This is the Internet Report: Pulse Update, where we review and provide an analysis of outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read our full analysis below or tune in to our podcast for first-hand commentary.
Internet Outages & Trends
It was an eventful fortnight on the Internet as Twitter, Dish Network, Akamai, and Ticketek Australia all experienced outages.
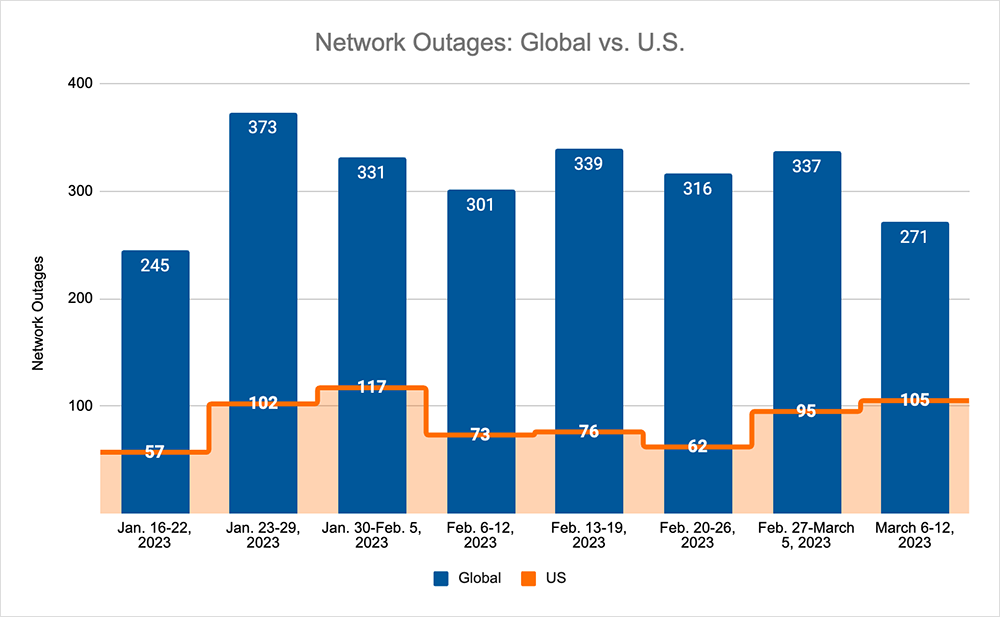
Looking at global outage trends, we also saw total outage numbers rise briefly, before resuming their downward trend, while U.S. outages increased consistently, accounting for 33% of all outages. See the By the Numbers section below to learn more.
Read on for our analysis of these incidents and global outage trends, or use the links below to jump to the sections that most interest you.
Twitter Performance in the Elon Era
On March 6, around 3:45 PM UTC, Twitter users globally began receiving HTTP 403 forbidden errors, preventing some from being able to access the service or click on links. The fact that 403 forbidden errors were seen in response to user requests is indicative of a backend application issue. Around 4:19 PM UTC, Twitter announced that the disruption had been caused by an internal system change that had some unintentional consequences, and they were working to resolve it. The disruption lasted 60 minutes, with service access restored to users around 4:50 PM UTC.
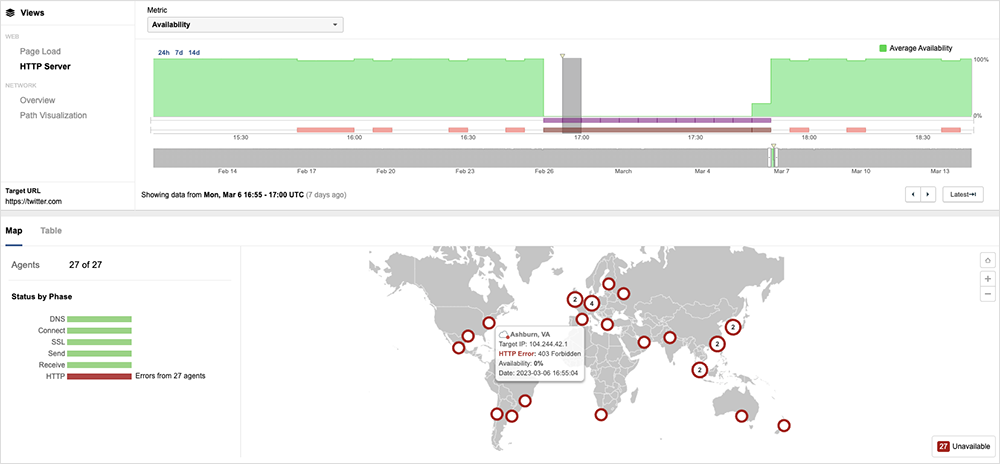
Looking at Twitter performance over time, the March 6 outage event is the only service-wide disruption seen over the past six months. However, over that same period of time, other instances of service degradation have increased. While these degradation issues wouldn’t render the app completely unavailable, some content may not load correctly or some functions may appear to lag for some users. In the last three months, for example, the number of incidents that impacted Twitter performance or app availability more than doubled, increasing from 100 to 208, compared to the same period last year (December 2021 - February 28, 2022). Most of these incidents were brief or impacted a limited aspect of the service, meaning only some aspects of the application were unavailable or seeing issues.
