[Oct 8, 3:15 pm PT]
ThousandEyes tests confirm there was a second, separate issue with Facebook apps & services today that is now resolved. Unlike the Oct. 4 outage (see analysis below), Facebook and Instagram were reachable, but tests showed increased server errors and that the applications were running very slow for some users, in some cases failing to load.
[Oct 6, 10:10 am PT]
Facebook has published a more detailed report of the incident, which fully aligns with the analysis provided below. Facebook’s statement that their backbone network went down prior to DNS is consistent with our finding that receive errors were globally seen before DNS went down and for some time after DNS service was restored. Read on for a full account of what we saw.
Additionally, we’ve now published a new episode of The Internet Report, which dives deeper into their incident report, and also calls out the lessons to be learned from this outage.
[Oct 5, 10:45 am PT]
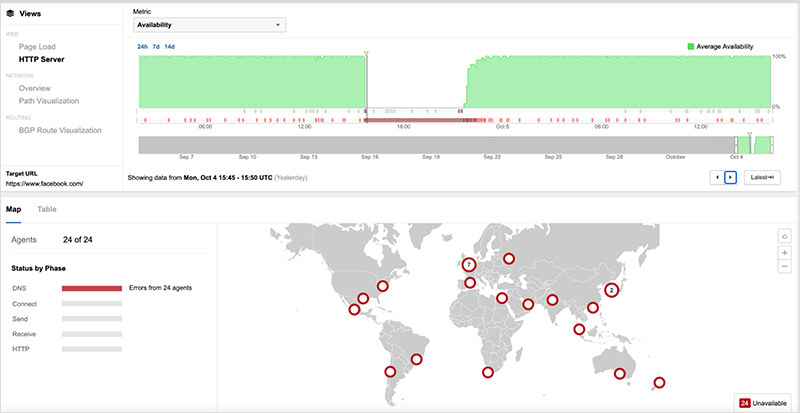
On October 4th, between approximately 15:40 UTC - 22:45 UTC, Facebook suffered one of the largest outages on record for a major application provider in terms of breadth and duration as Facebook, Instagram, and WhatsApp were offline and unavailable globally for more than seven hours. While the DNS failures could have caused the apps to go offline, Facebook’s large-scale BGP route withdrawals precipitating the incident, along with other signals, point to issues that impacted Facebook more broadly.
At a minimum, the unprecedented length of the outage should be seen as an indication that the issue went beyond simply a DNS service outage. Something significant occurred that not only took down their internal DNS service, but also prevented a highly sophisticated network operations team supporting the most highly trafficked site on the Internet from resolving the issue in short order.
Facebook Engineering has published a blog sharing some details about the events that unfolded, which you can read here. In this post, we’ll attempt to answer some of the most common questions we’re getting by unpacking the outage from multiple angles. Later today, we’ll be publishing an episode of the Internet Report where we’ll cover not only what happened and its impact, but also the precipitating event, takeaways, and lessons to be learned.
First of all, why is DNS important and what happened to Facebook’s internal DNS service?
