This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
As one year comes to a close and another begins, network teams face a challenging season. While it may seem like a good time to make alterations to the network (as it tends to be a quieter period for some teams), it’s also a season when the Internet sees large spikes in demand for services, especially during the holidays when people are at home more and looking for entertainment. With many workers out of the office, my experience is that this period also coincides with reduced staffing levels at many organizations. This can sometimes lead to unusual or unexpected conditions for IT, resulting from configuration changes, upgrades, or non-typical loads and requirements.
In keeping with this trend, the first two weeks of 2024 brought outages that, in my opinion, may not have happened in another season.
For example, just after the new year began, a major mobile network operator—Orange Spain—had its RIPE account compromised. Although security-related incidents cause outages throughout the year, I’d imagine that the holiday and early new year period could be a particularly tempting time for hackers as many teams are on vacation or just ramping up after the holiday season. However, it must be noted that while security-related outages are often caused with malicious intent, this Orange incident seemed more meddlesome than anything. The impact appeared to be largely confined to the operator’s own customers; Internet infrastructure detected the incident and routed around the problems.
The ramp-up period at the start of the new year can also create an ideal environment for oversights, such as an unnoticed configuration change, to happen accidentally. During the first two weeks of the new year, there were two high-profile incidents: DigitalOcean and OpenAI both experienced issues after 20:00 UTC and into the night—timing that is usually reserved for planned upgrades or maintenance work.
Read on to learn about these recent outages and disruptions, or use the links below to jump to the sections that most interest you:
Hack Leads to Orange Spain Outage
Customers of Orange Spain experienced degraded services on January 3 after the carrier’s RIPE account appeared to be breached, resulting in the alteration of its Route Origin Authorizations (ROAs). In Internet infrastructure, the ROA “states which autonomous system (AS) is authorized to originate a particular IP address prefix or set of prefixes.”
According to reports, the hacker announced Orange’s prefixes as different autonomous systems. As a result, some BGP paths were invalid, which resulted in packet forwarding loss. In other words, traffic that reached the erroneous AS essentially dropped into a “black hole.”
Describing the incident as a “hijacking” doesn’t align with accepted Internet industry terminology. The term “hijack” is generally associated with a BGP or route hijack, where traffic is maliciously diverted to another network where it can be intercepted or otherwise accessed. In this incident, my best guess is that the hacker appeared to have less interest in Orange Spain’s Internet traffic; their actions seemed more akin to a disruptive denial of service (DoS) nature, causing connections to break but not much beyond that.
One important point to note about this incident is that its impact on the Internet was relatively short-lived for some prefixes. During the incident, ThousandEyes observed 100% packet loss on Madrid-based peers, but the issue was quickly resolved, and traffic was essentially redirected around the problem. While users of Orange Spain may have experienced slow or laggy mobile data services for a few hours, anyone whose traffic normally went through the Orange backbone was likely not affected once the traffic was rerouted. According to ThousandEyes data, the issue was fully resolved when Orange restored its ROAs.

Two Consecutive Service Degradations at ChatGPT
On January 11, OpenAI’s ChatGPT experienced two “service degradation” issues, one after the other. The first incident—color-coded red on their status page’s traffic light system—began at 4:41 AM (UTC) and took until 8:19 AM (UTC) to resolve. A second “service degradation,” color-coded yellow, was then experienced between 9:30 AM and 10:19 AM (UTC). It’s not clear if the two incidents were related.
According to ThousandEyes analysis, the degradations caused slow page load times but did not render the ChatGPT service completely unusable. This indicates that the service was reachable, but my best guess is that there may have been a backend issue, such as a configuration problem or resource constraint, present.
