


The past two weeks on the Internet were all about the cloud. And actually, a clarifying point right off the bat: it’s not limited to just the past few weeks. In fact, there’s been an upward trend in application faults over the past year, relative to other fault types (for example, those associated with networks), as shown in the following chart.
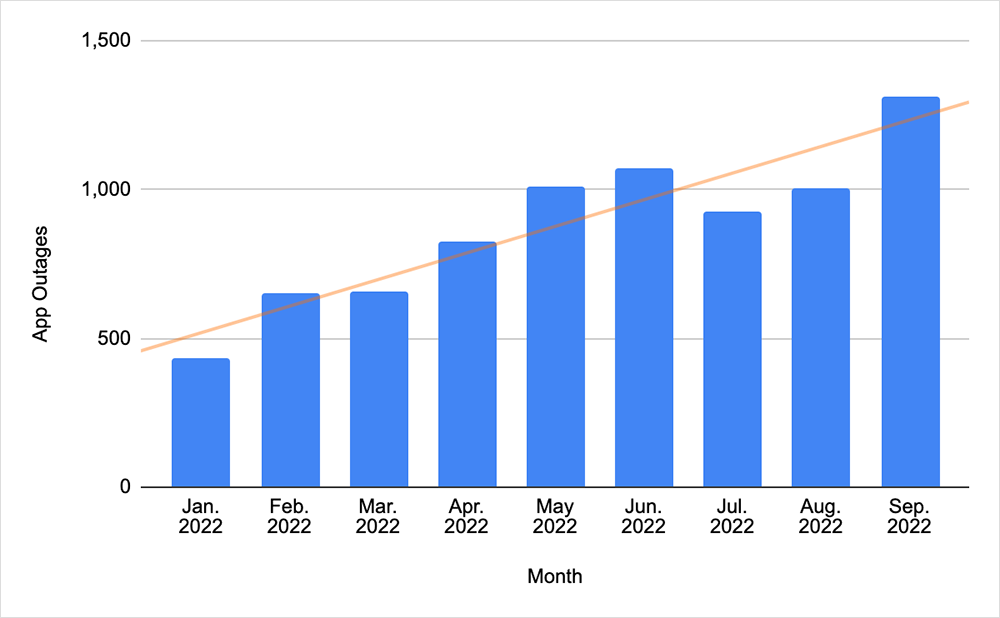
As to the cause of this trend, my theory is that when an application experiences fault conditions or degraded performance, there are fewer reasonable workarounds. However, a distributed network architecture may have multiple viable traffic routes, and software-defined intelligence built into networks means routing decisions can occur automatically, as needed.
These days, when a terrestrial telecommunications or data network has problems, ThousandEyes will detect it, but there’s often limited public-facing impact because the operator or enterprise customers are typically able to route traffic around the issue via an alternate, redundant path. That doesn’t mean that network outages have diminished to the point where they have a negligible impact; it is just the dependence on single or aggregated points of potential failure is less likely.
Applications, on the other hand, can be vulnerable to degradation or outages because the way they are architected often means they have dependency on a single or small number of central points or cloud-hosted functions. For example, an application may use one central database to store information, or it might rely on an API gateway to facilitate calls on that data.
Whatever the central point in the application’s backend is, if that central point has issues, and the application isn’t architected to run in a distributed fashion (for example, across multiple AZs or regions, which could be an expensive proposition) then public-facing impacts are likely. Which is why, when clouds wobble, applications can fail.
We’ll have more to say on this in the coming months, but in the meantime, it’s worth digging into several cloud outages that occurred over the past several weeks. These impacted some of the core services that applications rely on, causing downstream issues for application owners and end users.
AWS Outage
The first issue occurred on September 28th, manifesting as increased error rates on API Gateway endpoints in AWS’ US-WEST-2 region. The issues started at 10:13 AM PDT and were resolved at 1:43 PM PDT the same day, impacting API calls to 65 AWS services at its peak as well as applications with backend components hosted in US-WEST-2.
In a post-incident report, AWS said the root cause was “a subsystem responsible for request processing experienced increased load, which ultimately led to contention of a component within the affected subsystem.”
As to the front-facing impact, AWS said: “Customers with applications that use API Gateway [experienced] elevated error rates and latencies as a result of this issue.” For customers that had dependencies on API Gateway and were experiencing error rates, AWS said there were no mitigations “to recommend to address the issue on the customer side.”