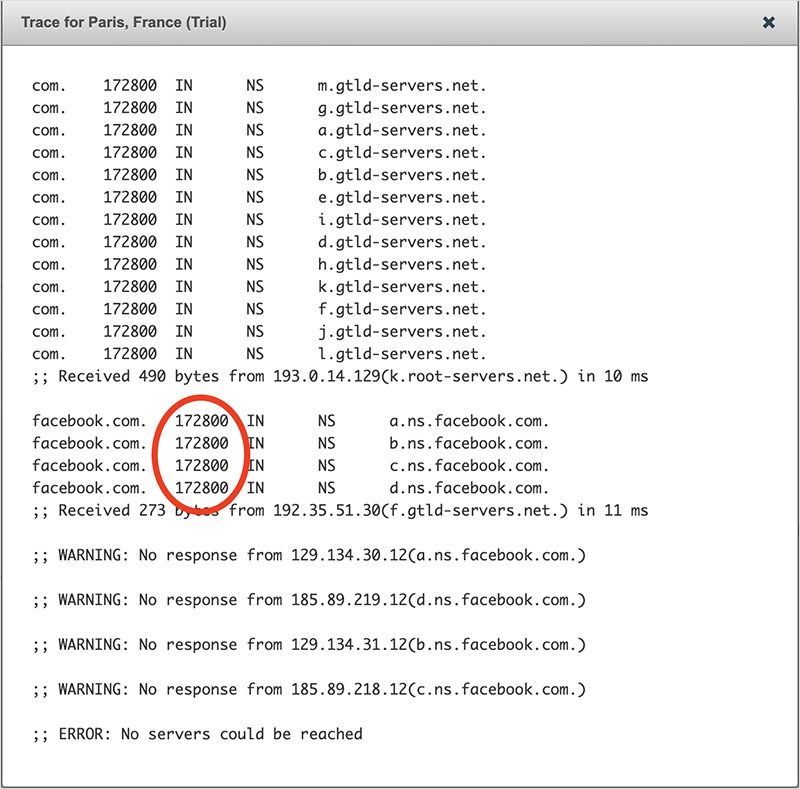
DNS is the first step in reaching any site on the Internet. Its failure would prevent the reachability of a site, even if the site itself and the infrastructure it was hosted on was available. In the case of Facebook, they internally host their DNS nameservers, which store the authoritative records for their domains. Facebook maintains four nameservers (each served by many physical servers) — a, b, c, and d — as seen in figure 1.

Each of those nameservers is covered by a different IP prefix, or Internet “route” (more on that later), covering a range of IP addresses.
At approximately 15:40 UTC, Facebook’s service started to go offline, as users were unable to resolve its domains to IP addresses through the DNS.
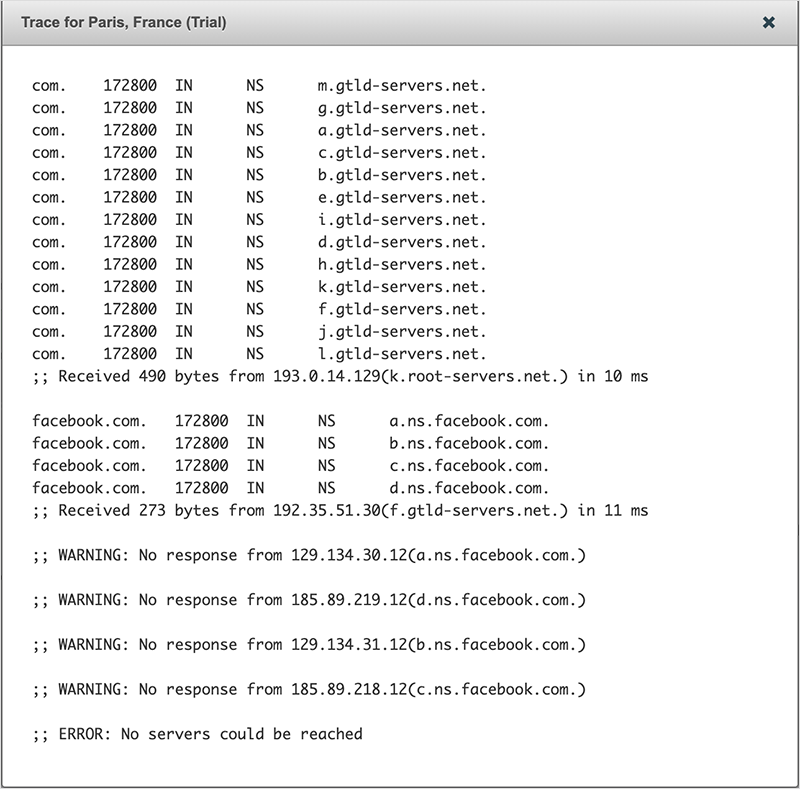
As this was happening, we could also see that queries through the DNS hierarchy for the facebook.com A record were failing due to Facebook’s nameservers becoming unreachable (see figure 3).
