[Nov 15, 3:00 pm PT]
Early last week, Comcast experienced two distinct outages that were felt by customers across the US. In this analysis, we’ll cover what we observed in the ThousandEyes platform during and around these outages, and what it reveals about the internal complexities of designing and operating large-scale provider networks.
The first outage began late in the evening on November 8, shortly before 10 pm PST, and the second started during the early morning on November 9, 2021, just after 5 am PST.
Both incidents shared similar behaviors and, likewise, in both events, Comcast’s Sunnyvale, California core network appeared to be at the center of both local and broader traffic impacts.
What happened during the outages?
First outage starting at ~9:44 pm PST, November 8
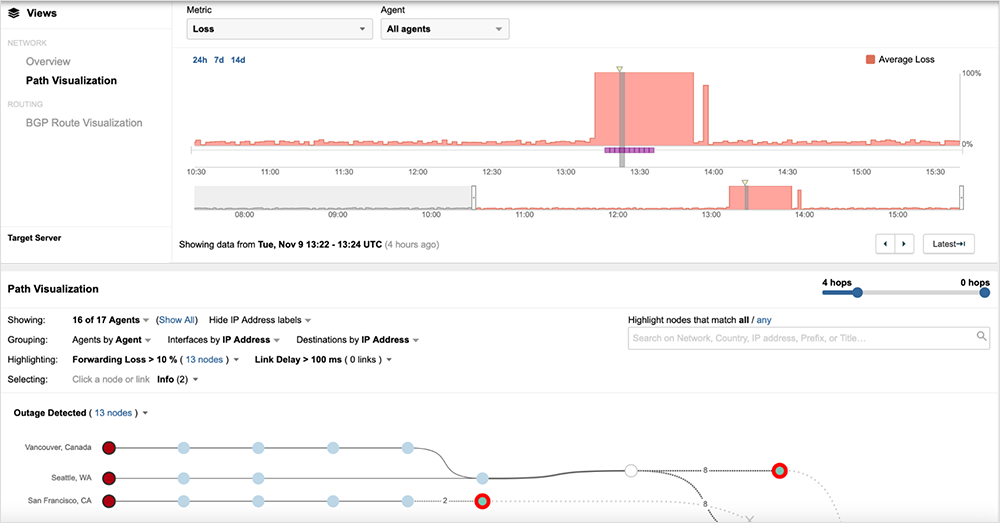
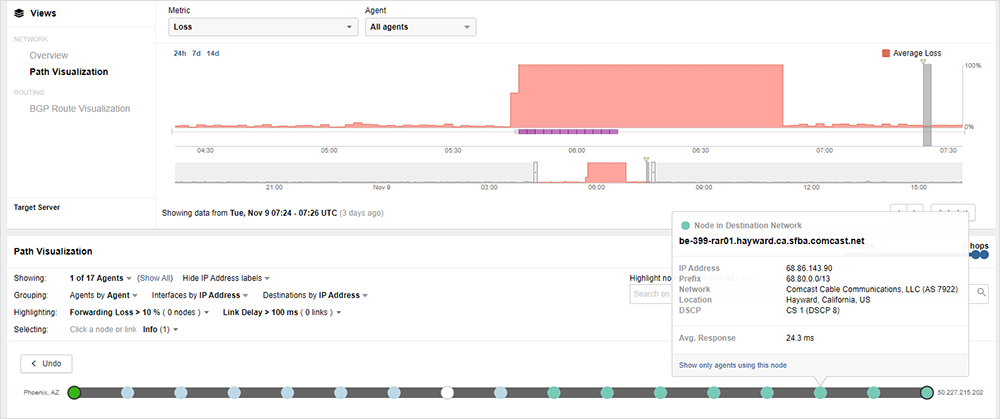
This first event began at approximately 9:44 pm PST on November 8th. In this first event, traffic that was traversing Comcast’s Sunnyvale core prior to the outage began to drop on nodes located in Sunnyvale.
Initially, from 9:44pm PST to approximately 9:46 pm PST, traffic traversing neighboring parts of Comcast’s network outside of Sunnyvale continued to be successful.
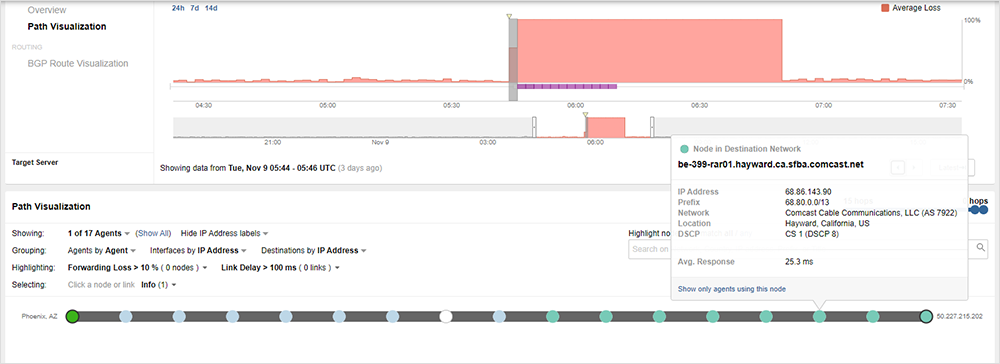
However, at 9:46 pm PST, we observed some neighboring traffic paths get rerouted, causing them to send traffic through nodes within the Sunnyvale core, at which point, they began experiencing the same total packet loss.