One example of such a degradation occurred on the morning of March 1, when Twitter users were greeted with an empty timeline and a “Welcome to Twitter” message—as if they’d just set up an account and logged in for the first time. The site itself appeared to be functional; it could still be reached, trending topics worked, and users could still tweet. But the timeline, which normally displays recent tweets from accounts users are following, did not render properly and was blank.
This incident lasted several hours and occurred in the morning for those in the U.S. It technically broke with the pattern of outages we’ve observed (and previously discussed) for Twitter, which are largely backend-related, or comprised of timeouts and/or unresponsive services. It's not totally clear what caused this issue, but five days later an internal system change caused widespread disruption.
Dish Network Outage
Dish Network was forced to pare back to only the most essential online presence when it became a ransomware victim. After detection, isolation and containment are critical parts of security incident response, and these steps were clearly followed as Dish’s issues unfolded.
Dish more or less fell off the Internet, as traffic dropped to zero and page loads timed out, which is consistent with a network becoming completely isolated. This “lights out” response was clearly visible externally, as was the tentative recovery when business continuity processes kicked in and engineers worked out what they could and couldn’t recover and/or restore of their IT systems and web presence.
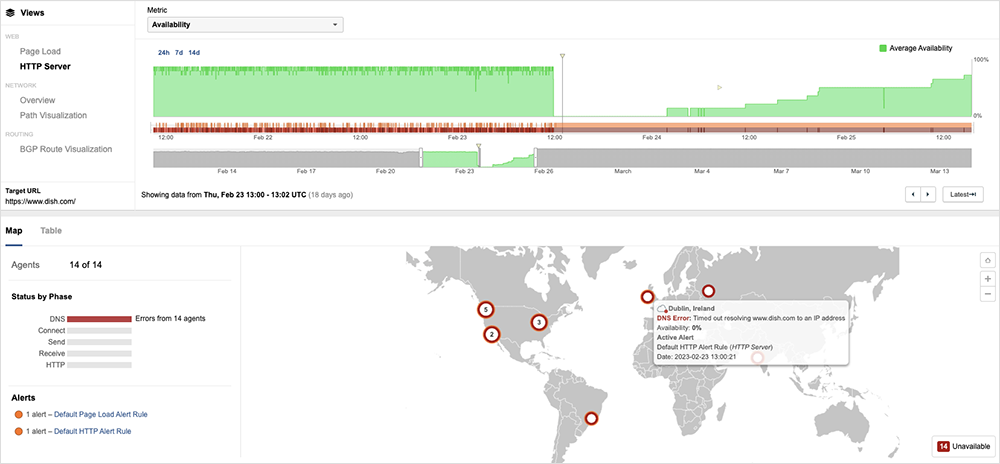
The initial online presence that signaled recovery was minimal: a simple website with just the Dish Network logo, with no navigation paths or access to any backend services beyond that.
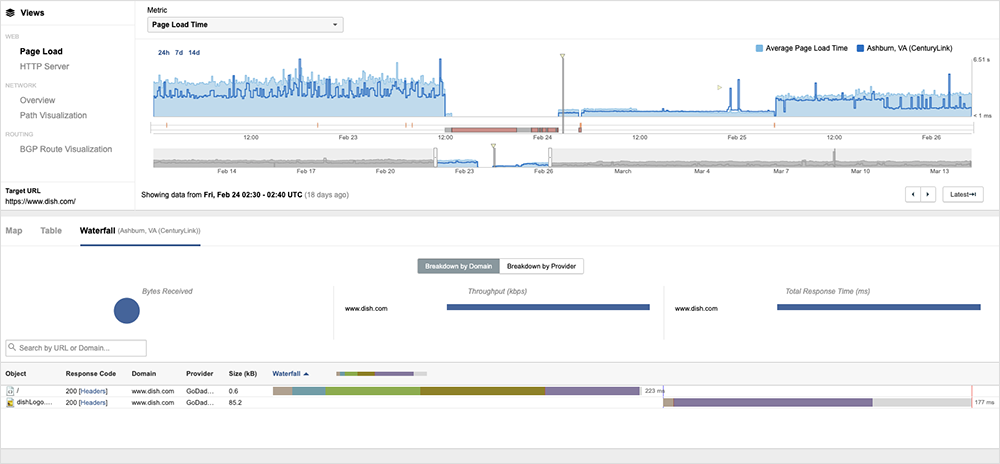
An interesting aspect observed by ThousandEyes was the use of a different host and different traffic pathways in the initial stages of recovery. Dish appears to have reverted to its usual primary providers once recovery progressed and (most likely) when it was determined that the attackers’ access paths had been blocked.