Now, a word on the DNS. The DNS is so critical to the reachability of sites and web applications, that most major service providers don’t mess about with it. For example, Amazon stores the authoritative DNS records for amazon.com not on its own infrastructure (which, as one of the top public cloud providers, is amongst the most heavily used in the world), but on two separate external DNS services, Dyn (Oracle) and UltraDNS (Neustar) — even though Amazon AWS offers its own DNS service.
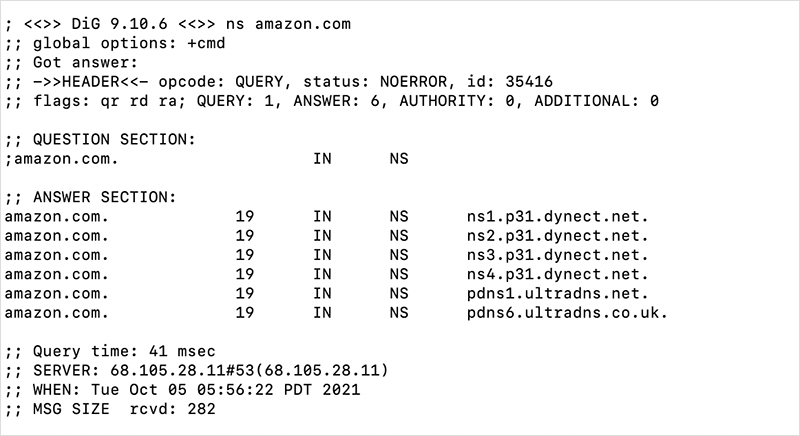
Not only does Amazon use external services to host its records, it notably uses two providers. Why is this notable? As a critical Internet infrastructure, DNS has, notoriously, been targeted for attack by malicious actors, as in the case of the massive DDoS attack on Dyn in 2016 or the route hijacking of Amazon’s DNS service Route 53 in 2018. By hosting with two different providers, Amazon can ensure that its site is reachable even if one of its providers were to be unavailable for whatever reason.
Why didn’t Facebook move their DNS records to an external DNS service provider and get their services back online?
Nameserver records, which are served by top level domain (TLD) servers (in this case, com. TLD) can be long-lived records — which makes sense given that app and site operators are not frequently moving their records around — unlike A and AAAA records, which often change very frequently for major sites, as the DNS can be used to balance traffic across application infrastructure and point users to the optimal server for their best experience. In the case of Facebook, their nameserver records have a two day shelf life (see figure 5), meaning that even if they were to move their records to an external service, it could take up to two days for some users to reach Facebook, as the original nameserver records would continue to persist in the wilds of the Internet until they expire.
So moving to a secondary provider after the incident began wasn’t a practical option for Facebook to resolve the issue. Better to focus on getting the service back up.
Why did Facebook’s internal DNS service go down in the first place?
Like DNS, BGP is one of those scary acronyms that frequently comes up when any major event goes down on the Internet. And like DNS, it is essential vocabulary for Internet literacy. BGP is the way that traffic gets routed across the Internet. You can think of it as a telephone chain. I tell Sally (my peer) where to reach me. She in turn calls her friends and neighbors (her peers) and tells them to call her if they want to reach me. They in turn call their contacts (their peers) to tell them the same, and the chain continues until, in theory, anyone who wants to reach me has some “path” to me through a chain of connections — some may be long, some short.
Moments before the outage, at approximately 15:39 UTC, Facebook issued a series of BGP route withdrawals covering hundreds of its prefixes — almost all immediately reversed — that effectively removed its DNS nameservers from the Internet. Depending on where Internet Service Providers sat on the Internet, they would have seen these route changes almost immediately or up to ten minutes later.
While most of the withdrawn routes were readvertised, those covering its DNS nameservers were not (with one exception). Prior to the outage, seven (IPv4) prefixes covering its internal DNS service were actively advertised (see below):
129.134.0.0/17
129.134.30.0/23
129.134.30.0/24
129.134.31.0/24
185.89.218.0/23
185.89.218.0/24
185.89.219.0/24
The key routes above are the /24 ones, since those are more specific and would have been preferred. The /23 prefixes are umbrella or “covering” prefixes for the /24 prefixes. Finally, a /17 covers 129.134.30.0/23, 129.134.30.0/24, and 129.134.31.0/24 prefixes — a covering route for Facebook’s nameservers ‘a’ and ‘b’. All vanished from global routing tables on or about 15:39 UTC, with the exception of the /17 (more on that later).
