


After a brief hiatus, The Internet Report returns in a refreshed bi-monthly format, but with the same insights and analysis on outage and disruption events that you’ve come to expect. Let’s resume by analyzing a series of power problems that led to some shutdowns of IT systems. But, before discussing that, let’s look back at the outages over the previous months.
Internet Outage Trends
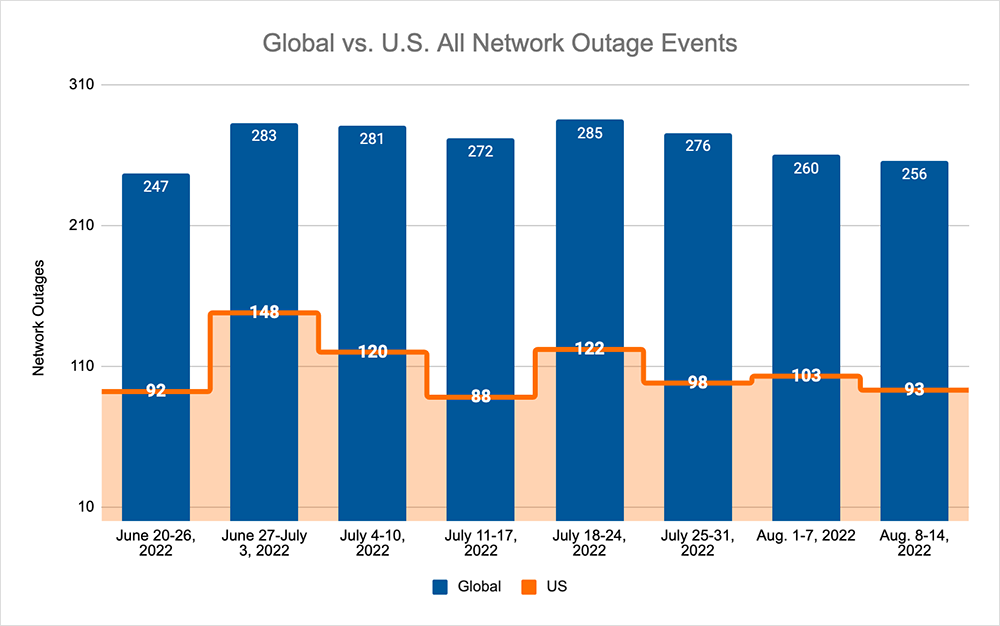
In July, we saw global outages rise from 247 to 283 — a 15% increase compared to the previous week. This was reflected in the U.S., where outages rose from 92 to 148 — a 61% increase compared to the previous week. This was followed by two consecutive weeks of decreases, with total global outages dropping from 283 to 272 — a 4% decrease when compared to the week beginning June 27th. This downward trend was again reflected domestically in the U.S., where outages dropped from 148 to 88 — a 41% decrease compared to the week beginning June 27th.
This downward trend came to an end the week beginning July 18th, with total outages rising from 272 to 285 — a 5% increase — and U.S. outages rising from 88 to 122 — a 39% increase when compared to the week prior. This increase was immediately followed by three weeks of successive decreases, with total outages dropping from 285 to 256 — a 10% decrease compared to the week beginning July 18th. However, this trend was not reflected in the U.S. outages, where an initial drop from 122 to 98 — a 20% decrease compared to the previous week — was then followed by an increase in outages, rising from 98 to 103 — a 5% increase when compared to the week beginning July 25th, before again dropping from 103 to 93 — a 10% decrease compared to the previous week.
A Summer of Power Outages
It’s actually quite rare these days to read about data center incidents. After all, these are facilities that, for decades, have been designed to be fault resilient, often with two (or more) sets of independent power sources to ensure service continuity.
Best practice dictates regular test runs of secondary power infrastructure—the uninterruptible power supply (UPS) batteries and generators—to try to ensure the data center’s load fails over correctly to backup power in the event the main power is out. Of course, despite best intentions and regular failover test runs, reports of a power loss leading to a partial or entire data center outage are not uncommon; situations where the UPS fails to pick up compute load while the generator starts, or perhaps more commonly, where the generator fails to start up, leaving servers without an alternative power source altogether.
The past several weeks have seen several data centers experience outages, due to either a loss of power or a loss of cooling (which led to racks and floors getting powered down).
On July 28, a 20-minute power loss in one availability zone of AWS US-EAST-2 led to hours of problems for some customers. It wasn’t just EC2 instances that were impacted; the outage took out dozens of AWS services, as well, and that interrupted a lot of backend processes. Customers who use one of these services as an architectural component of a web application or process might have seen that the entire app or process stopped working. Applications like Webex, Okta, Splunk, BambooHR, and others were all affected to some degree by this scenario.