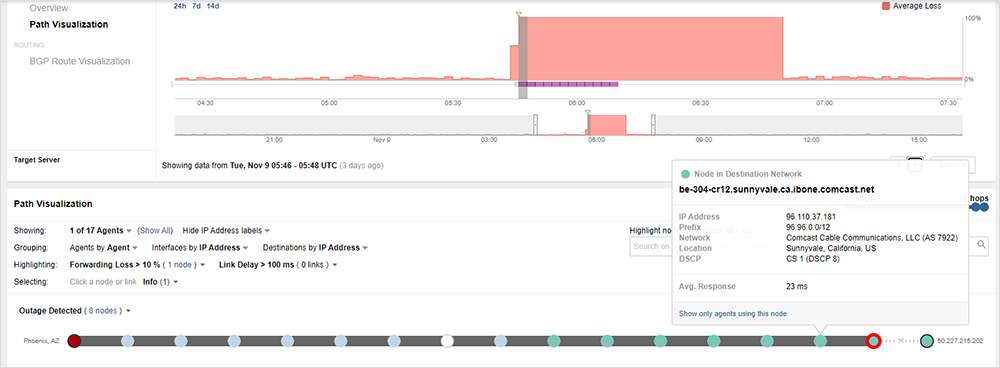
The first outage continued in this manner for another hour before traffic loss finally abated at approximately 10:48 pm PST. At that time, the traffic paths that had been rerouted to Sunnyvale during the incident had reverted back to their previous paths. The original, Sunnyvale-traversing paths were still going through the Sunnyvale core, albeit across a different set of Sunnyvale nodes than prior to the outage.
Overall, this first event appeared to be affecting traffic routed through Sunnyvale and its surrounding area.
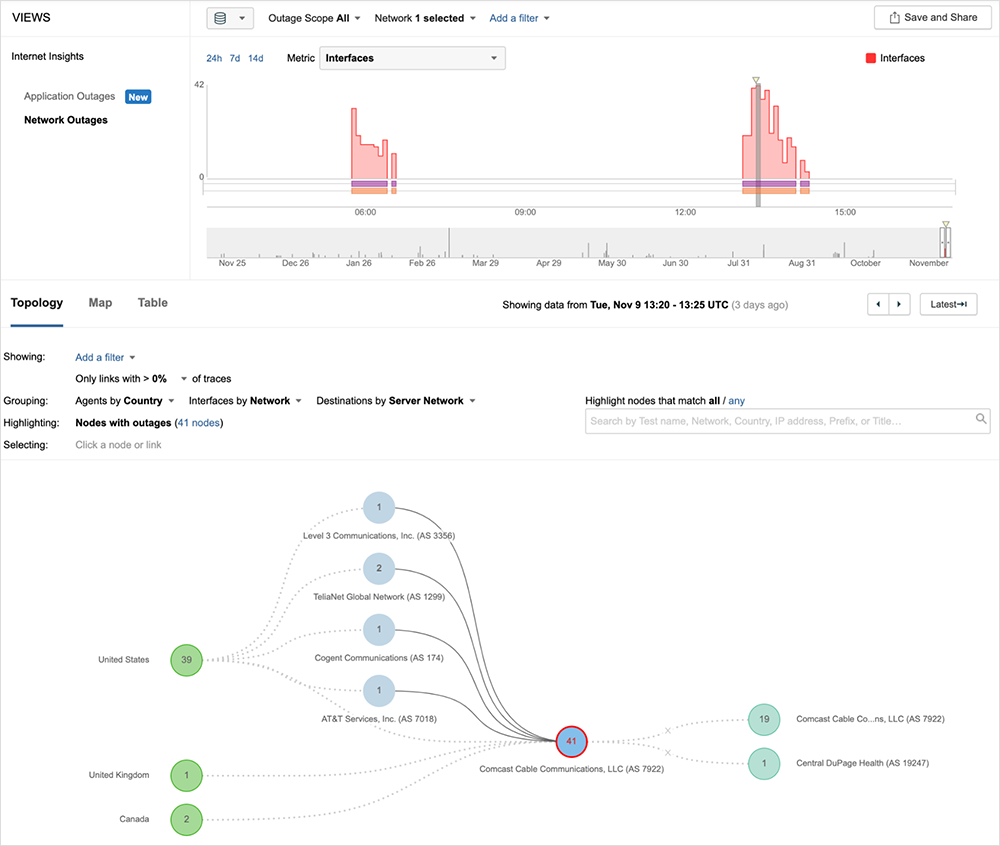
The second outage, however, had a much broader impact, with temporary “blackholing” of some Central and Eastern U.S. traffic in Comcast’s Sunnyvale core—despite the geographic distance from Sunnyvale and the fact much of that traffic would not have needed to have been routed through Sunnyvale (e.g., Chicago to Chicago traffic).