To illustrate how this outage was experienced from the standpoint of ISPs and transit providers, who route user traffic to Facebook, we took a snapshot of Cogent’s routing table as it was before the outage at 12:00 UTC on October 4th and during the outage at 16:00 UTC. Facebook had 309 prefixes advertised at 12:00 UTC and 259 prefixes at 16:00 UTC. Only the following prefixes were “missing”:
129.134.25.0/24
129.134.26.0/24
129.134.27.0/24
129.134.28.0/24
129.134.29.0/24
129.134.30.0/23
129.134.30.0/24
129.134.31.0/24
129.134.65.0/24
129.134.66.0/24
129.134.67.0/24
129.134.68.0/24
129.134.69.0/24
129.134.70.0/24
129.134.71.0/24
129.134.72.0/24
129.134.73.0/24
129.134.74.0/24
129.134.75.0/24
129.134.76.0/24
129.134.79.0/24
157.240.207.0/24
185.89.218.0/23
185.89.218.0/24
185.89.219.0/24
2a03:2880:f0fc::/47
2a03:2880:f0fc::/48
2a03:2880:f0fd::/48
2a03:2880:f0ff::/48
2a03:2880:f1fc::/47
2a03:2880:f1fc::/48
2a03:2880:f1fd::/48
2a03:2880:f1ff::/48
2a03:2880:f2ff::/48
2a03:2880:ff08::/48
2a03:2880:ff09::/48
2a03:2880:ff0a::/48
2a03:2880:ff0b::/48
2a03:2880:ff0c::/48
2a03:2881:4000::/48
2a03:2881:4001::/48
2a03:2881:4002::/48
2a03:2881:4004::/48
2a03:2881:4006::/48
2a03:2881:4007::/48
2a03:2881:4009::/48
69.171.250.0/24
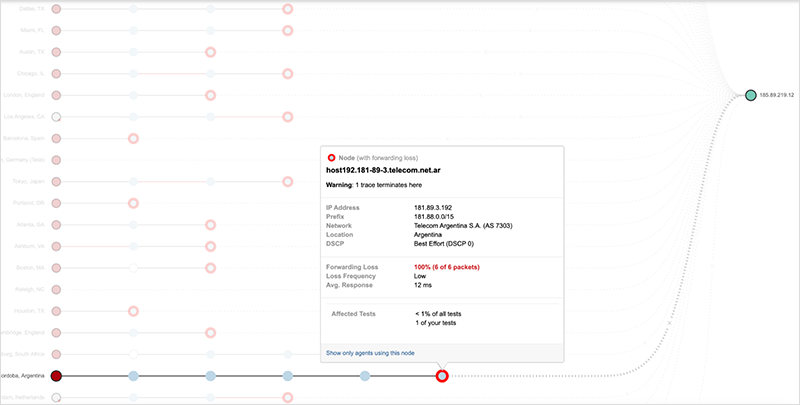
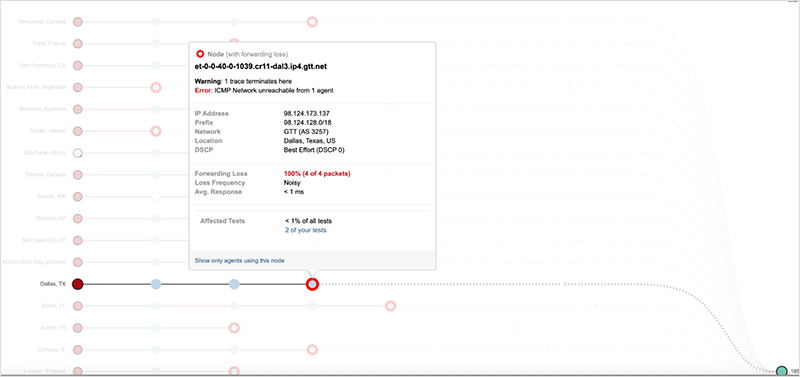
All of these prefixes covered Facebook nameservers, with the exception of the last one. Figure 6 shows traffic destined for nameserver ‘c’ getting dropped by the first Internet hop, as the service provider had no route in its routing table to get the traffic to its destination.
