This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
If you want to know what load looks like in 2023, generative AI tools like ChatGPT have been under it, and occasionally overwhelmed by it.
Launched in late November 2022, ChatGPT has proved wildly popular, hitting over 1 million users in just five days after launch. Even semi-regular users of OpenAI’s ChatGPT will likely have been served the “at capacity right now” and “hang tight as we work on scaling our systems” status messages at least once while using ChatGPT.
And, in late March, ChatGPT was impacted by one of its first proper outages.
Read on to learn why the outage actually represented a pragmatic move on the part of OpenAI. We’ll also discuss global outage trends; explore other recent incidents at Dish Network, Microsoft, and Virgin Media UK; and look at why responses to performance problems vary, based on application characteristics and usage patterns.
OpenAI’s ChatGPT Outage
As previously noted, before the late March outage, some users did experience occasional difficulties accessing the service. Many of those users, especially those in the free tier, are likely pretty understanding of this occasional inaccessibility, knowing that ChatGPT is still an experimental offering.
But the space is moving fast, and as enterprises uncover more valuable use cases—such as developers using the tool to write Python scripts and SQL queries—ChatGPT will face higher performance and operational expectations.
Case-in-point, on March 20, ChatGPT experienced one of its first true outages. The outage itself was actually a pragmatic move on the part of operators to take the service offline when a vulnerability in the open-source software used on the backend was uncovered.
To maintain throughput and serve large volumes of users quickly, ChatGPT cycles users in and out of a shared pool of connections that are used to transmit requests and responses to and from the backend infrastructure.
The vulnerability meant that under certain conditions, data from a previous connection was shown to the next user allocated to that pooled connection. This meant that, according to OpenAI’s comprehensive writeup, “some” users saw “titles from another active user’s chat history. It’s also possible that the first message of a newly-created conversation was visible in someone else’s chat history if both users were active around the same time.”
It was then discovered the same bug had caused some users’ personal data to be viewable by others. At the point it became a security issue, OpenAI opted to take ChatGPT offline entirely to remediate the problem and limit the potential blast radius.
Being able to take an entire public-facing service offline is a luxury that many companies will never have. NetOps, DevOps, and engineering teams usually have to work on fixes in-flight, since the characteristics of their application or service—coupled with the usage profile—make taking it offline an impossibility in all but the most serious circumstances. And in highly regulated industries, there may even be penalties or other compensation required if a transactional system relied on by users needs to be pulled offline.
In ChatGPT’s case, however, the characteristics of the application—effectively an experimental platform in a high-growth market—allowed it to be taken down for a period. There was no brand damage; and OpenAI may actually emerge better off, partially due to the company’s transparency around the issue, which is not always the case in incident response scenarios.
Dish Network Outage
Dish Network also took major measures in response to a recent security-related concern, although under different circumstances. As we previously covered, Dish has been responding to a ransomware attack that also meant taking down its systems and, basically, its entire public-facing presence.
When we last left off, Dish was still recovering some systems and re-establishing functionality. That process was visibly continuing over a month later (at the time of this second post’s writing), based on our observations and tests.
Evidence suggests that while their network infrastructure is back online, they’re running it on a limited or controlled basis, and that’s resulting in some cascading impacts on customer services.
Customers have reported facing very long hold times for support. While it’s possible Dish hasn’t yet fully recovered its call center system, a similarly plausible explanation is that they might be limiting traffic ingress/egress to the system, which is causing a bottleneck.
It’s not unheard of for ransomware victims to be hit multiple times consecutively, or for cleanups to not go as planned—two scenarios that Dish is probably keen to guard against, which might have led them to control and limit traffic to the system in an effort to control the recovery as much as possible. Proper recovery is careful, methodical, and painstaking, and that’s likely the phase they’re in.
Microsoft 365 Outage
Microsoft 365 users ran into an unusual set of problems around March 21-23 when “a section of infrastructure responsible for regulating user geolocation” malfunctioned, according to the advisory posted in the Microsoft 365 admin portal.
Geolocation is one of many checks that Microsoft 365 makes when determining authorization permission and access. Environments that had implemented “specific conditional access policies” based on user location suddenly found that users were locked out of the service because Microsoft 365 recognized them as logging in from a different geography than the one they actually were in.
Users in multiple regions, including North America and Japan, were impacted, according to the advisory.
For some, this would have manifested as an outright refusal to connect, as their conditional access policies were denying access requests due to users’ geolocations being inaccurate. Others might have experienced slow performance, even if their policy didn’t specifically block access based on geolocation details because Microsoft may have mistakenly routed traffic over circuitous data transit paths since the users appeared to be in a different country than they truly were. This odd traffic routing may also have caused issues for customers with internal restrictions on which international routes they favor for their traffic.
The problems impacted some big organizations, including the UK’s National Health Service (NHS). Microsoft ultimately initiated a rollback and implemented some traffic redirections to return Microsoft 365 to normal operations.
