At the heart of any network performance monitoring and diagnostics application is a pretty simple concept: watch for something, and tell me about it. In prior blog posts, members of our team have covered specific use cases for monitoring for CDN performance, watching for BGP hijacks, and understanding when you’re being hit with a distributed denial of service attack. In this post, we’ll focus on the second half of the concept: telling you when something is happening.
ThousandEyes provides a rich alerting capability, which can be used to notify members of your team when something is amiss. From alerting on HTTP availability and DNS responsiveness, to loss and latency issues and upstream BGP changes, alerting can trigger at any point, based on the thresholds you define.
But… what happens once an alert triggers?
In our platform, alerting is an event that is triggered when your test data meets certain conditions. You define these conditions in alert rules — and the alert rules can be as simple or complex as you need them to be.

delay in paths through Cogent’s network exceeds 200ms.
Data is checked against the assigned alert rule conditions as it comes in; this evaluation against the assigned alert rules is handled on a per-agent basis. Given this, there are a few sensitive points that we’ll need to make you aware of:
- It’s very important that agents are time synchronized, for the purposes of alert rule evaluation. Data evaluation only happens for the current round: if an agent reports data for a different round due to time synchronization issues, it may affect the processing of alert data.
- If an agent fails to report data for a round, that agent’s response is not considered during evaluation of alert rules: in the event that an agent is overloaded for a round and fails to run the test, its results will not be considered.
- Alerts can’t be manually acknowledged or cleared. Each alert rule assigned to a test is evaluated on a per-round basis, and the test data either results in a match or not.
Once an alert rule has been triggered, it becomes an alert. Users can optionally notify on alerts, or just allow the system to log the timing when the alert criteria is met.
Captain Obvious Says…
Keep in mind that there’s a lot going on at any given time on the Internet, and you need to allow for when the Internet is being… the Internet. Whether you’re designing services to be used over the Internet, or a consumer of a service - you need to account for occasional deviations in metrics as “normal”.

Tune your alerts to trigger based on the business metrics associated with your service, but to notify you when something’s wrong that you need to do something about. This sounds obvious, but you’d probably be surprised to see the number of instances where alerts quickly become noise. An alert should be something that, when a page wakes you up in the middle of the night, you can (and need to) do something about. Alerts without notifications can be useful from a reporting perspective: report on the number of triggered alerts, or on the percentage of inactive alert time via our handy reports interface.
.")
As a reminder: remember to schedule an alert suppression window when running scheduled maintenance. Alert suppression windows prevent alerts from being generated, potentially impacting on service performance reporting.
So… What Happens When It Gets Worse?
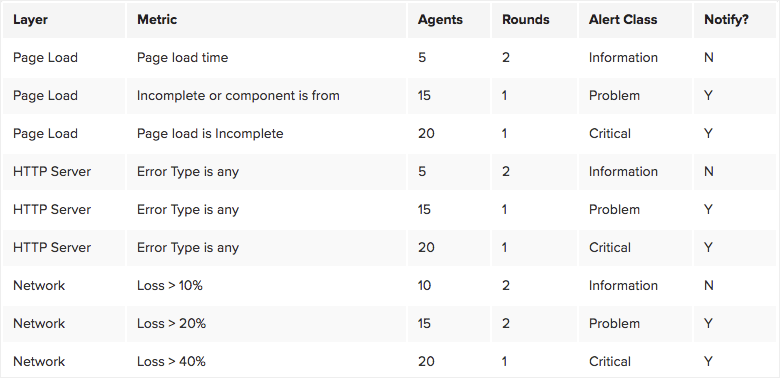
The #1 recommendation in this area is to design your alerting based on thresholds. An alert that is informational at first may increase (or decrease) in severity, so having one catch-all alert won’t achieve that balance between useful information and noise. Consider a page load test running from 40 agents:

You may have different classes of alert based on each layer of data. Each class of alert may be bound to a fixed number of agents, with increasing severity:
Email Notifications
By far the most common approach to managing alerts; add a list of recipients to a notification, and those recipients will be emailed a notification in the event of an alert. When multiple alerts are triggered for the same test in the same round, notifications are grouped based on common recipient lists.
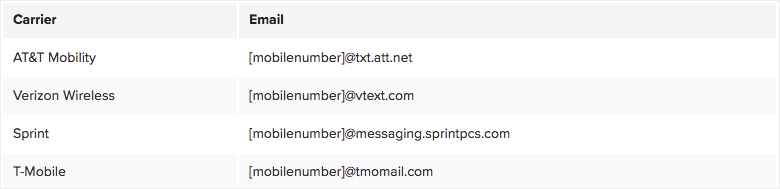
For users wanting SMS notifications, we recommend using an email-to-text service for email notifications. In the United States, mobile carriers often provide this service for free, providing a unique email address for each mobile user. A sample list of target domains for major US mobile operators can be found below:
PagerDuty Notifications
A much more advanced system than using email-based notifications, PagerDuty allows companies to configure services, on-call rotations, acknowledgement requirements, and escalation rules for inbound notifications. ThousandEyes provides a native integration with PagerDuty for triggering notifications.
We use PagerDuty ourselves. It’s a great service, and if your organization doesn’t already have an integration, I can’t recommend it enough.
Third-Party Integration via API
If you’ve already got a system in place for managing incident notification, logging and response, you may want to integrate directly into those systems. ThousandEyes provides two simple methods for doing so: pull from our API or get a push notification via Webhooks.
When you’ve got an existing system, perhaps the most efficient way to handle the incident response strategy is to query the ThousandEyes API directly on a periodic basis to pull alert notifications. In this approach, you’ll query the API periodically (once or twice per minute) to check for new alerts, pulling alert details for any newly generated alert.
To pull a list of currently active alerts, query the ThousandEyes API without any parameters:
$curl https://api.thousandeyes.com/alerts.json \ -u noreply@thousandeyes.com:g351mw5xqhvkmh1vq6zfm51c62wyzib2
To pull a list of alerts active during a certain window, specify this window using a parameter:
$curl https://api.thousandeyes.com/alerts.json?window=90d \ -u noreply@thousandeyes.com:g351mw5xqhvkmh1vq6zfm51c62wyzib2
Note: when specifying a timeframe for your query (using either a window or from/to times), only alerts which began during the window will be shown. If an alert was active prior to the specified window starting, it will be suppressed from the output.
To pull details on a specific alert, query based on alert ID. This will show each agent involved in the alert, along with start and end times for the alert.
$curl https://api.thousandeyes.com/alerts/2081207.json \ -u noreply@thousandeyes.com:g351mw5xqhvkmh1vq6zfm51c62wyzib2
Check out our developer reference at http://developer.thousandeyes.com for more details on using the ThousandEyes API to pull alerting information.
Integration via Webhooks
In the event that you want ThousandEyes to notify you directly, but don’t want to query the API to pull alert details, you can configure a target service to accept HTTP POST notifications from ThousandEyes. Known as a Webhook, when an event is triggered inside ThousandEyes, our notification service sends a POST to the target service, allowing routing and handling of the notification internally. Note: when hosting a Webhook service, you’ll need to externally expose a web server capable of receiving the notification — however, you can configure authentication as applicable.
We’ve documented a couple of these simple examples using node.js on the Heroku service — check them out here: https://github.com/thousandeyes/simple-webhook-server
Other fun things we’ve seen done by customers:
- Integrate alert notifications (using Webhooks) to post to common chat-based services, such as HipChat or Slack (Slack example is shown in the node.js example above).
- Create a JIRA ticket for handling when an alert fires.
- Trigger an instant test from a new location when an alert is triggered.
- Use alerts in a positive manner - i.e. automatically mark a task as complete when a change can be detected based on metrics available in ThousandEyes.
- Deploy tests automatically during scale-out provisioning, and automatically activate the newly deployed hosts once tests to the new infrastructure return good results.

Tips for Configuring Your Alerts
At the end of the day, there’s no one-size-fits-all solve for managing your alerting requirements. When designing your alerting configuration, consider the 5 W’s:
WHO needs to be notified?
WHICH tests are failing, and WHAT is the impact?
WHERE are the problems being seen?
WHEN did the problem start?
WHY you’re waking someone up
After all, one of the keys of managing a platform which provides diagnostic services, timely notification is of paramount importance. Arm yourself with the right questions, and you’ll be sailing smoothly towards smarter management of your services.
You can put all of these tips into practice right now with your existing tests; learn more about alerts in the Customer Success Center or the Working with Alerts video tutorial. If you don’t have a ThousandEyes account yet, sign up for a free trial and begin monitoring your network.