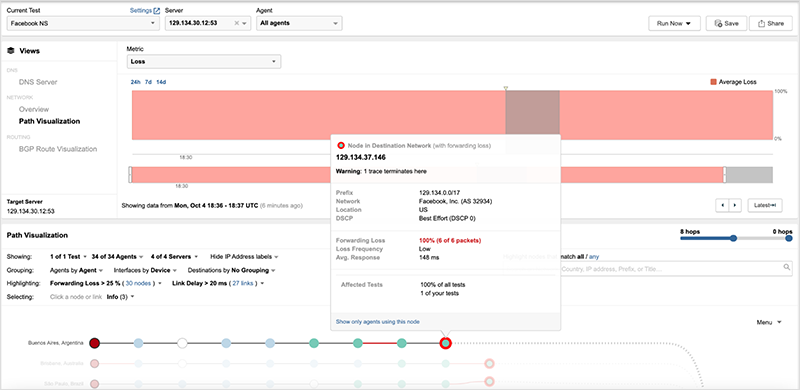
The /17 prefix covering 50 percent of Facebook’s DNS and was still advertised and in service provider routing tables, but as seen in figure 8, all traffic destined to Facebook nameserver ‘a’ via that route was dropped at Facebook’s edge.
The reason why this advertised route failed could be because it wasn’t set up to handle traffic to the DNS service (since a /23 and, more importantly, /24s were actively used before the outage) — or it could indicate that there was an issue in Facebook’s network, perhaps preventing traffic from routing internally. Similar behavior was seen during a major outage within Google’s network in 2019. In that incident, BGP advertisements continued to route traffic to their network, but the traffic dropped at Google’s network edge because their internal network was disabled and the border routers had no internal routes to send traffic to destination servers.
You can read our analysis of the Google outage here.
Finally, to provide a fuller picture of the state of Facebook’s network, let’s look at the final prefix on the list of withdrawn routes, the 69.171.250.0/24, which is one of the many prefixes for facebook.com. This route wasn’t withdrawn in the same way that the DNS prefixes were. Figure 9 shows the impact of the significant and continuous route flapping for that prefix throughout the outage, effectively rendering that route unusable.
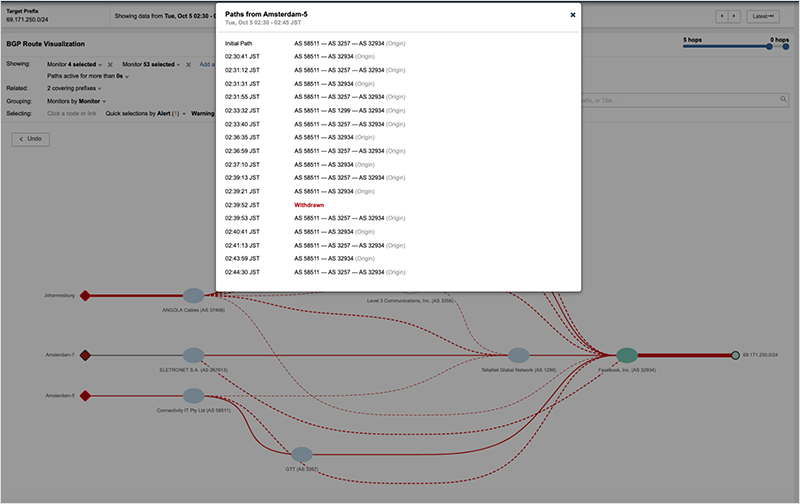
The fact that this route instability was left in place for so long is perhaps an indication that something beyond the DNS service was amiss. But before we get to that, let’s take a detour down BGP lane.
So why did Facebook withdraw routes to its service in the first place?
While we don’t know the specific reason for the configuration update that sparked this incident, route withdrawals and changes are not uncommon.
