This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
The Internet’s resilience is frequently tested, but thanks to the enormous investment in infrastructure over the years, it’s now possible to route around issues that would have previously created an outage or disruption. There are many ways to get traffic from Point A to Point B, so even issues at a major traffic exchange can usually be mitigated.
This played out recently as the Amsterdam Internet Exchange (AMS-IX) experienced issues. While ThousandEyes observed some localized impact on some organizations, the incident drew very little public attention. This was partially because the incident occurred at a transit point for traffic. Since other major transit points and links exist, AMS-IX was able to be temporarily bypassed until it could restore full peering connectivity. As a result, the potential for global disruption could be mitigated.
A second issue involving a peering exchange had a different set of impacts. In this case, the peer location itself was not impacted, but a downstream provider was.
These two incidents offer some helpful lessons for IT teams. First, degradation or disruption can happen to anyone, from the biggest Internet infrastructure operators to individual carriers. There are complexities on complexities when operating at scale, and it’s not realistic to protect against every possible combination of issues when scenario planning. Quite often, the unknown dependencies and unforeseeable edge cases cause the biggest headaches.
That said, all companies can benefit from a better understanding of all components and dependencies in the Internet ecosystem that contribute to their end-to-end service delivery. Having this information at hand helps them optimize service design and architecture, as well as take appropriate mitigation steps to maintain business continuity when an incident inevitably occurs.
Read on to learn more about these recent disruptions as well as separate outages at Oracle Cloud and Alibaba Cloud, or use the links below to jump to the sections that most interest you.
Optus and AMS-IX Outages
Recent changes appeared to trigger a series of events for two peering points internationally: one operated by Optus, the other by the Amsterdam Internet Exchange (AMS-IX).
In the case of Optus, there appeared to be an unexpected increase in the number of route announcements received from an upstream peering exchange starting on November 8. ThousandEyes observations, and details Optus shared, shed additional light on what happened.
This sudden surge of routing information changes spread through the Optus network and surpassed the predetermined safety levels on certain routers. As a result, those routers disconnected from the Optus network. Subsequently, the Optus network advertisements were withdrawn from global routing tables, which resulted in no return path from the Internet back to the Optus network. This led to 100% packet loss for customers, preventing many users from accessing Internet-connected services for more than nine hours. Some non-Optus customers were impacted as well, due to the fact they relied on a third-party service that was an Optus customer.

For them, this incident underscores the importance of deeply understanding your end-to-end service delivery chain, including the providers with which your own providers are peered. That information is valuable in helping organizations make their services more resilient.
On November 22, there was another incident involving a peering exchange. This incident appears to have started when customer-owned equipment began to propagate LCAP packets. According to ASM-IX, “These LACP packets triggered the teardown of LACP LAGs for other customers on both Juniper and Extreme (SLX) switches.” This resulted in flapping, timeouts, and error messages for other customers.
However, the public-facing impact was smaller, because telecommunication companies tend to utilize multiple peers, which would have allowed them to route around the issues at AMS-IX for the two hours it was impacted. This was confirmed by RIPE Labs, which characterized the incident as an example of “a healthy Internet interconnect ecosystem around these very large IXPs [Internet Exchange Points], suggesting there’s enough transit, direct (PNI) peering options and alternative paths … available for things to take a diversion when needed.”
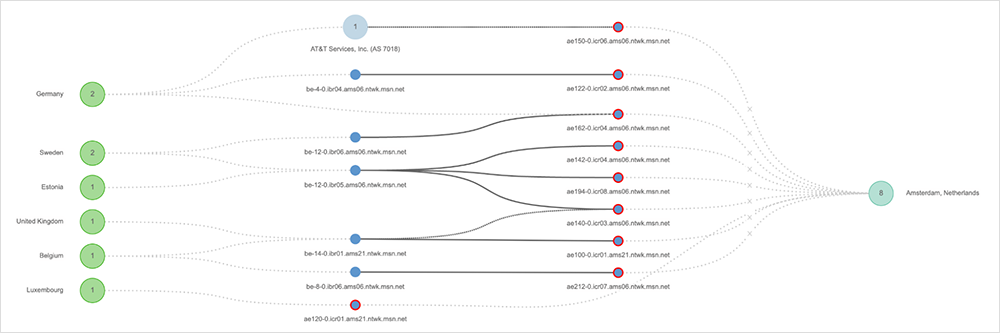
Oracle Cloud Outage
On November 15, Oracle experienced an outage on its network that impacted customers and downstream partners interacting with Oracle Cloud services in the UK South (London) region.