Second outage starting at ~5:05 am PST, November 9
Beginning at approximately 5:05 am PST, ThousandEyes observed 100% packet loss on nodes within Comcast’s Sunnyvale core network for some traffic that normally traversed through Sunnyvale. Much like the first event, we saw two categories of traffic impacted:
- Traffic already traversing the Sunnyvale core failed immediately at the start of the incident, and
- Shortly after the start of the event, some other traffic that previously was not traversing Sunnyvale was rerouted to Sunnyvale and also began failing.
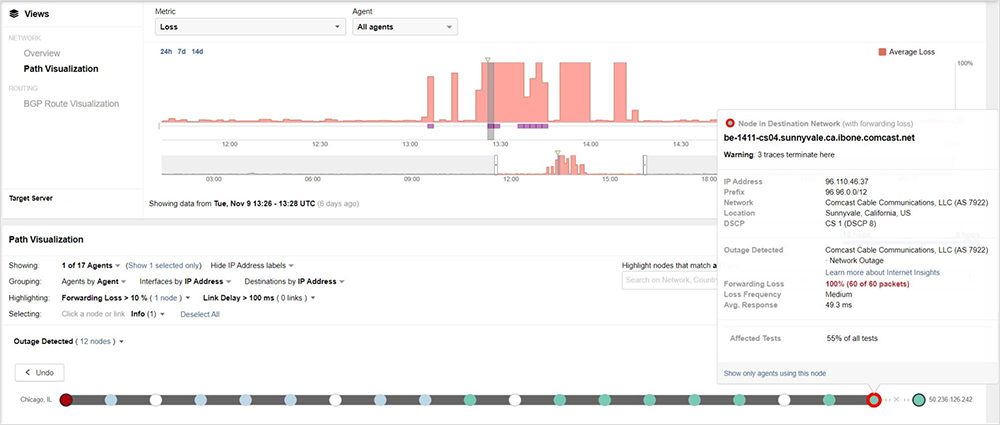
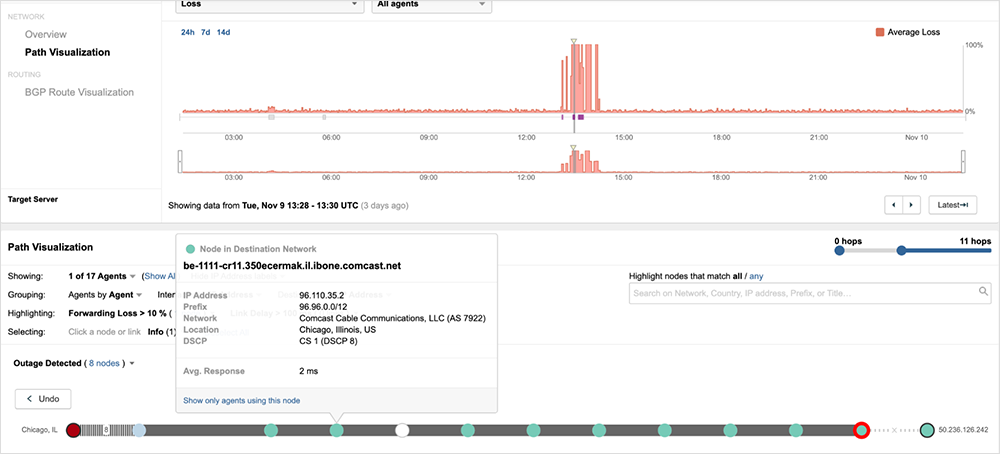
Unlike the first outage, some impacted traffic paths were intermittently reachable after the outage began, going back and forth between 100% loss and normal reachability. This flip-flopping may have been due to control plane churn, which are the rapid series of routing changes that occur as data plane recalculations are performed for all the forwarding elements when route changes or failures occur.
The fact that traffic paths across multiple coverage regions of Comcast’s network were rerouted and, ultimately, failed indicates a broader impact to users compared to the first incident. This aligns with reports of disruptions in multiple major metro areas.
By approximately 6:15 am PST, the second outage ended, with impacted traffic paths successfully reaching their destinations.
What could have caused these outages?
We know that many things can impact Internet traffic, such as Distributed Denial of Service (DDoS) attacks, hardware failures, link failures, fiber cuts, peer network failures, control plane software issues (such as misconfigurations), network changes, and even the occasional software bug.