BGP isn’t just the way traffic gets routed across the Internet. It’s also a powerful tool for network operators to shape the flow of traffic to their services. BGP changes are a normal part of operations in the running of a highly trafficked network. Reasons range from making changes to a service (for example, routing traffic to a different prefix to perform maintenance on some part of the service), traffic engineering to optimize performance for users, changing peers, changing the nature of a peering relationship, and other operational activities. Routes can also accidentally get withdrawn due to network configuration updates gone wrong, router bugs, or changes meant for a single peer getting pushed out broadly.
Why was Facebook unable to restore routes to its service for more than seven hours?
Go ahead, blame the network. Even if DNS was the domino that toppled it all, and even if a rogue set of BGP withdrawals was the source of that toppling, like any BGP route change, it can be changed again. Or can it? History tells us that the longest lived and most damaging outages can most often be laid at the feet of some issue with the control plane. Whether through human error or bug, if the mechanism for network operators to control the network — to make changes to it — is damaged or severed, that’s when things can go very very wrong. Take the aforementioned Google outage. In that incident, which lasted about four hours, a maintenance operation inadvertently took down all of the network controllers for a region of Google’s network. Without the controllers, the network infrastructure was effectively headless and unable to route traffic. Google network engineers were unable to quickly bring the network back online because their access to the network controllers depended on the very network that was down.
Lack of access to the network management system would certainly have prevented Facebook from rolling back any faulty changes. Access could have been due to some network change that was part of the original route withdrawals that precipitated the outage, or it could have been due to a service dependency (for example, if their internal DNS was a dependency for access to an authentication service or other key system).
Regardless, even after DNS was restored (and shortly before it failed), we observed connection issues to facebook.com. Connection issue post-incident could be due to Facebook servers getting overwhelmed as they worked to build to full capacity (see figure 10), or it could point to broad issues within Facebook’s network.
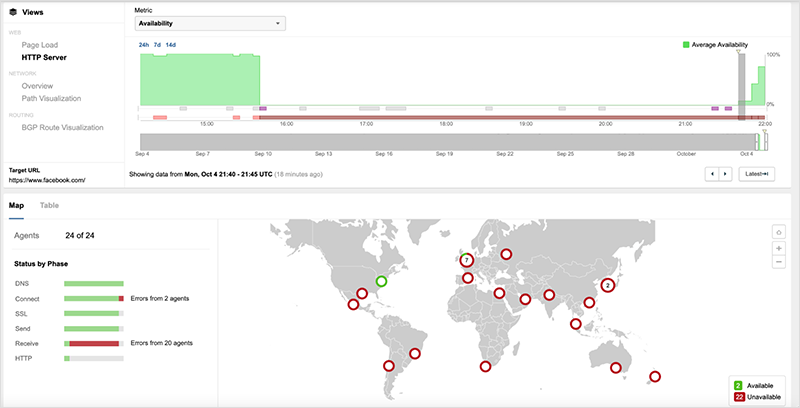
Notably, connection issues were observed immediately before DNS went down (see figure 11).
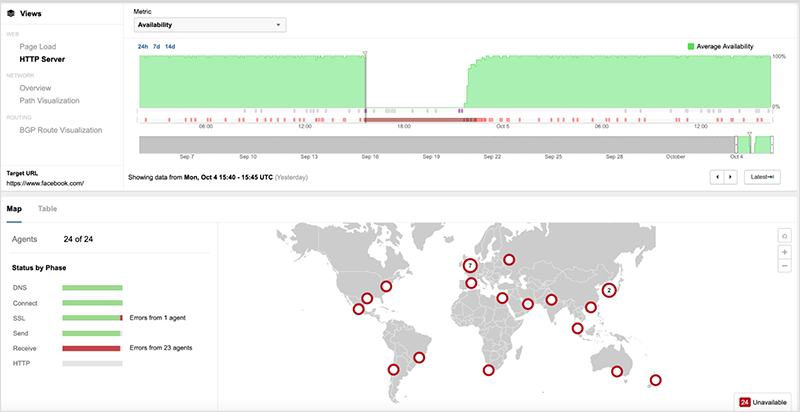
Why were there so many other network issues reported yesterday, too?
