In outage root cause analysis, there are often recurring themes. One of these is single points of failure, where a common element that goes offline has a radiating impact on all applications that use it.
This past couple of weeks saw two such incidents that are interesting not just because they involved single points of failure, but also because, in both instances, those single points were upstream, out of the direct line-of-sight of end users of web applications and services.
End users don’t blame invisible upstream providers. They lay blame squarely at the feet of the organization they have a direct (possibly paid) relationship with. The organizations that bore most of the blame for these outages ultimately had no control over the situation.
We’re less interested (in this case) in misattribution than locating the root cause of the incidents—and this fortnight proved how hard that can be without good monitoring and visibility.
The first incident occurred at Australia’s central bank, the Reserve Bank of Australia, when it made a planned change to software used to manage a fleet of virtual servers that underpin real-time payments services. The change had unplanned consequences, causing critical payment settlement messages to either go unsent or be heavily delayed.
The public-facing consequence of this was that many customers’ payments did not go through immediately. Dozens of banks and fast payment service operators that overlay the RBA’s infrastructure immediately accepted the blame. It was not until the following day that the RBA acknowledged its role—cryptically at first, then later in a more detailed manner. Even then, much of the public reporting focused on the banks and fast payment service providers themselves, rather than on the party that was ultimately responsible for the outage.
The total length of the outage was about four-and-a-half hours, although the backlog of unprocessed or incorrectly processed payments took much of the following business day to clear. It was reported that 800,000 transactions, worth almost A$1 billion (US$620 million), were caught up.
The incident raises questions about single points of failure in the delivery of real-time payments in Australia. More broadly, it’s a reminder of the challenges many industries face as they go down the path of real-time and straight-through processing. When people transact in real-time, they expect more. The margin for error is much smaller than with batch-processed systems. The real-time nature of the application—instantaneous payment transfers—is what made this incident all the more critical.
The second incident appeared to manifest as an issue within NTT’s infrastructure. However, upon further examination, other Tier 1 providers like GTT, Zayo, and even Google were having similar issues. What they all had in common was a route through Chicago, with all paths appearing to lead to Deft (formerly known as ServerCentral Turing Group), a managed cloud data center and colocation provider headquartered in Chicago, IL.
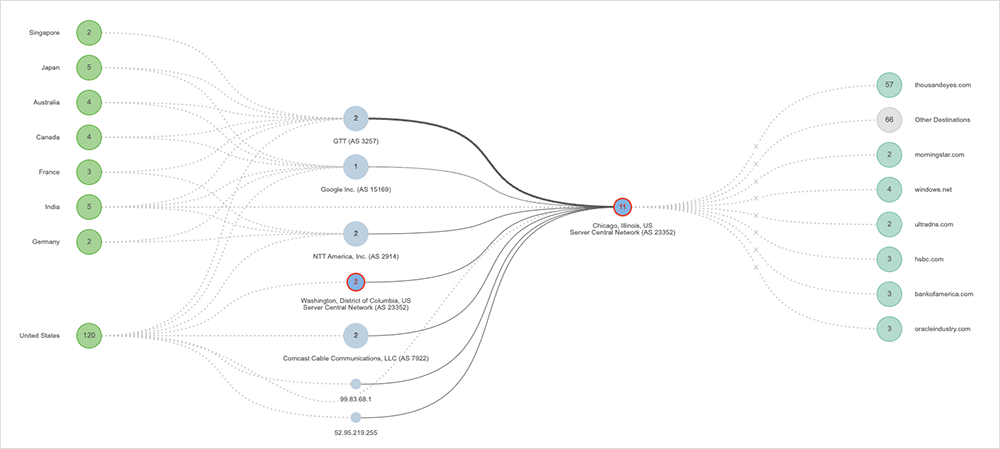
Our monitoring shows an impact of just over an hour on October 4 for some customers and downstream partners across multiple regions, including the U.S., Brazil, Germany, Japan, Canada, India, Australia, the U.K., France, and Singapore. We also observed four occurrences of outage conditions on Deft nodes across the hour, with one of these occurrences lasting 24 minutes.

