This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
There’s never a good time to experience a degradation or outage, but there’s some relief when an outage's impact is either isolated to or occurring in a different region or outside of your business hours. However, even a regional outage can have a refractive effect on other geographies, an experience that may be heightened by the ‘follow the sun’ model. Common in software development today, the follow-the-sun model refers to a practice where teams in certain time zones complete work while their colleagues in other geographies are offline for the night, enabling greater efficiency.
For example, many large U.S. companies—and indeed large companies throughout the world—have application development teams in India. If an outage impacts the team in India during their business hours, it could stall projects their U.S. colleagues were counting on, impacting the company’s U.S. operations as a result.
The refractive impacts of regional outages are supported by our own data. Year-over-year, we’ve consistently observed that between 70% and 80% of outages occur outside of U.S. Eastern Time business hours. As a result, one might think that these outages would have limited impact on U.S. businesses and their customers. However, the blast radius of these outages often impacts other geographies during what would then be their own business hours. The issues experienced by these regions then have ripple effects on other areas, including the U.S.
In recent weeks, GitHub experienced a service degradation that had some interesting regional aspects. While the root cause of the incident hasn’t been officially announced, it serves as a jumping-off point to discuss the potential impacts of a follow-the-sun approach and the importance of proper visibility to guard against possible ripple effects.
Read on to learn more about this event and other recent outage news. (Or use the links below to jump to the sections that most interest you.)
GitHub Service Degradation
On May 9, at 11:32 AM UTC (4:32 AM PT), GitHub said it was investigating reports of “degraded performance for Git operations.” The performance degradations cascaded to impact more GitHub services over the next 25 minutes. The problems then escalated to “degraded availability,” again impacting more services progressively.
Recovery began at 12:38 PM UTC; “the majority” of services were deemed to have recovered by 1:14 PM UTC, except for three services that took until 3:07 PM UTC to fully recover. GitHub then had to process the backlog of delayed pull request updates, which may have had the effect of extending the disruption period.
ThousandEyes’ tests showed the issues manifested mostly as 5xx errors, ranging from 500 - internal server errors and 502 bad gateway errors to 503 - service unavailable errors, with server requests timing out and servers being unreachable and/or unresponsive.
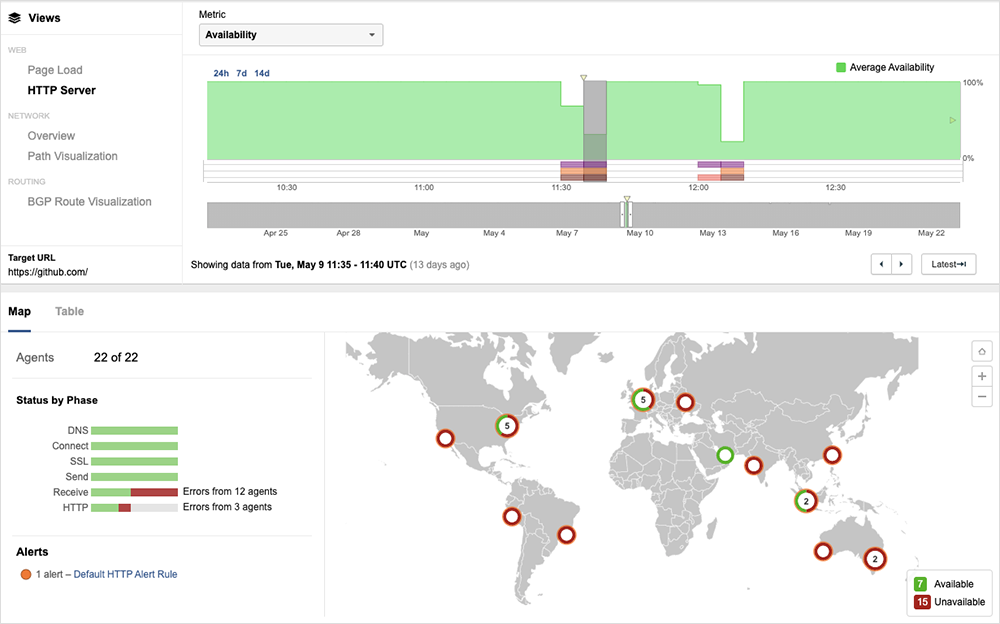
Interestingly, we also observed impacts on both GitHub and Microsoft infrastructure (Microsoft acquired GitHub in 2018). Those impacts appeared to be regionally based: Most North American impact was through GitHub infrastructure, while APAC and EMEA were being routed through Microsoft infrastructure, but ultimately hit the same bottleneck. That may point to workloads being shifted around internally between GitHub and its parent, Microsoft.