Even apart from the millions of users impacted, reports of issues with services providers were rife during the outage. ISPs and transit providers would have been impacted in a couple of ways. First, Facebook accounts for significant amounts of Internet traffic volumes — and all the queries to its DNS servers would have been dropped by providers, since they had no routes to that service. At the same time, greater volumes of DNS queries (and, thus, network traffic) would have been hitting both DNS providers (and ISPs) since the DNS is inherently resilient, and when queries to one nameserver failed, DNS resolvers would have tried the other nameservers — to no avail. What would ordinarily be a single query, would have been quadrupled during the outage. Not to mention all those browser refreshes generated by anxious users trying to reach the site. Facebook’s CTO also reportedly alluded to the stress on its network post-incident in an email to its employees.
When did the incident end?
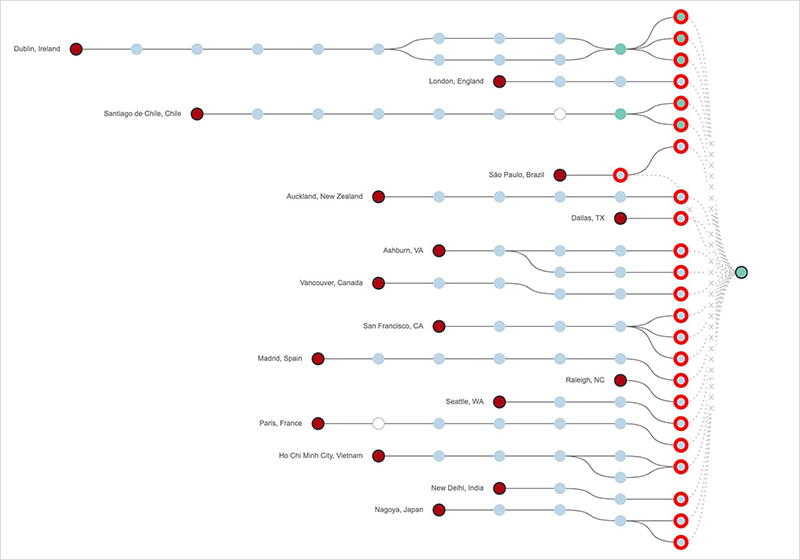
The DNS service started to come back online around 22:20 and by approximately 22:45 the incident was effectively over, with most users able to reach Facebook, as seen in figure 12.
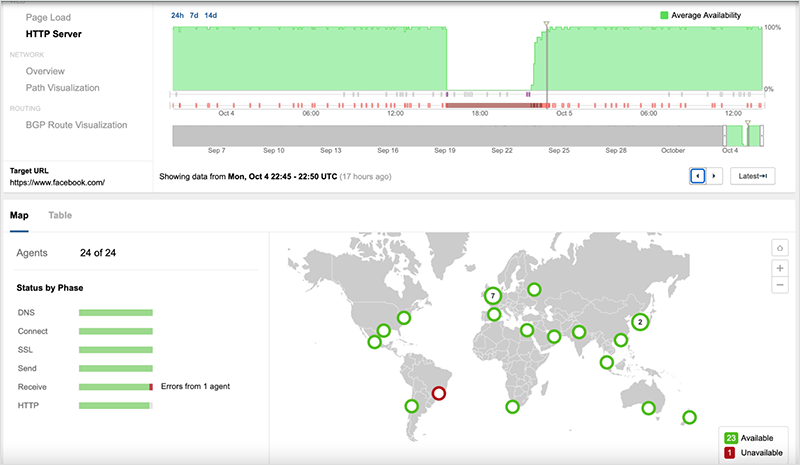
Lessons Learned
Be sure to check back later today for more on this front. We’ll be releasing a new episode of the Internet Report, where we’ll walk through what we’ve discussed in this post, but also discuss some of the key takeaways and lessons learned.
