ThousandEyes actively monitors the reachability and performance of thousands of services and networks across the global Internet, which we use to analyze outages and other incidents. The following analysis of AWS’ US-EAST-1 service disruption on June 13, 2023, is based on our extensive monitoring, as well as ThousandEyes’ global outage detection product, Internet Insights.
Outage Analysis
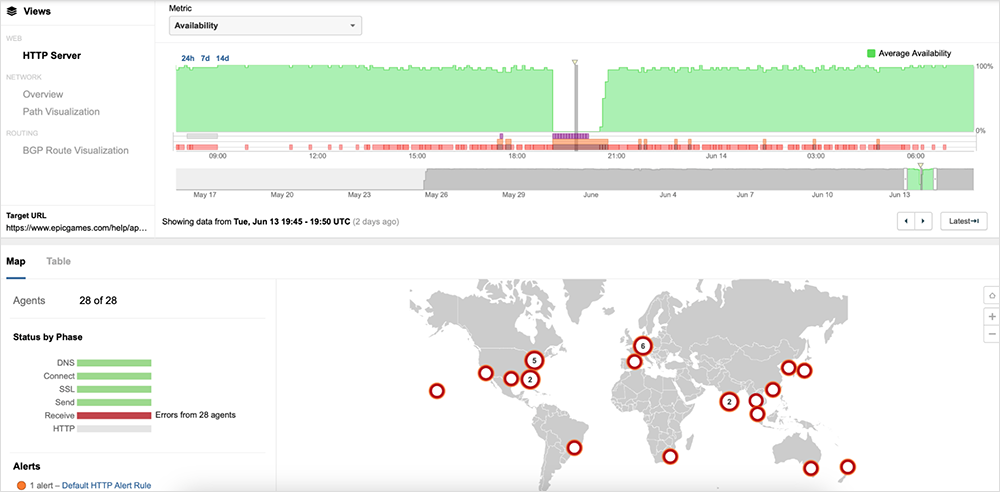
On June 13, 2023, Amazon Web Services (AWS) experienced an incident that impacted a number of services in the US-EAST-1 region. The incident, which lasted more than 2 hours, was first detected around 18:50 UTC, when ThousandEyes observed an increase in latency, server timeouts, and HTTP server errors impacting the availability of applications hosted within AWS. The issue was mostly resolved by 20:40 UTC, with availability returning to normal levels for a majority of impacted AWS services, as well as subsequently affected applications.
You can explore the outage within the ThousandEyes platform here (no login required).
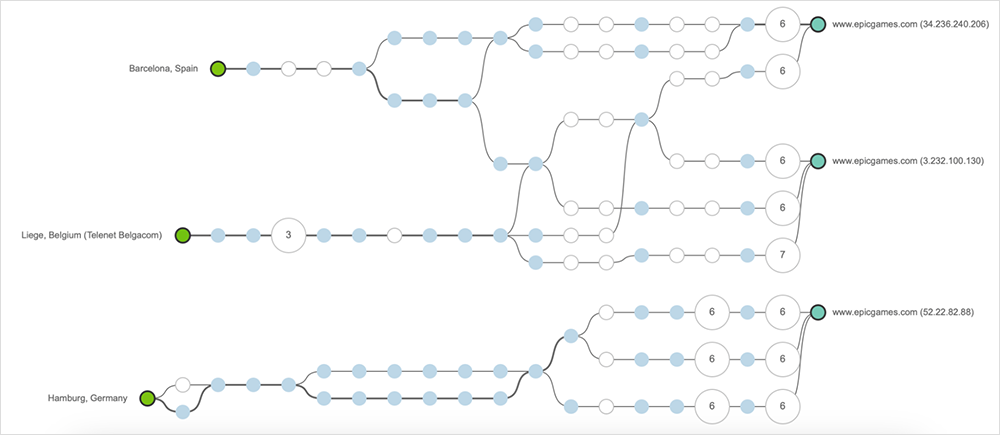