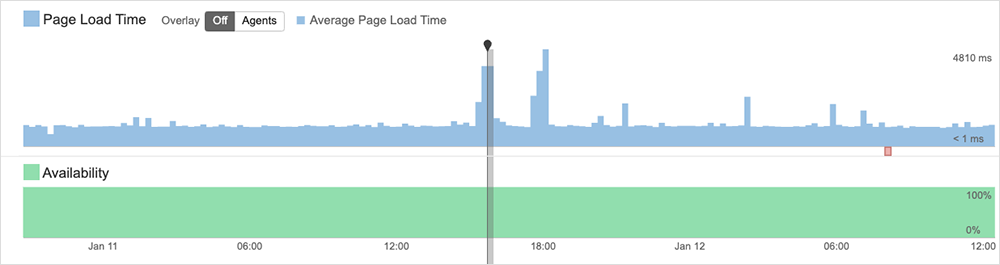
DigitalOcean Disruption
Cloud service provider DigitalOcean experienced a major network issue between 8:15 PM and 9:45 PM (UTC) on January 10. According to its incident report, the issue caused disruptions to several of its services and products worldwide, affecting many users who rely on the impacted DigitalOcean’s services for their business operations.
The outage manifested as elevated error rates and latency for a range of activities—from accessing the company’s website, to resolving DNS, and accessing the control panel to manage infrastructure consumption. Users also saw “timeouts/increased latency for networking requests to Droplets and Droplet-based services,” DigitalOcean said in a brief post-incident status update.
According to ThousandEyes analysis, connections to DigitalOcean resources appeared to be unaffected, but access to specific services resulted in timeouts and/or degraded performance for users across different regions. My opinion is that this may indicate some form of backend load balancing or a workload distribution system issue.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (January 1-14):
-
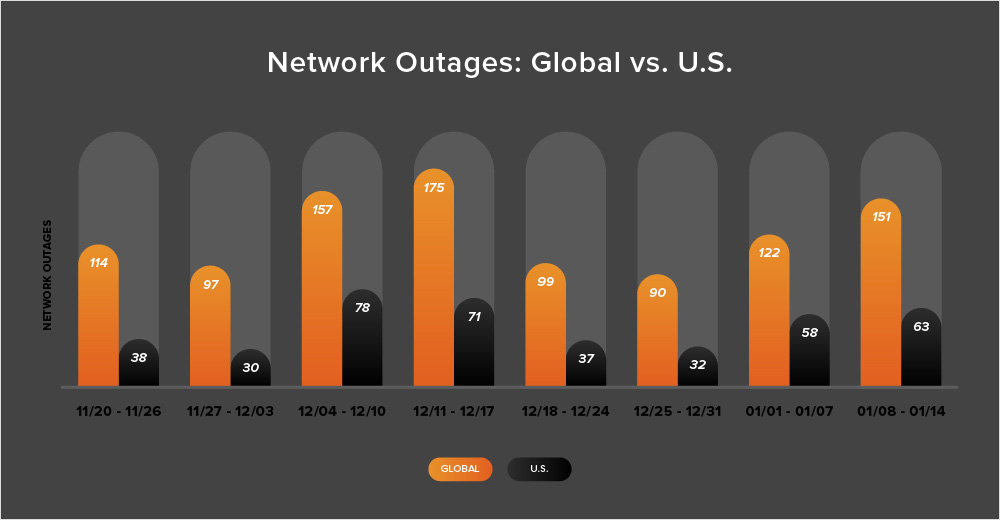
In past years, ThousandEyes has observed that the number of outages increases as we move forward through January. This year is no exception; the number of outages worldwide has risen significantly in the first two weeks of January. During the week of January 1-7, outages increased 36% compared to the previous week, rising from 90 to 122. This trend continued in the second week, with outages rising from 122 to 151, a 24% increase. The chart below illustrates this trend.
-
There seemed to be a similar pattern in the U.S., where outages increased across January’s initial two weeks. During the week of January 1-7, the number of outages rose from 32 to 58, an 81% increase when compared to the prior week. This was followed by a 9% increase, with the number of outages rising slightly from 58 to 63.
-
Over the past two weeks, outages in the United States have accounted for at least 44% of all observed outages, a trend observed consistently since April 2023 (with just a few exceptions). However, during the last two-week period of 2023, U.S.-based outages accounted for only 37% of all observed outages. This is somewhat expected as it was over the holiday period, and all outage numbers observed were trending down over the period.