ThousandEyes observed a mixed front-facing impact—some timeouts and some 503 errors—which are consistent with the high error rates identified by AWS. However, it appeared that if the end customer hit the application frontend and, through their actions, initiated repeat API calls to the application backend, it was possible that one might get through. Users could’ve been unlucky, but more than likely, after retries, they would have gotten a response back from the application they were using.
Sentiment analysis across social channels supports this, suggesting the issue was intermittent and not debilitating, and that users who did have problems took any temporary application degradation in stride.
Google Cloud Outage
The following day, for application owners and users relying on Google Cloud services out of São Paulo, Brazil, things were a bit more difficult. For almost 18 hours, Google Cloud reported “near 100% error unavailability” on Cloud Uptime Monitoring. The customer impact was that “public uptime checks were unable to egress from South America during the incident period. Affected customers would have observed partial or absent metric data from this location.”
The root cause was related to “a severed link in Google’s backend network in South America.” Google added that the issue was mitigated only “once engineers redirected traffic to alternate links,” it said.
The long duration (17 hours and 55 minutes) points to a particularly nasty cut or set of breakages. The cable may also have been in a particularly inaccessible or hard-to-access location or conduit, requiring meticulous splicing work.
Prolonged duration outages aren’t out of the question when a fiber cut is the root cause, though one would expect Google Cloud to be interested in any learnings, particularly those that might translate into future connectivity improvements, as a result.
Internet Outages and Trends
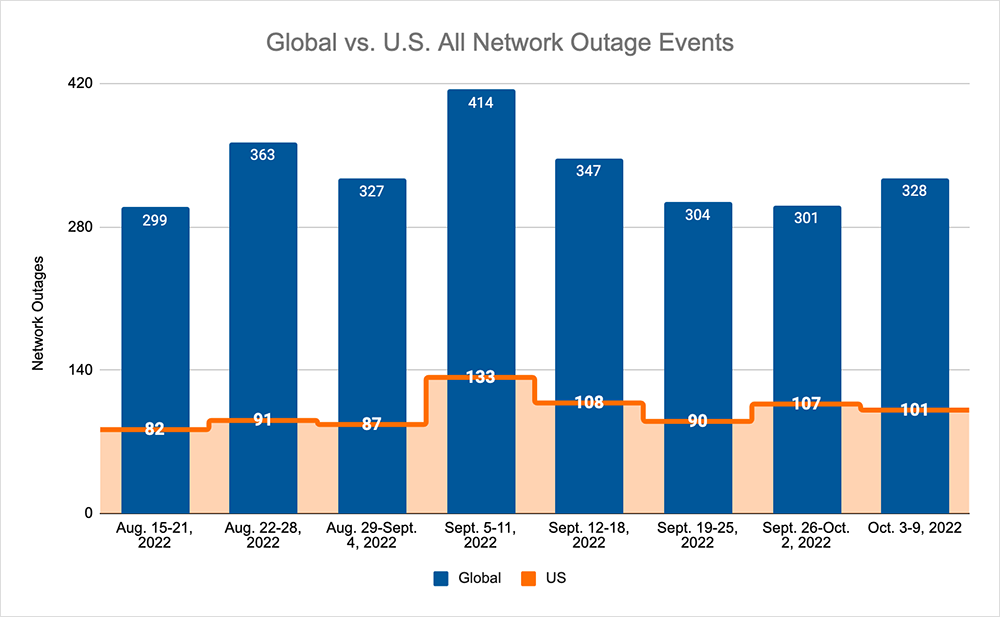
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
- Global outages continued the recent downward trend and initially dropped from 304 to 301, a 1% decrease compared to September 19-25, before increasing the following week, where we observed a rise from 301 to 328, a 9% increase when compared to the previous week.
- However, this pattern, and downward trend, was not reflected domestically, with an initial rise from 90 to 107, a 19% increase compared to September 19-25, before dropping from 107 to 101, a 6% decrease from the previous week.
- US-centric outages accounted for 33% of all observed outages, which is larger than the percentage observed on September 12-18 and September 19-25, where they only accounted for 30% of observed outages.
Other Incident of Note
ThousandEyes also observed a non-cloud incident at a US data center company, TierPoint, on September 25, lasting 41 minutes over a 55-minute period. Due to the issues occurring at a colocation facility operator, there was some impact to other regional nodes. The impact would have been limited regionally, however, as we did not observe any problems with major carriage routes, suggesting (as we did earlier) that these days at least, networking issues are now a lot easier to mitigate against.