This kind of minimalism is understandable, even logical. Dish’s engineers needed time to test their connectivity and routing to understand the extent of the infection, to clean any hardware, and to recover their systems. The easiest way to do that was to temporarily become an island and then slowly reconnect to the internet when appropriate. Full recovery after a ransomware attack is a lengthy process, typically measured in weeks. According to a company statement, Dish was still re-establishing some functionality, such as online payments, at the time this blog was written.
Akamai Edge Delivery DNS Resolution Failures
Akamai reported “Edge Delivery DNS resolution errors” on February 27, starting at 19:00 UTC, with a total duration of approximately 20 minutes. The official explanation will be familiar to regular readers of this blog, as a typical root cause identified by many a software engineering or deployment team: “A recent software release [that] was identified by our monitoring and alerting systems, at which point the software release was rolled back.”
ThousandEyes observed intermittent packet loss and timeout conditions that may have prevented some users from accessing or interacting with applications leveraging Akamai’s CDN service. Applications impacted include Salesforce, Azure console, SAP Concur, LastPass, and others. The incident appeared to have mostly recovered by around 21:55 UTC, but intermittent issues continued for some applications and users.
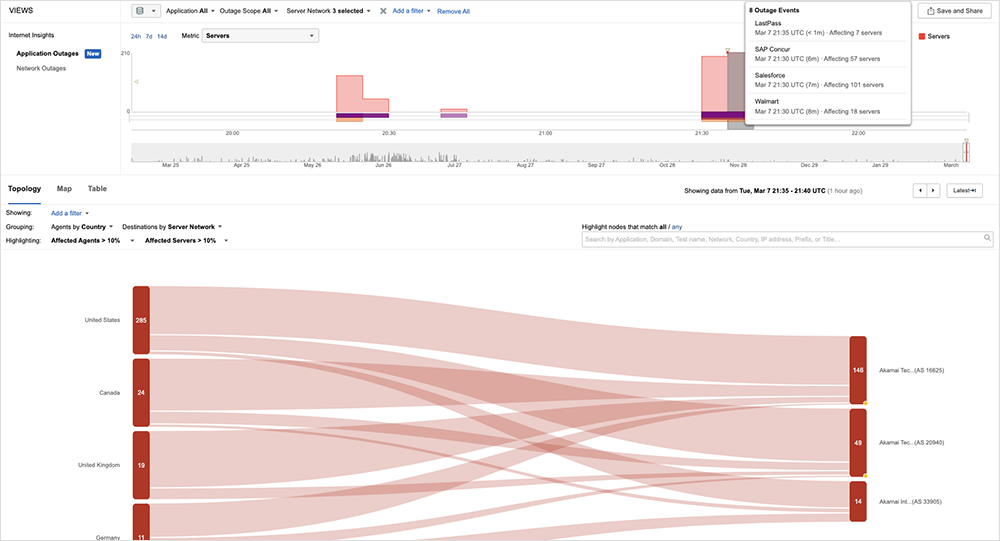
Akamai has had DNS problems before, and I’ve previously outlined the case for and against having CDN redundancy to guard against potential DNS issues. Without re-prosecuting that case, this level of redundancy would not be practical for everyone, particularly because of the expense of having an alternative CDN handy just in case it’s ever needed.
A more practical alternative could be having the ability to re-advertise your online services through a different network, allowing valid traffic paths to your services to be established. This would require having a good understanding of how all your systems, subpages, services, and sites are served.
Ticketek Outage
Ticketek in Australia, an event ticket retailer, also experienced an outage in March. Here, the company’s app reportedly failed to display the necessary ticket barcode to scan for entry into an entertainment venue, so tickets could not be validated. The nature of the issues suggested a backend problem, potentially connectivity-related, as even e-tickets that had been previously downloaded displayed on users’ devices as void or as being for an expired event.
In this circumstance, it was Ticketek that quickly went into impact mitigation mode, enacting a contingency plan to get tickets manually printed at the venue and into the hands of concert-goers. The incident highlights the challenge of uptime and maintaining access to digital credentials and other goods stored in digital wallets as their use is already ubiquitous and will likely only become more prevalent.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (February 27– March 12):
- Global outages initially reversed the downward trend seen over the previous two weeks, rising initially from 316 to 337, a 7% increase when compared to February 20–26. However, the downward trend returned the next week with global outages dropping from 337 to 271, a 20% decrease compared to the previous week (see the graph below).
- This pattern was not reflected domestically, with an upward trend observed over the two-week period. Initially, outages increased from 62 to 95, a 53% increase when compared to February 20–26. This was followed by another rise from 95 to 105, an 11% increase compared to the previous week.
- U.S.-centric outages accounted for 33% of all observed outages, which is larger than the percentage observed on February 13-19 and February 20–26, where they accounted for 21% of observed outages.