In this blog post we're going to compare the parsing and serialization efficiency of three different C++ JSON libraries. We are carrying out this performance test because we use JSON-RPC in some of our applications. The volumes of data we handle are quite large and we need to be as efficient as possible when processing them.
Libraries to Test
JsonCpp: JsonCpp is among the most popular libraries for JSON parsing and manipulation and serialization. It currently has an average of 1,000 downloads per week from their sourceforge page. One of the strongest points of this library is its intuitive and easy to use API and complete documentation hosted on the library's site.
For the benchmarks we are going to use the trunk version at revision 276 of the svn repository.
Casablanca: This is more than a JSON library, it is a SDK for client-server communication developed and maintained by Microsoft. One of the cons of the Casablanca library is its immaturity. The first version was published on Jun 27, 2012. The library is actively being developed which is always a good sign. We are going to use version 2.0 for our benchmarks, this is the first stable release they have made and it was released on Mar 20th, 2014.
As Boost is a dependency of this library, we will use the latest stable version of Boost, 1.55.
JSON Spirit: This is a JSON manipulation library based on the Boost Spirit parser generator. JSON Spirit is a mature library whose first version was published on Aug 10, 2007 and has been regularly updated since. It is hard to tell whether the library is currently being maintained due to the fact that there is no code repository publicly available. The documentation is scarce but consistent and clear.
It provides two implementations for the JSON objects: using maps and vectors. Each of them has its pros and cons but at least both implementations are available. For our benchmark purposes we will test both implementations of the latest library release to date, which is version 4.06. The Boost library version used to compile it will be Boost 1.55.
Testing Environment
All the benchmarks were executed in a host with the following properties:
- Amount of Memory: 8 GB 1333Mhz
- OS: Ubuntu 12.04 64bit
- Processor: AMD Phenom II X4 925
All the tests and libraries were compiled using g++ version 4.8 with the following flags:
- -std=c++11
- -O3
Benchmark Tests
For each of the libraries we will analyze the parsing and serializing speed of three objects that will vary in size. In all of the cases the keys of the dictionaries are 16 byte strings.
Small Object Test: The small object consists of a JSON object that will contain 100 elements of different types inside it, it is nested up to 3 times, the nested objects have a maximum size of 10 and the lists contain up to 25 objects. The content of the file was generated randomly and you can download the data on GitHub. Its size is 800 KB.
Medium Object Test: In this test, the object has 5000 key-pair values of mixed types following the same nesting, inner object size and list size restrictions. The file can be downloaded from GitHub; it is 8.9 MB.
Large Object Test: Here we are pushing the boundaries to test how the libraries behave in an extreme case. The object to be processed has 100,000 elements. In this case, the nesting restriction was set to two and the maximum size for the lists and nested objects was set to 5. The generated file has 25MB of data and can be downloaded from GitHub.
Benchmarking Methodology
In order to measure the time as accurately as possible, we are going to use one of the features available in the C++11 standard. This is the chrono library and in particular the steady_clock. According to C++ Reference,
For each of the benchmarks, we are going to take the time immediately before executing 1,000 times the action to be tested. Once the loop has finished, the current time will be taken again. We obtain the average time of the tested action by dividing the interval between the two measurements by the the number of times the action was executed. The unit that we'll be using for all the measurements are milliseconds.
In order to reduce the I/O subsystem interference, in the parsing benchmarks the file will be loaded into a string and parsed from there. For the serialization tests, the generated strings are not saved into files for the same purpose.
The source-code of the benchmark-runners can be downloaded from GitHub here.
Parsing Benchmarks Results
The following are the results for the parsing tests. The lower the amount of time it takes to process, the better the library.
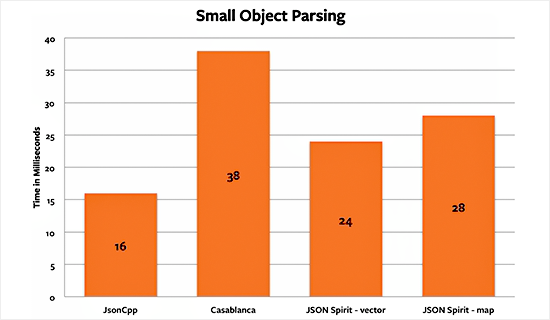
It is clearly visible who the winner is in this case: JsonCpp. The difference between this and the second fastest library, JSON Spirit's vector implementation, was 50%. Casablanca was the worst performer at this test, taking almost 2.5 times more than JsonCpp and 35% more than the nearest competitor.
