Note: Looking for analysis of the October 15th, 2015 UltraDNS outage? See it here.
Yesterday we woke up to alerts going off across a wide range of web services. In some cases, ThousandEyes employees weren’t able to access tools we use internally, such as RingCentral and Salesforce. We knew something big was up and dug into our tests to find out what was going on. Here’s what we saw and how we tracked the unfolding situation.
Alarms Go Off
Starting at 8:15am on Wednesday April 30th, service availability alerts started going off across a range of services that we track, including: ServiceMax, RingCentral, Veeva Systems and Salesforce. While these services were still generally available to users, particularly those with active sessions, new logins were in some cases affected.
A look at the HTTP Server view in Figure 1, showing service availability for ServiceMax, a field service management SaaS, shows the issues beginning. Our agents, which pull ‘fresh’ non-cached DNS records for performance tests, show DNS resolution failing for over 60% of locations. This view, combined with similar ones for other affected services, clued us in to a widespread UltraDNS issue.
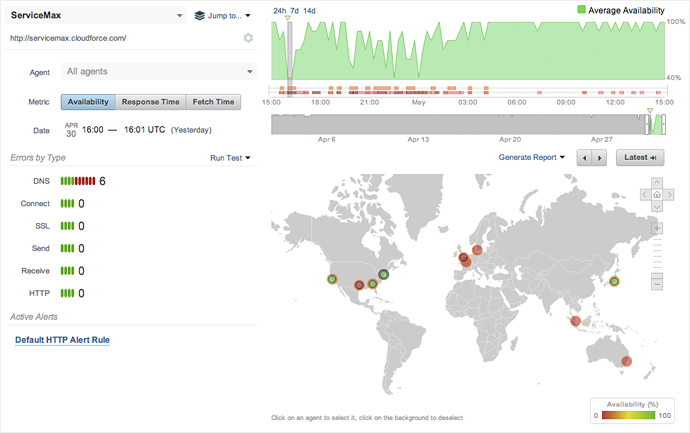
UltraDNS Outage
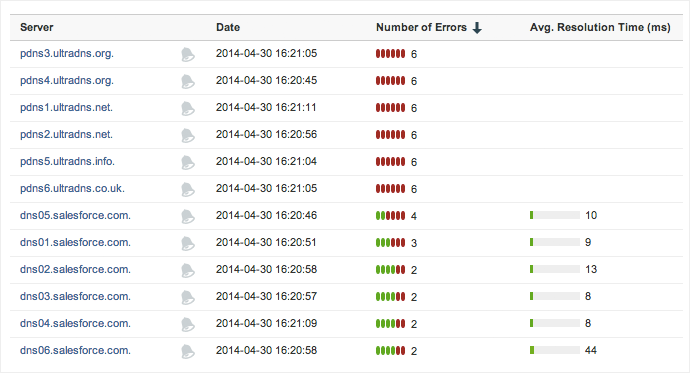
It quickly became apparent that service interruptions were related to an outage by UltraDNS, a DNS service offered by Neustar that powers a number of important web services and applications, including ServiceMax. We tracked this by diving into the DNS Server view, which gives us an understanding of how many authoritative name servers are available and resolving the hostname.
Figure 2 shows the authoritative name servers for ServiceMax, the same that are used for Salesforce as ServiceMax is hosted on the Salesforce platform. For several hours, a majority of the DNS servers were unable to resolve hostnames, and those that were saw up to a 10X increase in resolution time.
