This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for firsthand commentary.



Internet Outages & Trends
Load is a fundamental but, at times, challenging variable for networks and operations teams to handle. In the past fortnight, ThousandEyes observed various load-related problems that took a toll on carriers and businesses.
Some of the problems exhausted available capacity and overtook the provider’s ability to spin up more. Google Cloud reported it could not provision extra metadata infrastructure resources fast enough to meet an “unexpected spike in demand”; similarly, Front reported that users were unable to load the application due to a “large unexpected increase in web traffic” on the provider’s end.
For others, the problem wasn’t extra capacity—it was capacity, full stop. At AT&T and a collection of banks in Australia, the concern was recovering infrastructure to serve regular customer loads, as network problems left core services unavailable.
Variations in load are often indicative of the presence of deeper issues. For example, Minnesota State University Moorhead reportedly noticed a change in server performance, and, in their investigations, they discovered a previously undetected cyber incident.
Read on to learn about all these outages and degradations, or use the links below to jump to the sections that most interest you:
-
Box experiences outage as third-party network component fails
-
Australian banks appear to lose online and app-based services for 24 hours
-
Minnesota State University Moorhead’s case study on good visibility
AT&T Outage Impacts Cellular Services Nationwide
On February 22, AT&T reported that their cellular services were impacted for some users. Experienced by users across the United States, the outage appeared to be related to a centralized upgrade effort that was being undertaken by the company. The disruption began at approximately 3:30 AM EST (8:30 AM UTC) on the U.S. East Coast. While disruptions can occur at any time, the specific time of day (carriers tend to perform customer-impacting work during off hours) combined with a notification that expansion work was underway, suggests that this upgrade effort was likely related to the outage. AT&T prioritized restoration, starting with critical first-responder services. Cellular services appeared to be restored in stages throughout the day, with full restoration occurring approximately 11 hours after the outage was first observed.
AT&T attributed the outage’s root cause to an incorrect process that was executed during the expansion of its network. The outage appeared to affect only cellular services, including data services running over the cellular network. Some customers reported that their mobile phones were stuck in “SOS mode,” indicating that the devices were unable to complete the connection to the core network or any other cellular or Public Switched Telephone Network (PSTN) services. As a result, customers were unable to access voice or data services. Initially, there were rumors that other wireless carriers were also impacted; however, these reports were coming from customers of other networks who were not able to reach AT&T users.
Based on the reported impact and characteristics of the outage, it is reasonable to assume that the outage was caused by a software action at an aggregating point, such as the handoff between cellular and other networks. Throughout the duration of the outage, ThousandEyes observed that the AT&T core IP network was available and functioning, implying that enterprise customers leveraging the IP core were unaffected. The outage appeared to only impact some consumers on cellular networks.
Google Cloud Metadata Store Faces Sudden Demand Spike
On February 14, Google Cloud customers in its us-west1 region experienced sporadic disruption due to issues with a regional metadata store in that location. As Google explained, “The metadata store supports critical functions such as servicing customer requests and handling scale, load balancing, admin operations and for retrieving/storing metadata including server location information.”
While the metadata store uses load balancing and autoscaling to keep pace with metadata requests, “an unexpected spike in demand exceeded the system’s ability to quickly provision additional resources. As a result, multiple Google Cloud products and services in the region experienced elevated latencies and errors until the unexpected load was isolated,” Google stated in its post-incident report. A large number of AI and machine learning-based services were impacted.
Unable to handle the spike in load, the metadata store experienced intermittent performance degradation, which prevented certain actions such as deletion and storage of data. The failure was sporadic but caused total disruption for just over three hours. Tests by ThousandEyes indicate that there were some small delays in load time, but the overall impact on customers was negligible.
Front’s “Large Unexpected Increase in Web Traffic”
Collaboration and workflow automation service provider Front experienced a disruption on February 18 due to what it says was a "large unexpected increase in web traffic.” The disruption manifested to users as “problems loading the application.” ThousandEyes observations confirm the cause was indeed load-related. Looking at the timing (a Sunday in the U.S.) and the geographic scope, the increase in traffic does not appear to have been nefarious in nature. Instead, it may have been the result of something like a race condition brought on by a software change or patch update that was applied internally.
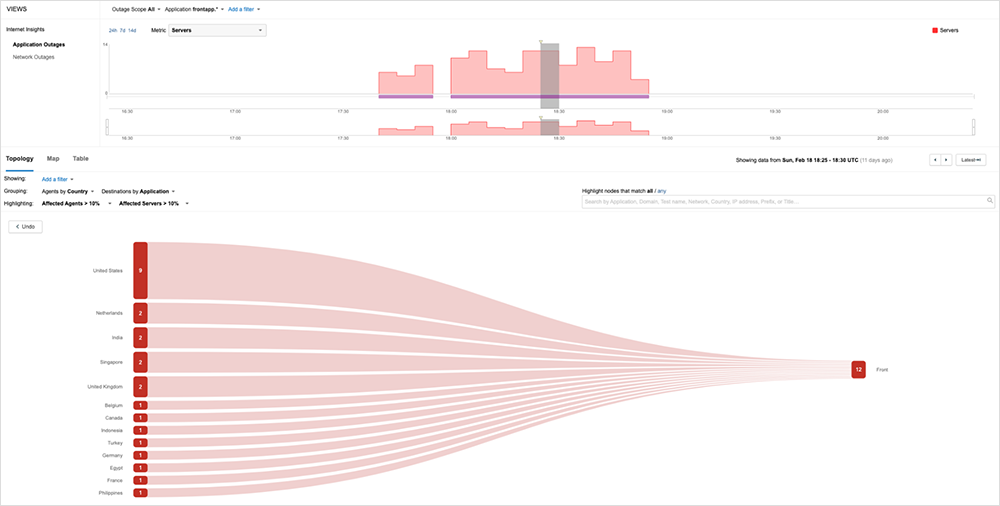
Explore this disruption in the ThousandEyes platform (no login required).