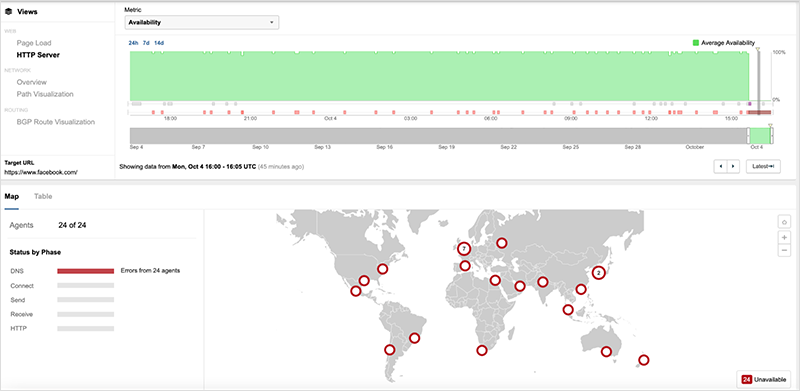
[Oct 4, 3:15 pm PT] Facebook’s DNS service appeared to be fully restored by approximately 21:30 UTC and Facebook.com is now reachable for most users.
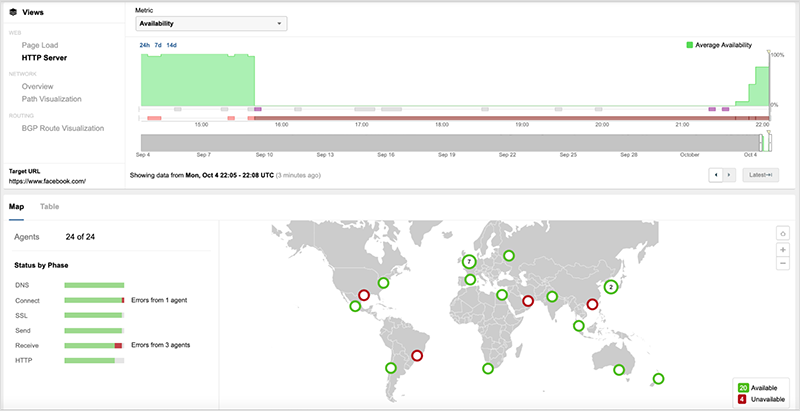
[Oct 4, 12:15 pm PT] Facebook made BGP withdrawals near the time of the incident, however, 2 prefixes covering two of their 4 DNS nameservers (a and b) are still being advertised across the Internet. They are reachable on the Internet but traffic is dropping at Facebook’s network edge.
The 2 DNS nameservers (a and b) are reachable because covering prefix 129.134.0.0/17 is still being advertised, but this advertisement may not have been designed to support the nameserver service.
The 3 specific prefixes covering a and b nameservers before the incident were 129.134.30.0/23, 129.134.30.0/24, 129.134.31.0/24. The specific routes covering all 4 nameservers (a-d) were withdrawn from the Internet at approximately 15:39 UTC.
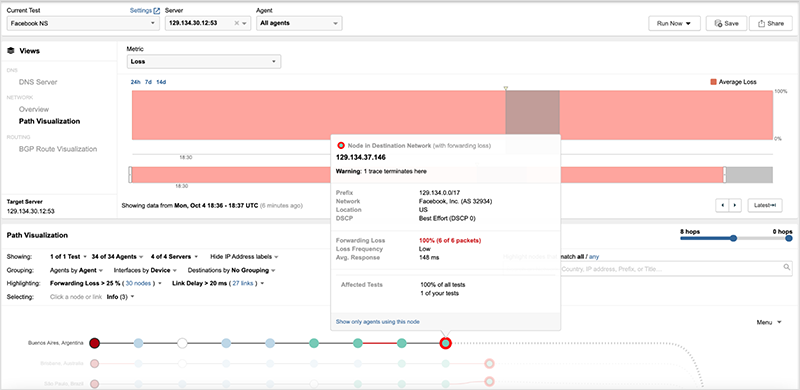
[Oct 4, 10:15 am PT] ThousandEyes tests can confirm that at 15:40 UTC on October 4, the Facebook application became unreachable due to DNS failure. Facebook’s authoritative DNS nameservers became unreachable at that time. The issue is still ongoing as of 17:02 UTC.