This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
With the architecture of platforms and environments as complex as they are today, enterprises and governments have made concerted efforts to scenario-test as many eventualities as possible—with the express intent of being prepared, should something happen.
But the reality is, not every contingency can be planned for. This fortnight, we saw real-life examples of unexpected and outlier scenarios impacting key services. Extended timelines were a factor in two of the incidents: a reported delay in deploying an infrastructure-as-code change at GitLab, and “extreme caution” that may have led to a longer timeframe when rectifying a capacity issue at Microsoft’s Azure. In both instances, customer experience was diminished unexpectedly.
While it’s impossible to plan for any and every outage scenario, what’s important is having visibility so you can recognize things are going wrong, pinpoint the root cause, and action a remediation or fix. This applies to both the service owner and customer. Importantly, good visibility creates a window of time where a provider may be able to route around an issue to minimize impact, or where a customer may be able to switch over to a backup or an alternative platform to maintain business continuity.
Read on to learn more and explore some recent outages and performance degradations, or use the links below to jump to the sections that most interest you.
GitLab Outage
On July 7, users of popular DevOps platform GitLab experienced a nearly four-hour disruption, “encountering 503 errors when interacting with the site,” according to their status page.
The root cause of the site-wide outage was a restart of a “stale” (in other words, outdated) Terraform pipeline. “As part of a change request, an old pipeline was triggered. This applied an obsolete Terraform plan to the Production environment,” GitLab said in a post-incident report.
Terraform uses the concept of state to map real-world resources to the infrastructure-as-code-based configuration stored in the platform. When changes are contemplated (using what's known as a plan), the system checks that a snapshot of state in the plan matches the actual state of the infrastructure. Mismatches or variances cause the plan to become stale.
The post-incident report indicated that the outage scenario was an outlier, a reminder that it’s almost impossible to thoroughly plan for every possible situation that might materialize in a complex environment.
“The same action was performed multiple times without causing any issue,” GitLab noted. “The changing factor that caused this incident is the delay in rolling the change to production ([around] three weeks). The known-to-be-good pipeline to use for resource re-creation went stale and a configuration drift appeared due to more recent changes being made.”
This GitLab incident also underscores the importance of having a backup communication method in case your usual communication system is impacted by an outage. During the disruption, GitLab engineers initially coordinated incident response from a shared Google Doc, because regular mechanisms and internal tools were inaccessible. While this backup process didn’t work perfectly, the fact it existed is important.
When an outage event occurs, companies should have response processes ready, and this may include instructions to move to a completely different platform temporarily for business continuity purposes until the issue with the regular platform can be found and addressed. The process to shift to a backup or alternate system may be automated or manual: what’s important is it exists.
Microsoft Azure Disruption
In another recent outage caused by an unanticipated edge case, Microsoft Azure users in Western Europe experienced packet loss, timeouts, and/or elevated latency over an eight-and-a-half-hour period on July 5 from 07:22 UTC to 16:00 UTC. The cause was ostensibly a fiber cut caused by “severe weather conditions” in the Netherlands; although, in reality, it appeared to be a bit more complex than that.
Once again, configuration played a major role. As Microsoft explained, its West Europe region “has multiple data centers and is designed with four independent fiber paths for the traffic that flows between these data centers. In this incident, one of the four major paths was cut,” allegedly causing “25% of network links between two campuses of West Europe data centers [to become] unavailable.”
Ordinarily, it appears the load would have been redistributed over the remaining fiber. But, in the Netherlands that evening—and in outage-land more generally—“when it rains, it pours.”
In a bit of bad timing, it seems the four links were already running above their specified utilization due to ongoing recovery efforts from another incident that happened a few weeks prior. On June 16, the addition of a new network topology description was added into the network automation system, which included information on links that were about to be added to the network to increase the capacity in West Europe. However, the physical links had not yet been connected or turned on. Following this addition, the network automation system began issuing commands to prevent potential link imbalances, under the false assumption that all link descriptions in the system were connected and turned on. This false assumption resulted in several links being taken out of service, which in turn caused congestion and impacted customer traffic. Although regions are built with extensive redundancy, in this case, enough links were impacted to cause issues.

The reality of the July 5 outage is that it is difficult to test or plan for outlier scenarios such as these, whereby the impacts of a prior outage compound in an unexpected fashion.