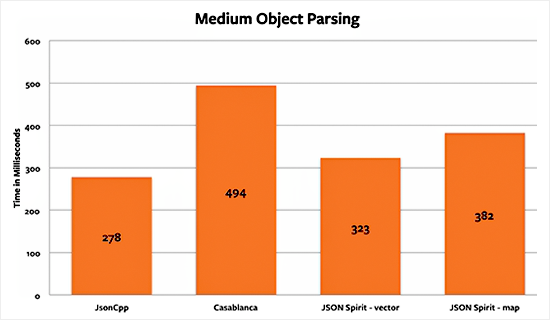
The medium dictionary parsing benchmark results show similar results as the last benchmark. JsonCpp has still an advantage over the rest. Although this time the difference between JsonCpp and JSON Spirit’s vector implementation is tighter, only 16%. The difference between Casablanca and JSON Spirit is the same as when parsing the small object.
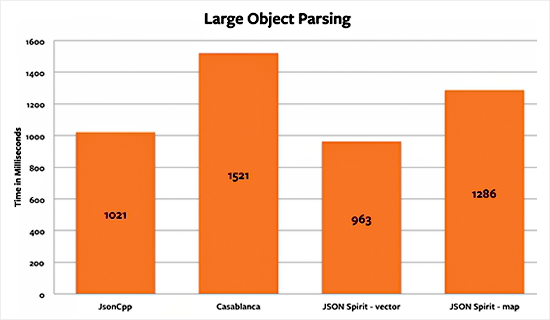
The large object benchmark shows that when dealing with a large number of keys the JSON Spirit vector implementation is faster than the JsonCpp one. This is to be expected as inserting in the back of vector is faster than an insertion in a map, the underlying structure for JsonCpp.
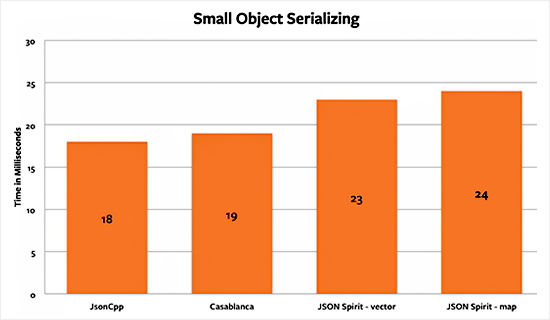
Serialization Benchmarks
From the serialization benchmarks we can tell that JsonCpp and Casablanca are tied. For small objects, both libraries have the same efficiency at serializing. When dealing with the medium-size dictionaries, JsonCpp has a slight advantage of around 8%. But in the large-object serialization test, Casablanca is the winner with an advantage of 7.6%.
JSON Spirit’s map serialization speed was the one that performed the worst, particularly in small and large objects. It is 20%-30% slower than JsonCpp and Casablanca.
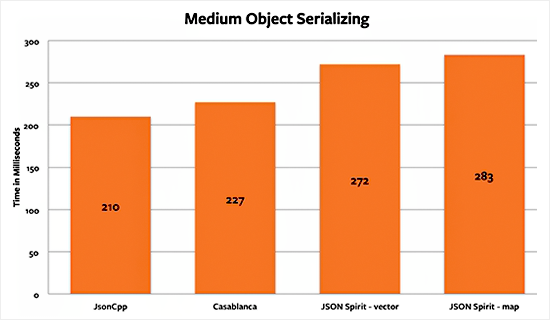
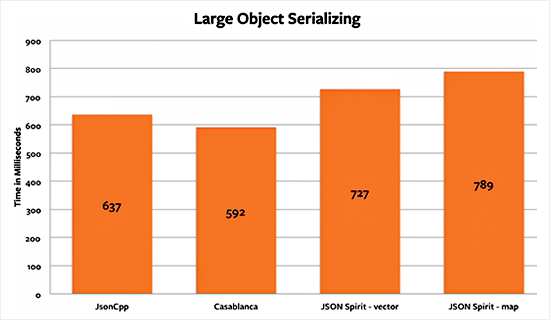
Based on the results of the benchmarks, we can state that JsonCpp is the best option for general JSON usage. It has performed better than the other two libraries for both parsing and serializing. The downside of using jsonCpp is that you need to use the repo version and not the release version because it’s out of date and several improvements have been made in the development branch. If you have any questions or came up with a different conclusion, let me know in the comments section below.