In this case, a DDoS attack is extremely unlikely given the nature of how the outage unfolded. Typically, with a DDoS attack, an increase in traffic from malicious hosts would flood a network and start to overwhelm network capacity, causing higher latency due to increased packet queue depths and jitter due to sporadic delays caused by congested buffers. Eventually, given enough network congestion, packet loss would occur causing overall service degradation (rather than “outage”) for users of the network. The level of packet loss on network nodes also generally varies throughout a DDoS attack. In this case, we observed no increases in latency or jitter or varying levels of traffic loss, but rather a sudden occurrence of 100% packet loss on some network nodes.
What about a link failure or hardware failure? In those scenarios, we would not expect to see such widespread impact—in particular, the sub-optimal routing that accompanied the traffic loss.
A fiber cut? Not inconceivable, and there is precedence for multiple fiber cuts having a broad impact on a network. In 2018, Comcast suffered a large-scale, long-lasting disruption of its network caused by two fiber cuts. Fiber cuts, particularly if they occur in a critical location, can most definitely cause widespread control plane churn, especially if the cut were to separate parts of a network’s control plane, as it did in the 2018 incident. However, a fiber cut seems less likely to have been the cause of these two recent outages given that they were spaced hours apart from one another and, in the second incident, it occurred intermittently.
Which brings us to the control plane, which governs how traffic is routed to and within a network.
The Notorious BGP...but which one?
Even the most sophisticated network operators can suffer a control plane malfunction. In fact, when it comes to large-scale network disruptions, the control plane is often the cause or a significant factor in the scale and scope of an outage. In the provider world, this often means BGP.
But was it eBGP or iBGP? eBGP (external BGP) is used to communicate from one AS (autonomous system) to another AS. An example of this is when one provider talks with another provider. iBGP (internal BGP) is used within an autonomous system (AS), i.e., within a provider’s network.
How would we know if the issue was due to external BGP advertisements or something advertised only within Comcast’s network? In both Comcast incidents, we know it was not caused by eBGP as we see stable route advertisements to various providers amidst the outage.
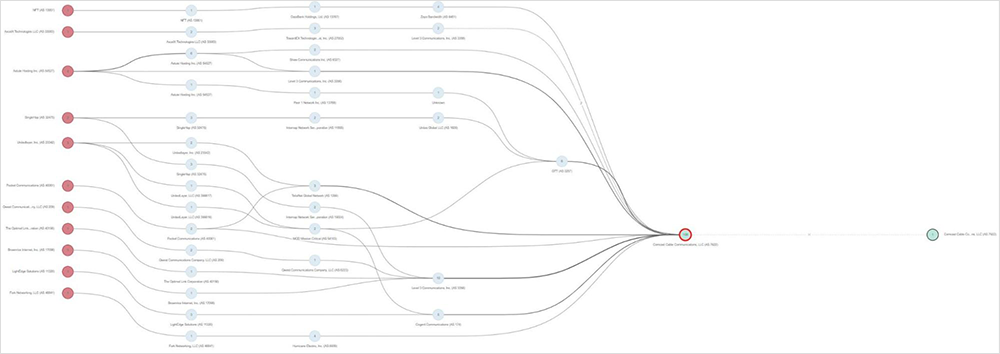
We know that many service providers rely heavily on BGP in their internal networks. To determine if the issue could be attributed to iBGP, we’ll need to consider how service providers architect their internal core networks, and specifically how Comcast’s is designed. Understanding these logical interconnections can help to explain how traffic moved from one part of the U.S. to another, as we saw during the second, far reaching outage.
In the November 8 and 9 events, we see some evidence of iBGP updates affecting Comcast’s core network traffic. This is illustrated in our example earlier of traffic getting routed to Sunnyvale, despite the source and destination both being in Chicago. We also see this behavior in the form of temporarily generated route loops while iBGP control plane churn is presumably ongoing (see figure 7).
Control plane software issues, such as bugs or a misconfiguration, can wreak havoc in amazing ways, with potentially wide-scale impact. To dig in further and understand more about the BGP behavior during these events, let’s look next at how Comcast’s internal BGP network is laid out.
A brief overview of Comcast’s core network architecture
Provider networks are usually designed both logically and physically to avoid such large impacts. So how does an event initially appearing to be localized in Sunnyvale affect areas outside of this region, such as Chicago and New York? Here’s where deep visibility helps us understand internal routing complexities.
First off, it’s important to understand that Comcast’s network is a fabric. A core node in Chicago is a part of the same cross-country network as a core node in Sunnyvale, California. Its network is purposefully built to support millions of customers and will interconnect across wide geographical distances to core routers over bandwidth-rich long-haul fiber.
Comcast utilizes a Clos (spine-leaf) design in their network cores, which enables them to scale their core capacity horizontally by increasing the number of routing devices, rather than vertically, which would require replacing outdated hardware with newer/bigger models. Although a Clos topology has been used extensively in network ASIC internal architecture and data center topologies, the use of a Clos fabric of smaller network devices to replace large fridge-sized routers is something relatively new and only made possible lately due to newer ASIC technology.