The result was “intermittent packet drops” on intra-region paths, primarily impacting traffic between availability zones within the West Europe region.
ThousandEyes observed a substantial inter-AZ impact, with latency increasing from its usual average of less than 2ms per transaction to around 86ms. This might not seem like a lot, but for a customer shifting data between two AZs, with 90ms per transaction (or per server turn or application-level roundtrip), that can build up over time into errors, like timeouts.

This is a second outage that highlights the difficulty in planning for every contingency or edge case that might occur. When different circumstances combine to create an unexpected degradation or outage scenario, it’s imperative to quickly recognize that something is going awry, to pinpoint the root cause, and then to use that insight to quickly determine what to do next.
In Microsoft’s case, they were able to use “detailed before-and-after traffic simulation” to safely reduce traffic in the region and balance it across the remaining functional links, until the fiber could be re-spliced.
Meta Disruption: WhatsApp, Facebook, Threads, Instagram Issues
On July 10, some users reportedly lost access to all of Meta’s platforms, including Facebook, WhatsApp, Instagram, and Threads—its newest arrival.
From ThousandEyes’ observations, the impact of the July 10 degradation was localized to the northeast United States; although, there were reports of more widespread access issues. While Meta hasn’t released an official explanation, the incident appeared to coincide with severe weather in the region.
Weather often impacts data center sites, so it’s theoretically possible that, like Microsoft Azure, Meta also had a weather-related issue; although, this is purely speculative on our part.
Severe weather events represent another edge case scenario that are hard to predict. While some planning measures can certainly be taken in advance, it’s impossible to anticipate all weather events and when they’ll occur. Thoughtful backup plans and effective monitoring are important to help your company minimize the impact of unexpected weather events.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (July 3-16):
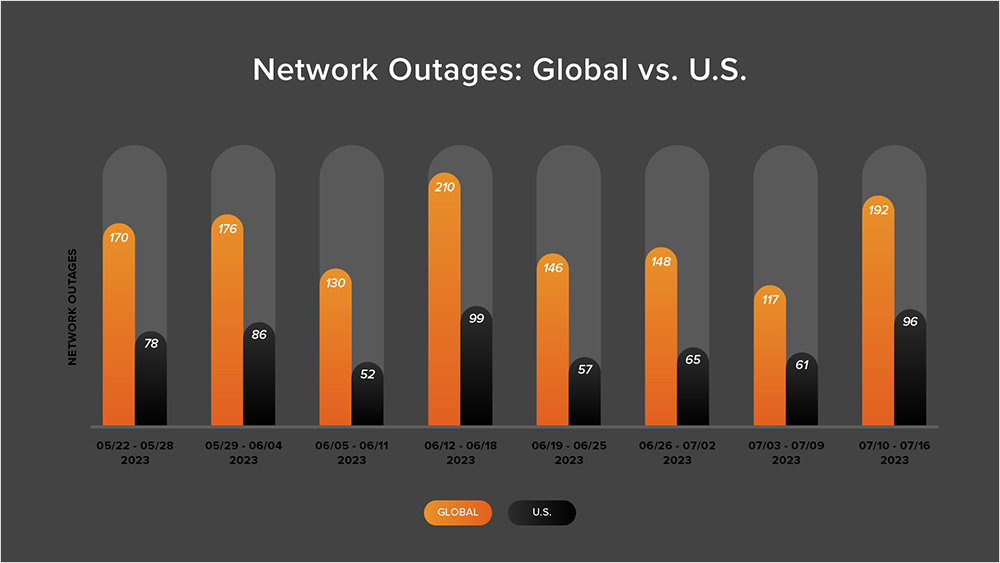
- Global outage numbers initially dropped, decreasing from 148 to 117—a 21% decrease when compared to June 26 - July 2. This was followed by global outages rising from 117 to 192, a 64% increase compared to the previous week (see the chart below).
- This pattern was reflected in the U.S. where outages initially dropped from 65 to 61, a 6% decrease when compared to June 26 - July 2. U.S. outage numbers then rose from 61 to 96 the next week, a 57% increase.
- U.S.-centric outages accounted for 51% of all observed outages from July 3-16, which is larger than the percentage observed between June 19 - July 2, where they accounted for 41% of observed outages. This continues the trend observed since April in which U.S.-centric outages have accounted for at least 40% of all observed outages; however, it’s only the second time this year when this percentage has exceeded 50%.