routed through the Houston, Washington D.C., and Virginia portions of Comcast’s network before being handed off to the Salesforce NA35 data center in Virginia.
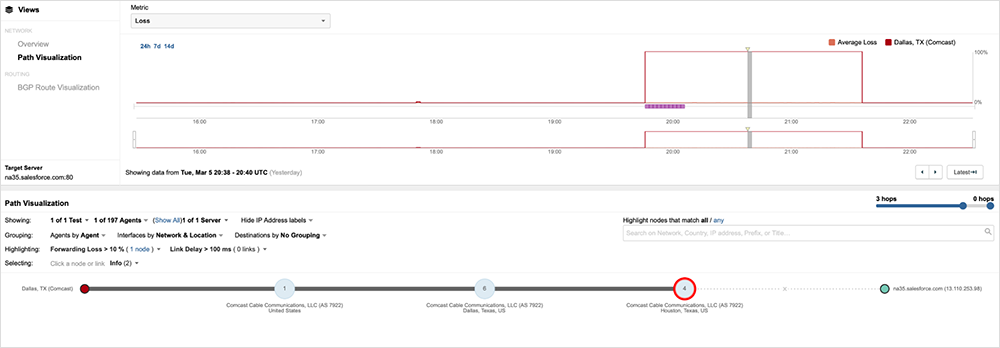
Explore this outage in the ThousandEyes platform (no login required).
Some Breathing Space, and Then LinkedIn Down
The day after the Meta and Comcast outages, LinkedIn experienced an outage lasting just over an hour. Users globally reported encountering service unavailable error messages.
ThousandEyes’ observations of this March 6 incident and recovery show that no apparent network issues should have caused the problems, suggesting that either something failed in LinkedIn’s backend or that key infrastructure required a restart in order to recover services.
ThousandEyes initially observed timeout errors at the origin, which suggests that a session could not be established with the backend service.
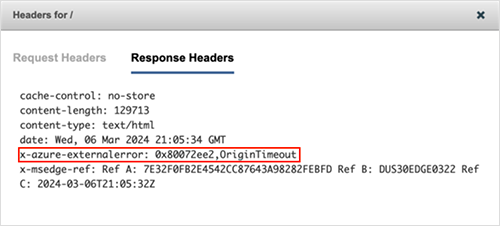
As the outage progressed, ThousandEyes tests returned HTTP 503 service unavailable messages (server-side errors that the backend service is unavailable or not ready to handle the request). During the recovery, ThousandEyes observed tests returning HTTP 502 bad gateway messages (where the origin could not understand or process the user’s request). This sometimes indicates system load issues as a service is being restarted or restored.
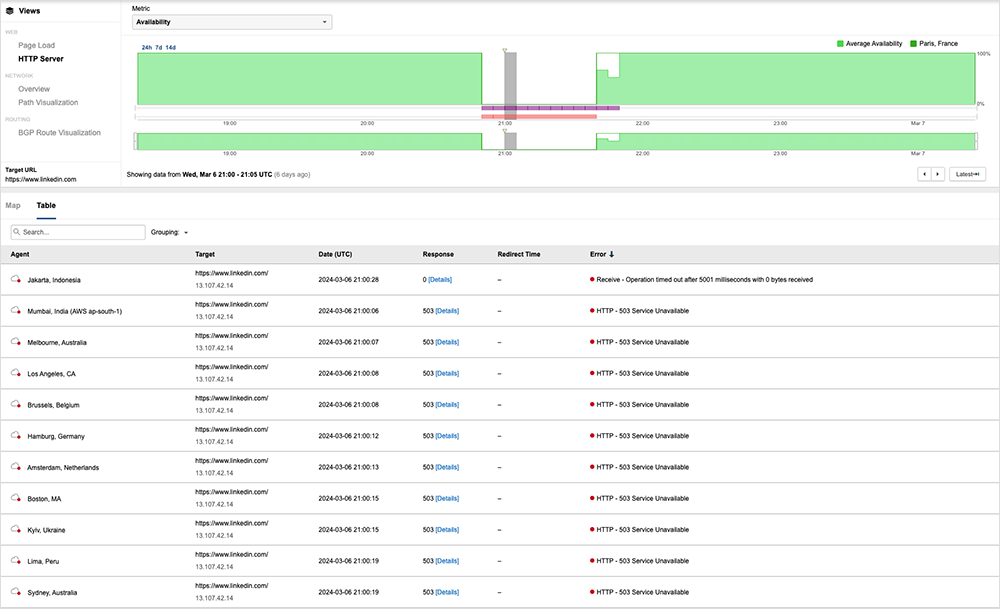
Explore this outage in the ThousandEyes platform (no login required).