The outage was first observed around 10:30 AM UTC and appeared to center on Oracle nodes located in London, England, and Slough, England. Forty minutes after the outage was observed, nodes located in York, England, and Marseille, France, also exhibited outage conditions for around five minutes. The disruption lasted a total of 46 minutes, and connectivity appeared to be restored around 11:45 AM UTC.
Alibaba Cloud’s Duo of Incidents
Alibaba Cloud reportedly experienced two service outages this past November. The first occurred on November 12 after a major sales event and impacted some apps and services for about three hours. Then, on November 27, “abnormalities” were reportedly detected in the cloud console and OpenAPI access. Our speculation is that this would likely have manifested as functional degradation and disruption for customers, as problems in Alibaba Cloud’s backend prevented it from fulfilling customers’ requests or actions.
By the Numbers
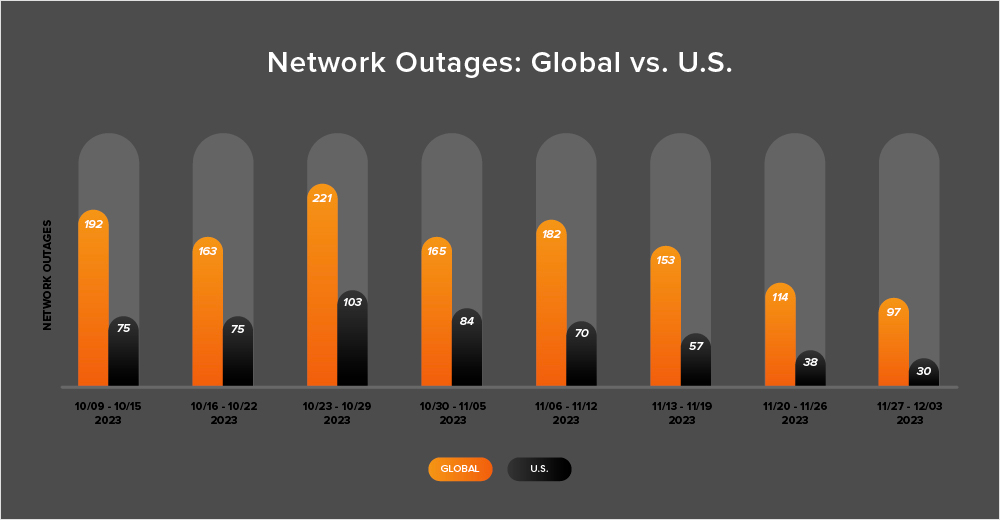
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past four weeks (November 6 - December 3):
-
Between November 6 and December 3, observed outages globally trended down. In the first week of this period (November 6-12), the number of outages increased from 165 to 182, which is a 10% rise compared to the previous week (October 30-November 5). However, in the following weeks, there were significant drops in observed outages of 16% (from 182 to 153), 25% (from 153 to 114), and 15% (from 114 to 97). The chart below illustrates this trend.
-
Outages in the U.S. followed a similar pattern, continuing an even longer downward trend that started the week of October 30 - November 5. During the week of November 6-12, outages decreased from 84 to 70, which represents a 19% decrease when compared to October 30 - November 5. This was followed by further decreases of 19%, 33%, and 21% in the following weeks.
-
In recent weeks, U.S. outages also diverged from a trend observed since April 2023. During nearly every two-week period since April 2023, U.S.-based outages have accounted for at least 40% of all observed outages. However, for two consecutive fortnights, this has not been the case. Between November 6 and November 19, U.S.-based outages accounted for only 38% of all observed outages. And from November 20 through December 3, they made up 32%.
-
Looking at the overall monthly trends, November saw 614 global outages, which is a 26% decrease from the previous month's 831 outages. Similarly, in the United States, the number of outages decreased from 355 to 241, a 32% drop. This trend is consistent with previous years, where outages tend to decrease as we approach the U.S. holiday season.