In Comcast’s network, this topology is complemented by a two-layer BGP design, which we’ll discuss a bit later. Such a two-layer BGP design is necessary in a Clos architecture for several reasons, but most importantly it provides flexible scaling both horizontally and vertically. With Clos, of course, we are multiplying everything—more links, more paths, more nodes. Providers like Comcast will have over a million prefixes in their internal core route tables. BGP full mesh may cause that to be 20 million or 30 million or more. BGP design in provider networks must account for such numbers.
From an operations perspective, Clos design means that the provider can enjoy a smaller failure domain and blast radius. In other words, a single router failure should not be able to take down a large part of a network.
Of course, this design does bring some additional complexity. Clos architecture gives us the concept of an extremely high bandwidth “backbone” or spine, to which the rest of the network connects; this is like its analogy in biology where a skeletal spine in an animal connects the rest of an animal together.
In this type of design, we have powerful core spine (CS) routers heavily laden with ports and capable of very high throughput that are connected downstream towards end users via Aggregation Routers (ARs) and Provider Edge (PE) routers. The ARs are in turn connected to the access switches handling end-user traffic or server traffic, whereas the PE routers connect to networks administratively handled by different providers. At the top of the spine reside the Core Routers, spread often across great geographic distances using long-haul fiber. This forms the provider’s core network.
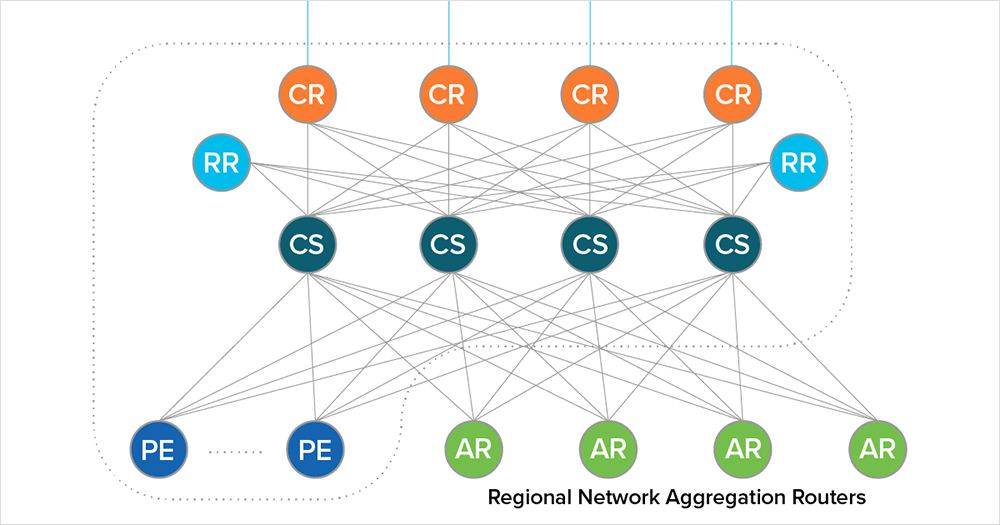
Note that if you are staying in one geographic provider region, say, for example, the Chicago area, you would never need to go to a CR. Your traffic would enter from an AR, or perhaps a PE if coming in from another provider, go to a CS, and then back down another AR or PE path. You only need to jump to a CR if you’re traversing to another provider-managed regional network.
As mentioned, Clos heavily increases the number of links as we now have many routers connected to the CS fabric devices. This is the very idea behind Clos architecture—every lower-tier node, or leaf layer, will connect to every top-tier node, or spine layer, creating a full-mesh design. User and server traffic enters the network at the leaf nodes, which are connected to every spine node in the fabric. The benefit of this is that if one of the CS nodes were to fail, it would only slightly degrade network performance given the extensive link and node redundancy.
Resulting from this are very large numbers of equal-cost multipath (ECMP) links that need to be properly load-shared for maximum efficiency so that we use as much of the available bandwidth as possible, evenly balanced across the links. We also now get an increased number of total nodes in the routing domain in this architecture.
This is where BGP steps in, including the two-layer design mentioned previously, to handle this scale.
The Route Reflector is king
To accommodate such a scale, operators leverage additional BGP features such as dedicated Route Reflectors (RRs). The idea behind the route-reflector is that, rather than have a full mesh of every BGP router talking to every other BGP router, we only fully interconnect the RRs to the other RRs.
Each of these RRs then take on the role of BGP server, controlling all BGP updates and sending them down to the individual routers as needed. Each of the routers act as clients to the RRs in this client-server BGP architecture. RRs, deployed in the full iBGP mesh designs, talk to each of the PE, CS, and CR routers, updating these BGP clients.
This simplifies the design, configuration, and updates needed for the network. In fact, this type of design using RRs is critical for both control plane administration purposes and for optimal convergence times given the huge numbers of ECMP paths and distributed long-haul fiber transports.