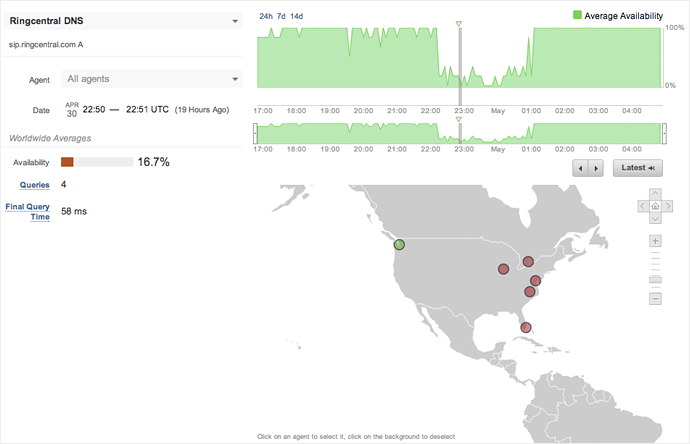
We see a similar issue with RingCentral, which also uses UltraDNS, in Figure 3.
Looking further, we can see from a network metrics view that there is high packet loss occurring en route to UltraDNS from all of our agent locations. Figure 4 shows more than 50% packet loss to UltraDNS servers and UltraDNS hosted servers, such as the one for ServiceMax and Salesforce.
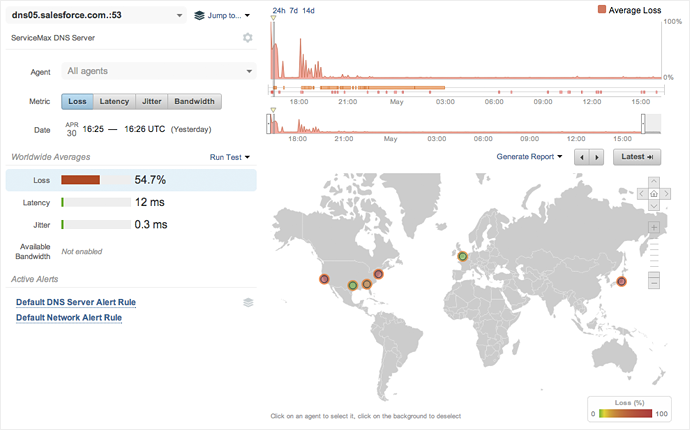
DDoS Fingerprints
Looking further into the situation, we can see that the outage was actually being caused by a DDoS attack on UltraDNS. We are tipped off about this from the sudden, severe and widespread packet loss that we saw in the previous view. To validate this we can use a path visualization of packets from our agents to UltraDNS servers.
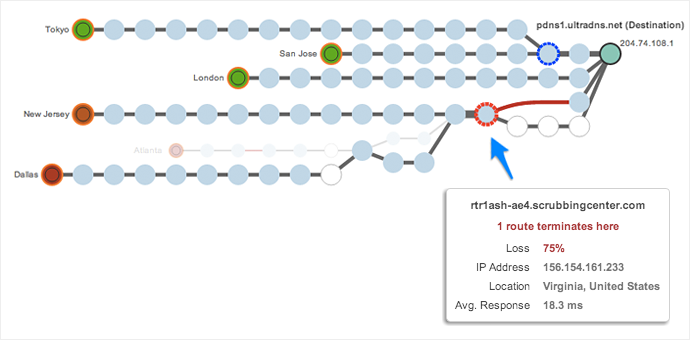
Figure 5 reveals the DDoS attack, with traffic flowing through scrubbing centers (highlighted with dotted lines) that filter out attack traffic. One scrubbing center appeared to be performing well (blue circle), enabling DNS resolution from the Western US and international locations. Another (red circle), is causing significant packet loss and DNS resolution problems for Eastern US locations. UltraDNS has confirmed that this was indeed a DDoS.
Troubleshooting DNS and DDoS
All in all, the UltraDNS outage impacted customers for up to 13 hours, from 8am to 9pm Pacific. With DDoS attacks becoming ever more powerful and creating large-scale disruptions, it is important to monitor your key services such as DNS. Tools such as DNS Server tests and path visualization help you keep an eye on unfolding service outages to plan a proper response. If you’re interested in learning more about how DDoS attacks affect service availability, check out previous posts on Visualizing Cloud-Based DDoS Mitigation and Using ThousandEyes to Analyze a DDoS Attack on GitHub.