Box Experiences Outage as Third-party Network Component Fails
Some users of the cloud storage and collaboration service Box were unable to log in for about 30 minutes on February 14. ThousandEyes observed errors and timeouts when accessing the service, indicating that network connectivity to Box’s “front door” was fine but that a backend problem existed, causing login attempts to fail.
A preliminary post-incident report by Box confirms that there was a backend issue on a third-party-hosted component that was powering part of the single sign-on (SSO) process: “The issue occurred as a result of a temporary failure of an underlying network component provided by one of [Box’s] third-party service providers. The issue self-resolved when the service provider addressed the issue.”
Australian Banks Appear To Lose Online and App-based Services for 24 Hours
A number of banks in Australia, including Ubank, Bank Australia, Defence Bank, Beyond Bank, People's Choice, and P&N Bank, experienced an outage that manifested to customers as a loss of access to their banking apps and an inability to make online transfers. Impacts from the disruption appeared to last for up to 24 hours—including a full business day in Australia.
The outages had similar symptoms and a potential common aggregation point emerged: Data Action, a provider of core services and Internet and app-based banking. Data Action reported a network outage on its end, and that it had “logged a series of incidents” that impacted its clients and its clients’ customers.
Minnesota State University Moorhead’s Case Study on Good Visibility
On February 1, IT teams at Minnesota State University Moorhead observed some of their server infrastructure wasn’t performing as expected. They initially suspected a network fault. To take control of the situation, teams proactively took servers, networks, and systems offline to troubleshoot. Networks and networked services were progressively switched back on over the following weeks, a process that eventually led to the discovery of an infection on a handful of servers. The incident illustrates what good observability looks like: the ability to identify atypical performance of a system or asset, and to use that as an early indicator of a problem that needs to be investigated and resolved.
By the Numbers
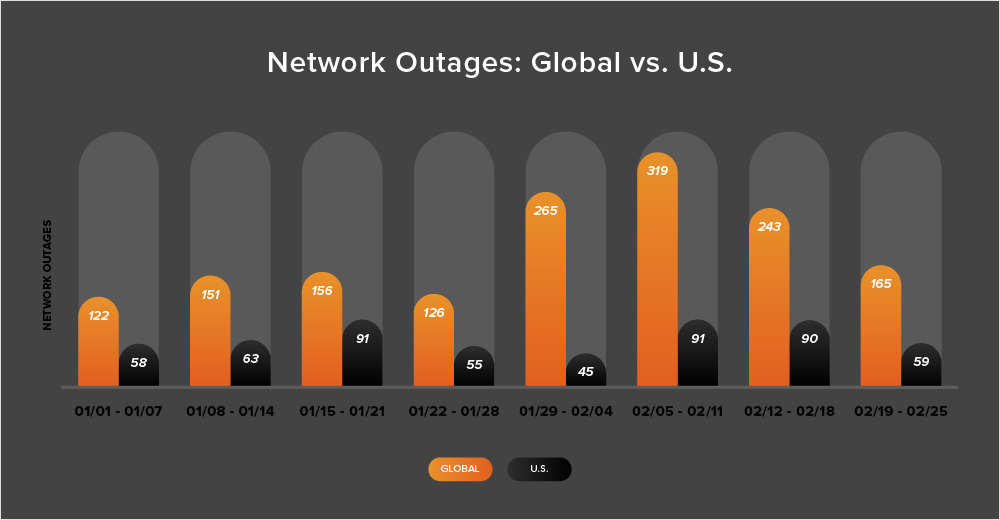
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (February 12-25):
-
After a slight increase at the beginning of February, the total number of global outages decreased throughout the latter portion of the month. During the week of February 12-18, the number of outages dropped from 319 to 243, a decrease of 23%. The following week (February 19-25) saw a further decrease of 32%.
-
There was a similar story in the United States, where outages initially decreased slightly from 91 to 90 (a 1% drop compared to the previous week), before decreasing by 34% the following week (February 19-25).
-
During the period of February 12-25, only 37% of all observed outages were based in the United States. This marks the second consecutive two-week period where U.S.-centric outages accounted for less than 40% of all observed outages—the first time in almost a year that two consecutive periods have been observed in which U.S. outages accounted for less than 40%.