There are certainly risks with such scale and complexity given the sheer number of variables at play. For example, changes could potentially get disseminated beyond desired scope, leading to unintended consequences. However, the benefits can outweigh the risks, especially with operational systems designed to manage this added complexity.
The long arm of Comcast’s core network
Now, while the above detour into the design of Comcast’s core network may seem academic, it’s quite relevant in unpacking the specific behaviors observed during the outages and, in particular, the second outage.
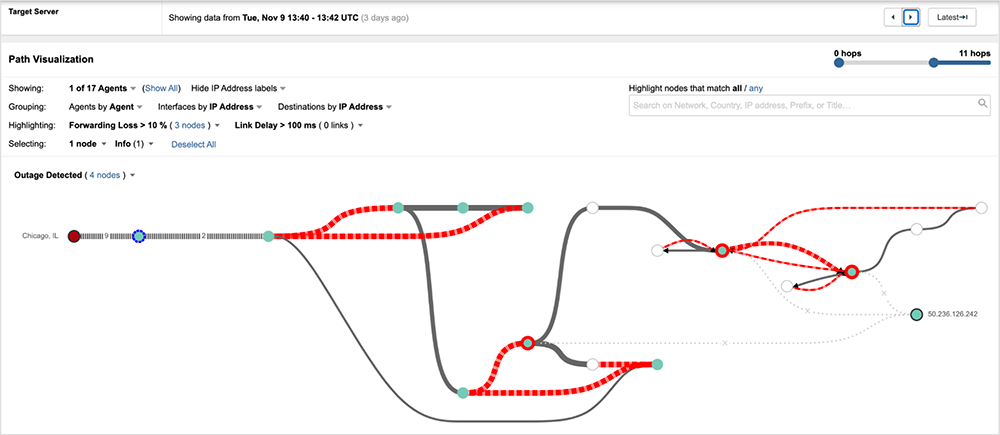
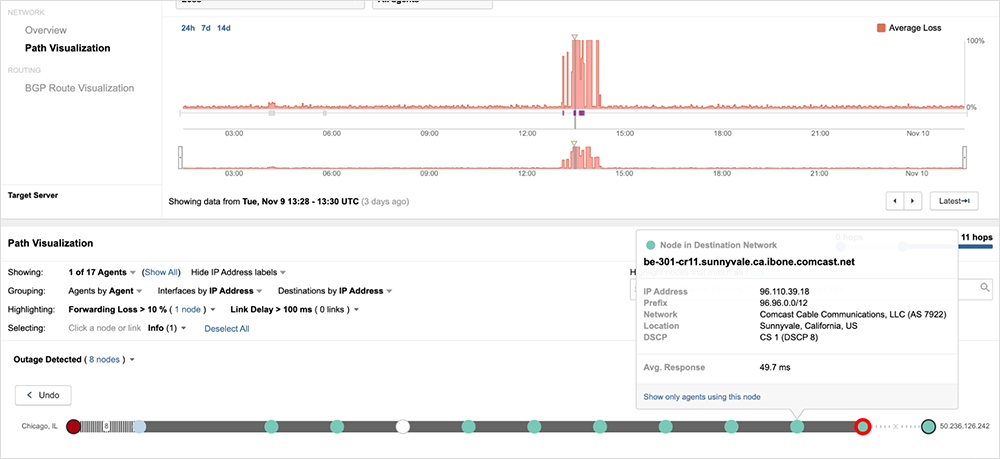
Returning to the example described earlier in this post, prior to the outage, traffic originating from a ThousandEyes vantage point in Chicago destined to a server located in Chicago and connected to Comcast's network enters the Comcast network and traverses through the spine (CS node). Illustrating this is traffic traversing Comcast’s cs04 node in Chicago.
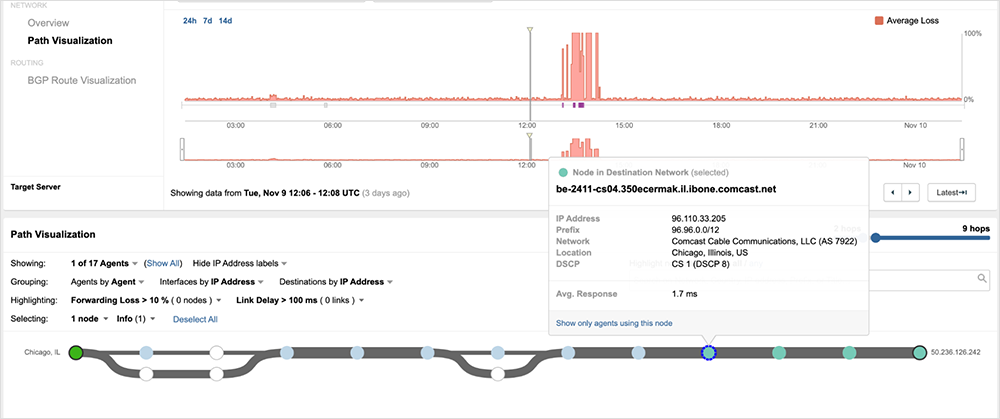
The figure below provides a high-level overlay of the route shown above on the Chicago core’s hierarchical architecture.