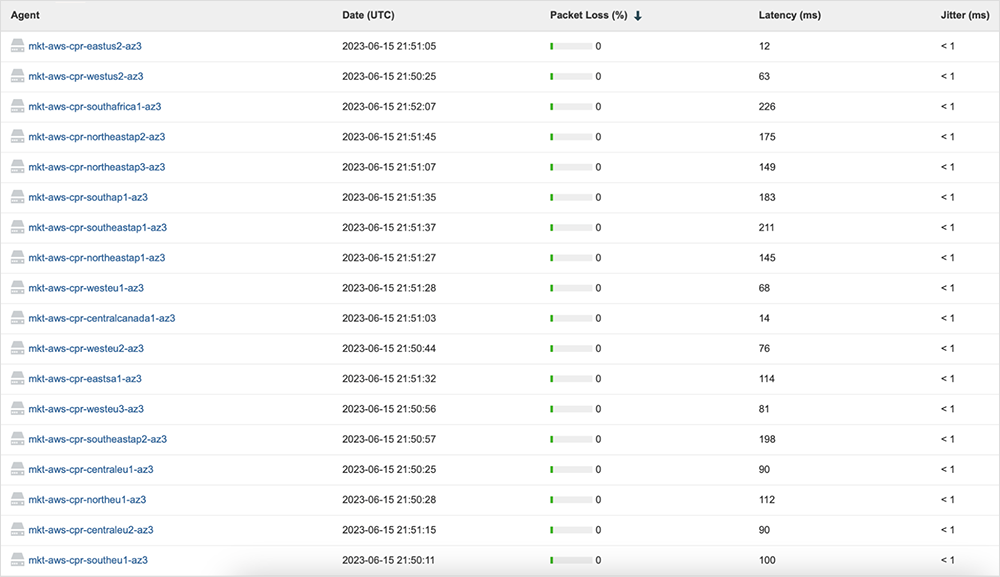
During the incident, ThousandEyes did not observe any significant issues, such as high latency or packet loss, for network paths to AWS’ servers, as Figure 2 shows.
However, the incident appears to have manifested as elevated response times, timeouts, and HTTP 5XX server errors for users attempting to access impacted applications (see figure 3).
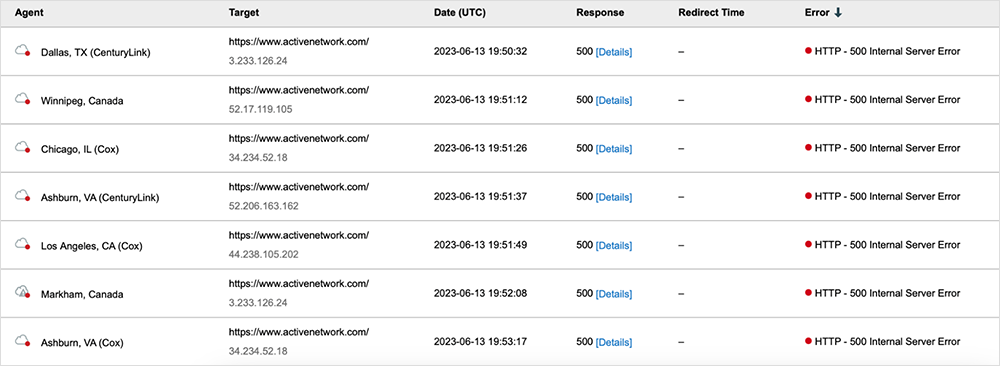
The HTTP 5XX server errors, as well as the receive timeouts ThousandEyes observed, point to an application issue that was likely related to a backend process. The applications that were impacted during the incident appeared to experience issues regardless of where the frontend web servers were located. However, the simultaneous failure conditions ThousandEyes detected in the US-EAST-1 region suggest there could be a potential point of failure for applications leveraging AWS services in that region.
Similar to the network conditions at the AWS edge servers, there was no apparent network degradation within the US-EAST-1 region at the time of the incident (see figure 5).