Virgin Media UK Outage
Another company to face outages in recent weeks was Virgin Media UK. On April 4, Virgin Media UK (AS 5089) experienced two outages that impacted the reachability of its network and services to the global Internet. The two outages shared similar characteristics, including the withdrawal of routes to its network, traffic loss, and intermittent periods of service recovery.
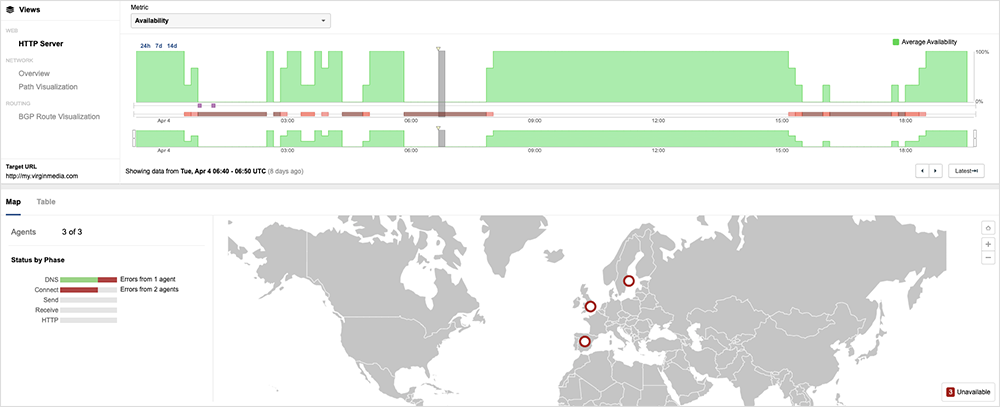
The recurrence of a nearly identical incident later in the day might indicate that the triggering mechanism for the first incident was either not fully understood or was not completely resolved. For a deeper discussion of these outages, see this April 4 blog and also this podcast.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (March 27 - April 9):
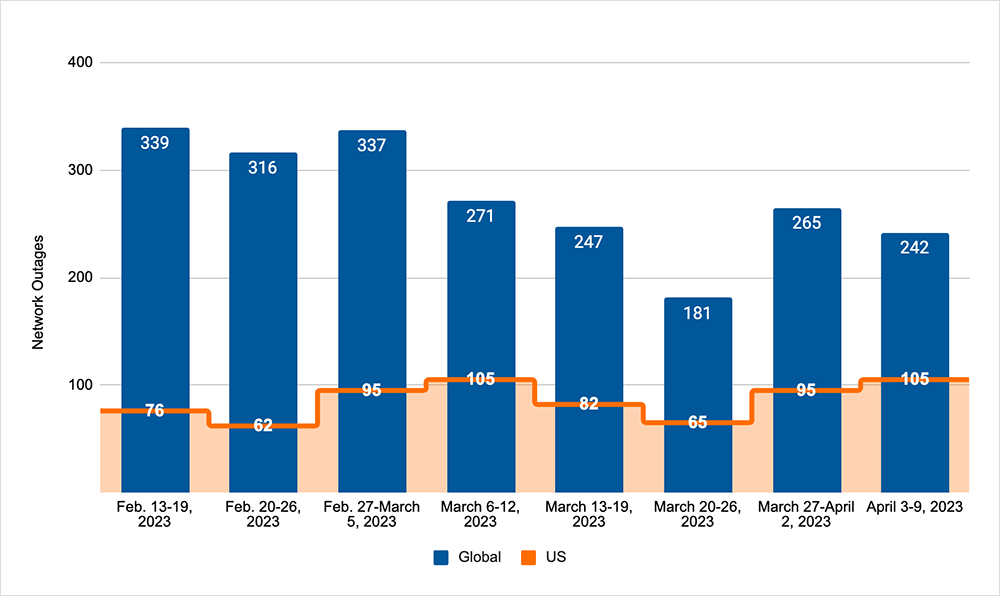
- The downward trend that had been observed in the preceding period was initially reversed, as global outages rose from 181 to 265, a 46% increase when compared to March 20-26. However, the downward trend returned the next week with global outages dropping from 265 to 242, a 9% decrease compared to the previous week (see the chart below).
- This pattern was not reflected in the U.S., as outages rose across the two-week period. In the first week, outages rose from 65 to 95, a 46% increase when compared to March 20-26. This was followed by another rise from 95 to 105 the next week, an 11% increase.
- U.S.-centric outages accounted for 39% of all observed outages, which is larger than the percentage observed between March 13 and March 26, where they accounted for 34% of observed outages.
- Since this two-week period (March 27 - April 9) includes the end of March, it’s also worth taking a look at total March outage numbers, compared to February’s outage numbers. In March, total global outages dropped from 1305 to 1077, a 17% decrease when compared to February. However, U.S.-centric outages rose from 312 to 369, an 18% increase.