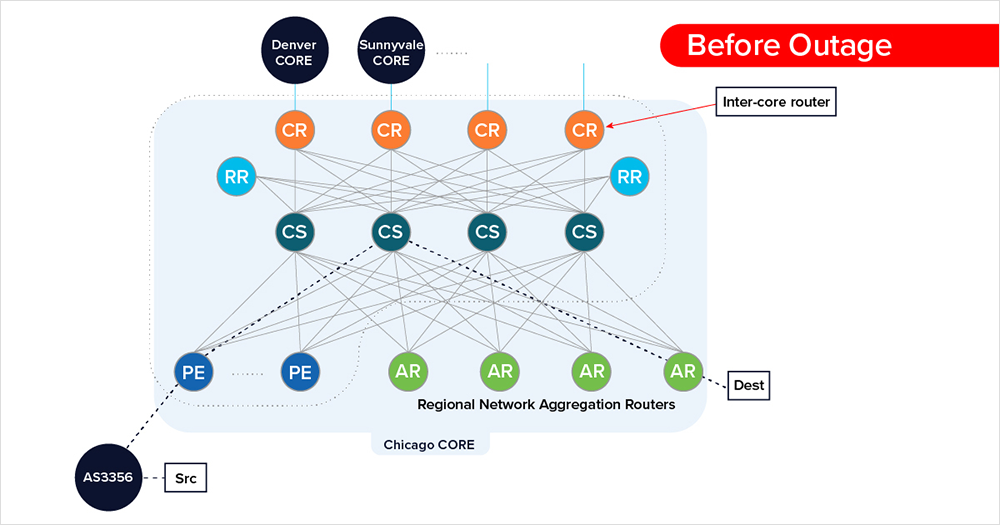
Traffic enters Comcast’s network through a PE router and traverses through the Chicago core network.
Once the outage starts, however, traffic from Chicago-to-Chicago now traverses a CR node in Chicago (figure 11) before getting routed to a Sunnyvale CR (figure 12), where it fails at a CS node in Sunnyvale (figure 13).
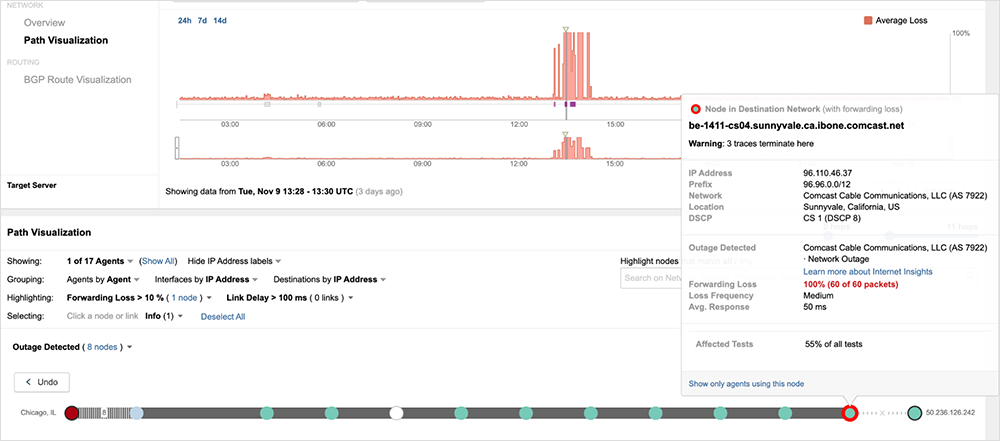
Given the source and destination of the traffic in this scenario, there would have been no reason for traffic to traverse to a Chicago CR node, as CR nodes handle inter-core (traffic between regional cores), let alone end up across the country in Sunnyvale. Figure 14 below illustrates the sub-optimal routing observed in the example above.