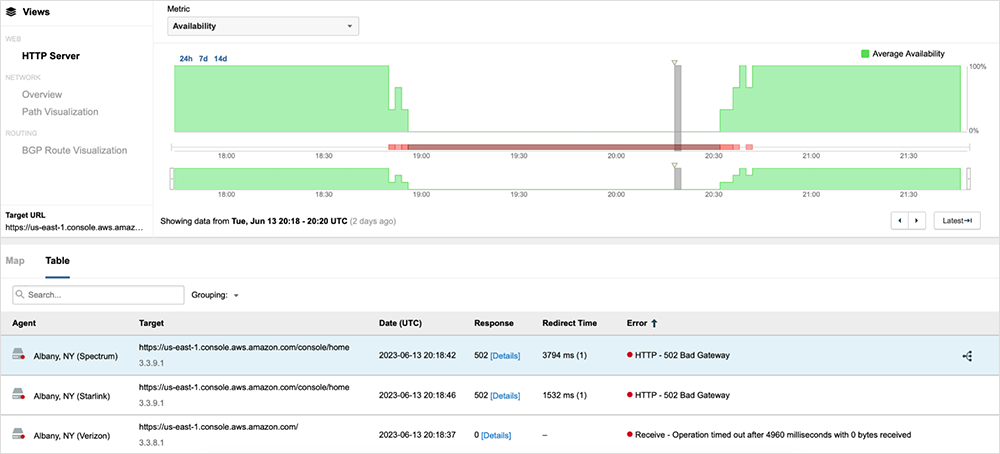
Approximately 20 minutes after the start of the incident, at 19:08 UTC, AWS reported that they were investigating a service issue in that region. At 19:26 UTC, AWS identified the source of the issue as a capacity management subsystem located in US-EAST-1 that was impacting the availability of over 104 of its services, including Lambda, API Gateway, AWS Management Console, Global Accelerator, and others. These affected services were experiencing elevated error rates and increased latencies. Subsequently, applications leveraging these services, regardless of where they were hosted or where they were serving users, would have experienced similar impacts in their own service availability. The issue was eventually resolved around 20:40 UTC, with availability returning to pre-incident levels, as figure 6 shows.
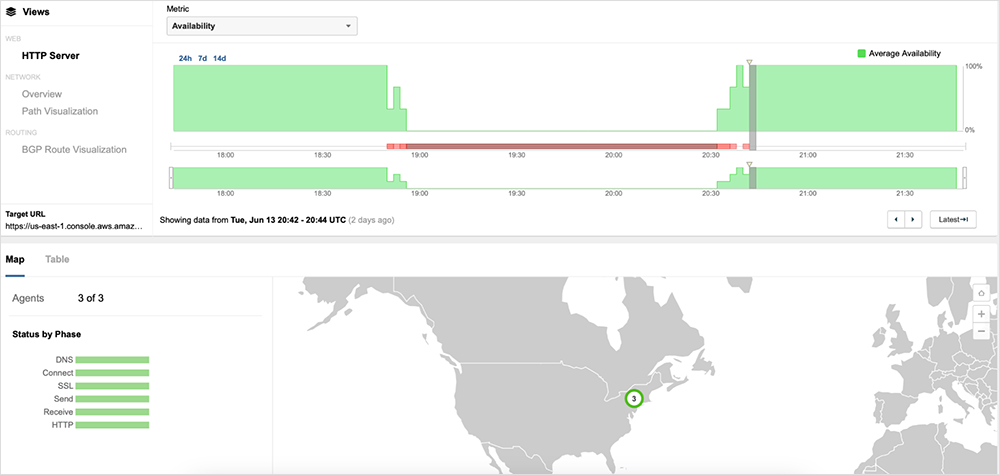
Approximately 20 minutes later at 21:00 UTC, another service disruption impacted some applications hosted in AWS for several minutes; however, this disruption appeared to be unrelated to the earlier ~2 hour incident.
Lessons and Takeaways
This incident illustrates the complex web of interdependencies that applications and services rely on today. Many of these dependencies may be indirect, or “hidden,” from the organizations, as they may be dependencies of the services they are directly consuming. In particular, many services offered by cloud providers such as AWS have fundamental architectural dependencies on one another. Organizations leveraging cloud services, such as those offered by AWS, should be aware of the relationships in their digital ecosystem, regardless of whether those relationships are services or networks.
Visibility is key to understanding dependencies and potential points of failure. Not every potential failure point in your service architecture is avoidable; however, being aware of your vulnerabilities and creating mitigation strategies in advance can enable you to minimize impact. The ability to quickly detect when these mitigation mechanisms are required is also critical to maintaining high availability—as is it for accurate attribution of issues.