Discord Encounters Load-related Issues
During the same two-day timeframe in which Meta, Comcast, and LinkedIn were impacted by outages, Discord also encountered a disruption. On March 5, Discord began experiencing issues that prevented some users from loading “guilds” (servers) and from starting new sessions. According to the company’s status update, an internal rate limit was being triggered. A temporary bypass allowed pending sessions to start. Then, four minutes later, the company said it was “scaling up an internal service” to meet the “influx of guild load requests.”
The issues were resolved after 34 minutes. In a subsequent update, Discord said it would be “reviewing the updated rate limiting that triggered the initial session start issues, as well as the scaling targets for the internal service which limited guild loading during initial recovery.”
DIRECTV Experiences Service Disruption
Satellite television provider DIRECTV recently experienced a “lengthy” service disruption due to a “satellite positioning issue,” where a geostationary satellite drifted out of range and its signals could no longer be picked up. The company went on to describe the root cause of the drift as an unspecified “space event” that required the satellite to be repositioned in order to restore subscriber access.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (February 26 - March 10):
-
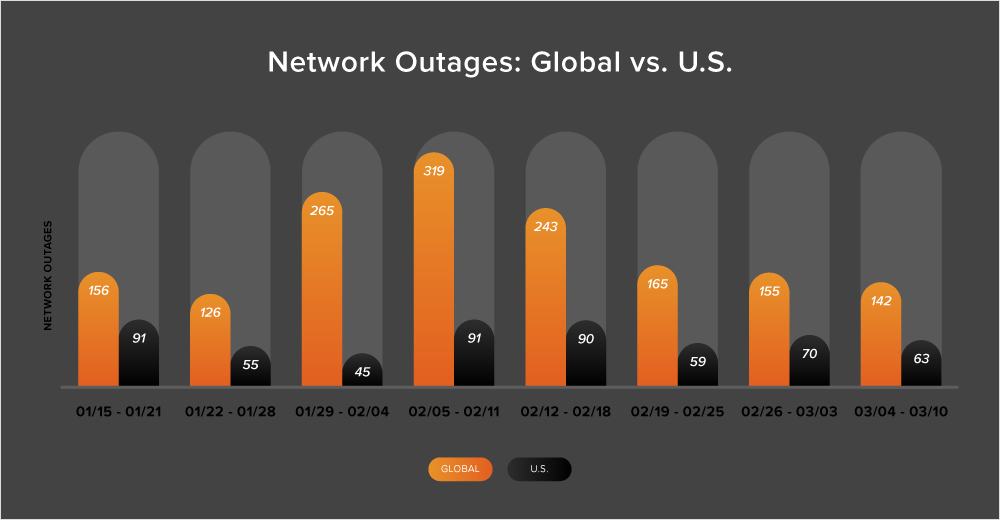
During the last week of February and into March, the total number of global outages continued to decrease. The downward trend that was observed during the previous two weeks persisted throughout this next period. From February 26 to March 3, the number of outages dropped from 165 to 155, a 6% decrease. The following week (March 4-10) saw a further decrease of 8%.
-
However, outages behaved slightly differently in the United States, initially increasing from 59 to 70—an 18% rise compared to the previous week, before decreasing by 10% the following week (March 4-10).
-
Between February 26 and March 10, almost half of all recorded outages (45%) were observed in the United States. This marks a return to the longstanding trend of more than 40% of all outages being U.S.-centric. The reason for this shift can be attributed to the decrease in global outages, which has resulted in a more significant proportion of U.S.-based outages.
-
In terms of monthly trends, the number of global outages in February was 1001, a 53% increase compared to the 653 outages of the previous month. Similarly, the United States also saw an increase in outages from 284 to 314, an 11% rise.