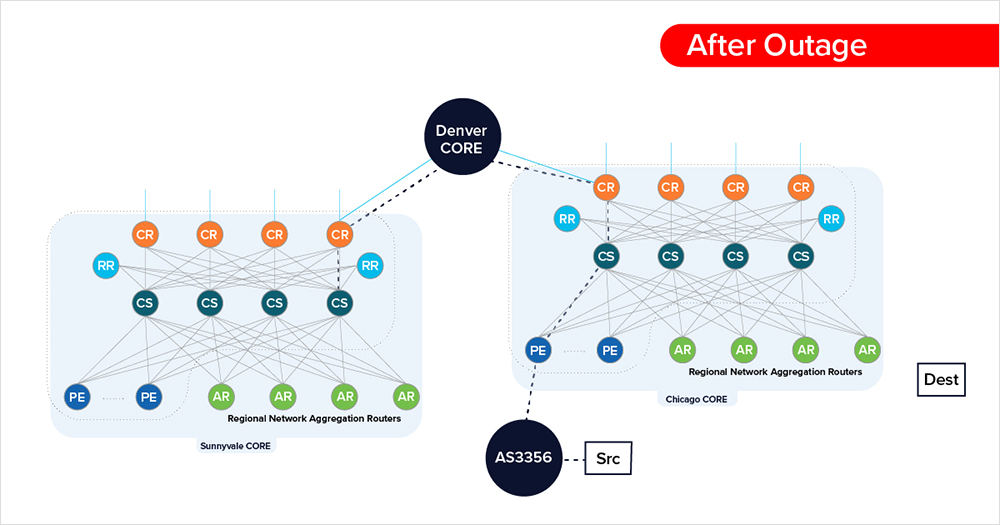
For traffic to take such a path, something would have occurred to precipitate the new routing. Some possibilities include an issue in Sunnyvale’s network that led it’s route reflectors to internally advertise more specific prefixes for routes that were otherwise advertised by other cores within Comcast’s network. Also possible is that for whatever reason, Sunnyvale was a backup route for other Comcast cores or was advertising a covering prefix that pulled traffic to its nodes when some other parts of the network became incapacitated. Both of these latter scenarios seem less likely given that the first outage was centered in a more local manner on Sunnyvale.
Lessons and takeaways
We all know outages are inevitable. Providers know this as well, as we see with all of their focus on the redundancies and scalability inherent in these multi-level BGP and Clos architectures, a reliance on next-gen core router hardware, and the extensive operational monitoring of granular fabric behaviors and metrics. Absolutely critical here is the later—the more real-time data and the more historical visibility gained over control plane behavior and health, the quicker a fault can be caught and mitigated.
Various legitimate control plane mechanisms can result in the things we saw with these events, especially the routing behaviors observed with the second outage. For example, the widely used BGP Prefix-Independent Convergence (PIC) feature creates a backup/alternate path in addition to its ECMP paths, so that when a failure is seen this backup path can quickly take over, enabling faster failover.
What it all comes down to, everything about network performance is about achieving good latency, low packet loss, low jitter, and good throughput, and ensuring that the operational frameworks of IP transports, BGP routing, and advanced systems such as DNS, do their job well and efficiently. To achieve this, network operators need data and control.
Enhanced visibility over control plane and the performance of data paths enables Ops teams with more than faster responses to incidents. Enhanced visibility importantly provides quicker (and safer!) restoration and improved capabilities for ongoing design, forecast planning, and increasing the operational efficiencies for the teams tasked with managing these gigantic swaths of gear, fiber, network services, and complex routing architectures essential for carrying millions of customers and incredible amounts of data.
[Nov 9, 11:30 am PT]
ThousandEyes detected two outages impacting Comcast’s network backbone. The first took place in Comcast’s backbone in the SF Bay Area between approximately 9:40pm-11:25pm PT on Monday Nov. 8.
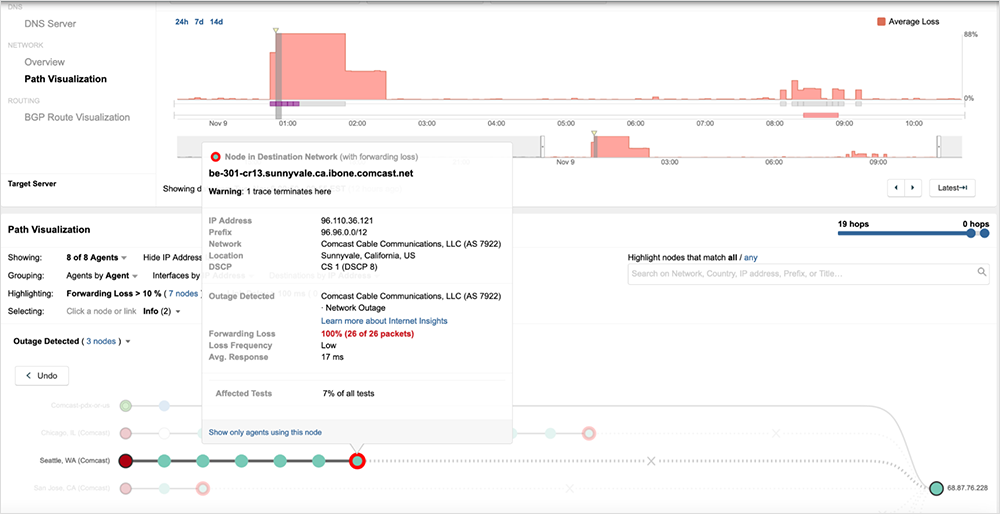
A second, more widespread outage occurred this morning starting at 5:05am and lasted over an hour until ~ 6:15am PT. The latter outage had broader reach across multiple cities in the U.S. Learn more on the Internet Outages Map: www.thousandeyes.com/outages/