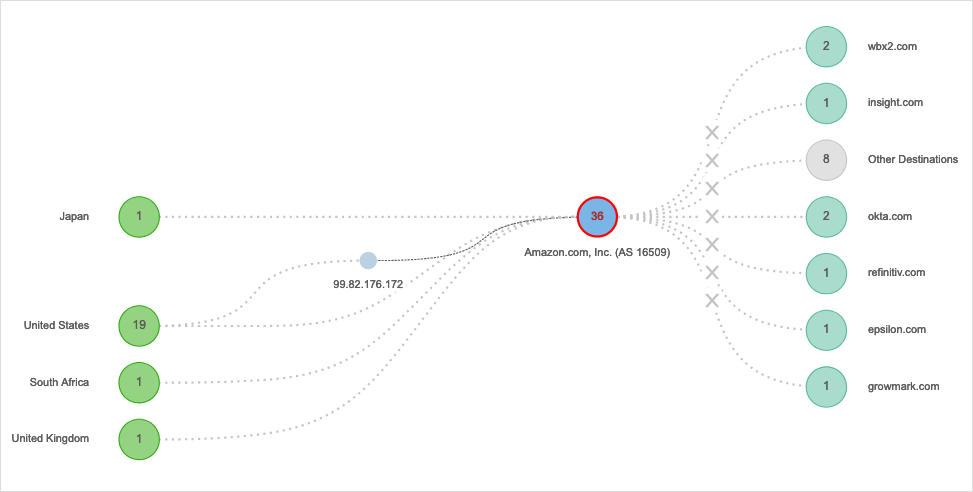
It’s unclear what led to the initial loss of power in part of the data center, as a detailed post-incident report hasn’t been circulated. However, it’s clear the shutdown led to a lengthy recovery time for some customers, particularly for those who rely heavily on the affected AZ.
We often discuss the importance of redundancy in cloud setups in case something goes wrong. Still, the reality is that redundant capacity in the cloud can be expensive, and it may not be an option for smaller organizations. For companies that can’t justify multi-AZ or multi-region redundancy, it is critical that they improve their visibility into their setups so they can detect the start of problems early. Visibility, in this case, may be the most cost-effective insurance policy for cost-constrained public cloud users.
Also, in July, heatwave conditions in the UK caused cooling system problems at data centers run by Oracle and Google Cloud. These sites didn’t lose power; but losing cooling made the end result much the same. Google reportedly suggested in advisories that it had powered down some parts of its infrastructure to prevent equipment from being fried. That suggests a more coordinated shutdown, but still one that left customers without juice to run their cloud instances.
Cooling failures in extreme heat are not unheard-of events. Australia has previously seen facilities shut down because cooling systems (main and ancillary) could not handle the ambient temperatures. The country has also previously seen data centers powered down due to floods, which caused utilities to shut off the main power (and where running any sort of backup power to water ingress-impacted floors is obviously a bad idea).
There’s a range of reasons why power to a facility may be cut, and even facility operators with deep pockets for resiliency and redundancy may not escape all of the time. As a customer of these centers, being able to see when your workloads start to wobble is crucial. At worst, it can buy time to warn of downstream impacts; at best, it could be the early warning system needed to initiate failover or your own business continuity plan.
One More for the Teams
There was also a noteworthy application outage for Microsoft Teams on July 20. The span of the impact was global, though due to the time-of-day the incident occurred, the Asia Pacific region was most heavily affected. The impact also widened to more Microsoft online services as time went on. First observed around 9:15 PM EDT, the outage, which lasted around 3 hours, appeared to impact users' ability to access the service. However, network connectivity to the service did not appear to experience any significant issues throughout the outage.
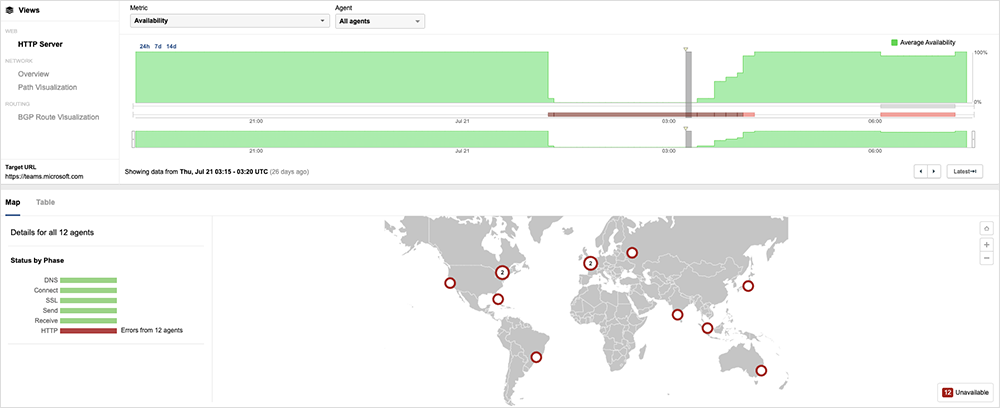
According to Microsoft’s statement on Twitter, the official cause was a bad deployment that “contained a broken connection to an internal storage service,” which they remediated by rerouting traffic to an alternate region in an effort to restore functionality to the service. The interesting thing about the recovery was that it appeared to be very controlled. ThousandEyes monitoring shows users were returned to service in a series of “steps.” It appears that Microsoft may have been keen to return service to the most likely active impacted users first.