The nature of the outage suggests, perhaps, a rack or infrastructure issue in the colocation facility, although it is difficult to know for certain. The Tier 1 providers impacted appeared to have enough redundant routes to circumvent the problem, suggesting there was little customer-facing impact. In addition, large colo providers generally do not publish status advisories that allow correlation with observed patterns and disruptions.
Again, the incident highlights the potential radiating impact that single points of failure can have on whole ecosystems, and the challenge of pinpointing the root cause and party at fault, when the party is a long way upstream. Without strong independent visibility, misidentification is possible—and even common.
Two Other Incidents of Note
There were two other incidents (or sets of incidents) worth discussing briefly that sit outside the broad theme for this blog.
First, ServiceNow experienced an outage that disrupted access to some of their services, globally. The disruption, lasting a total of approximately one and a half hours, appeared to intermittently disrupt connectivity to ServiceNow’s application, including periods of complete unreachability. The disruption appeared to have been initiated by an issue in an upstream ISP.
Second, health authorities on both sides of the pond had issues with Cerner software (which, as of June of this year, is owned by Oracle). On October 6, The [U.S.] Department of Veterans Affairs had issues that hit prescription refills for a full business day. Less than a week later, hospitals in the UK couldn’t access patient information when their Cerner instances errored with “invalid database configuration” messages. In the case of the U.S., it was reported to be the latest in a string of issues for the application since 2020.
Internet Outages and Trends
Looking at global outages across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks, we saw:
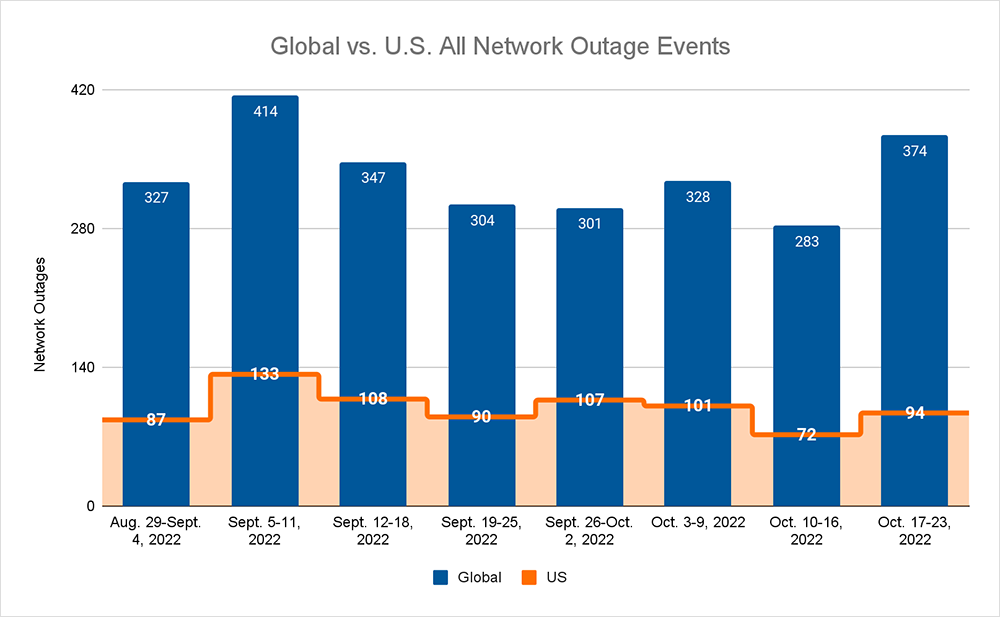
- Global outages continued the recent downward trend and initially dropped from 328 to 238, a 27% decrease compared to October 3-9, before increasing the following week, where we observed a rise from 238 to 374, a 57% increase when compared to the previous week.
- This pattern was reflected domestically, with an initial drop from 101 to 72, a 29% increase compared to October 3-9, before rising from 72 to 94, a 31% increase from the previous week.
- US-centric outages accounted for 26% of all observed outages, which is smaller than the percentage observed on September 26-October 2 and October 3-9, where they only accounted for 33% of observed outages.