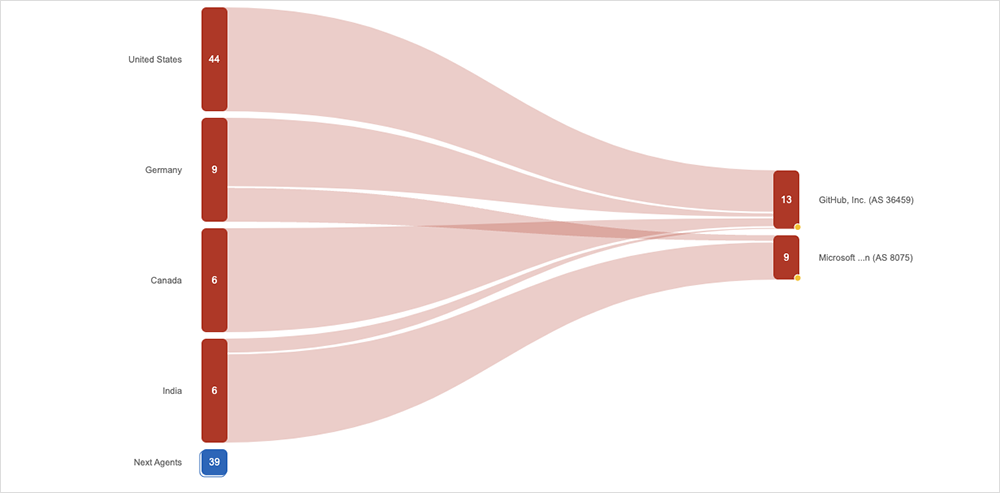
While the root cause of the GitHub incident has not been made official, we can observe some of the unique characteristics of this service degradation in order to surmise that the root cause was likely in the traffic distribution layer at a point of aggregation—a global load balancing or distribution service, for example.
Though there appeared to be an overall global impact, there are some interesting regional aspects to explore. First, while the incident occurred in the early hours of the morning, before North American business hours, the U.S. region was still heavily impacted. This is likely an artifact of current software development and deployment practices: Increased automation means code is often scheduled to be deployed to production out-of-hours. This may be what we’re seeing here, the breakage of this deployment model. One of the impacted services was GitHub Actions, a CI/CD workflow tool. Its unavailability may have caused a number of automated deployments not to complete.
India was another geography that appeared particularly hard-hit, with the problems starting around 5 PM IST. Software development practices may explain this as well. As discussed above, many large organizations in the U.S. and elsewhere have application development teams in India as part of a follow-the-sun model, an approach designed to optimize efficiencies within the organization and well suited to today's non-monolithic application architecture as different people and locations can simultaneously work on different parts of the code independently. The move to hybrid work practices globally was, in some ways, pioneered by application developers. Their work has long been distributed across multiple geographies.
Given the timing of GitHub’s problems, the impact on India may not have been domestic as much as international, stalling software deployments being made on behalf of companies in the U.S. and other regions by teams in India under this follow-the-sun model. As a result, the GitHub degradation may have had a larger effect on North America than it appeared.
We’ve previously discussed how follow-the-sun strategies influence outage scenarios. For example, when recovering from a global outage earlier this year, Microsoft appeared to take follow-the-sun operations into account, prioritizing recovery in geographies where it appeared to be impacting regional working day, and progressing from there. However, an outage can still significantly impact a region even if it occurs outside their typical business hours because the outage may impact users in other timezones and the resulting ripple effects may then impact users in the original region.
For organizations that utilize a follow-the-sun model, it’s important to have holistic visibility of the service delivery so that they can thoroughly understand and quickly ascertain the impact disruptions may have on other areas. These impacts may not be visible when viewed in isolation and only become apparent when considering the complete chain, including associated dependencies. In turn, this deeper understanding can be central in architecting around any single points of failure, and/or addressing them in disaster recovery and business continuity plans.
Aside from this GitHub incident, in recent weeks, two other major tech companies experienced disruptions that are worth exploring as well.
Update: Google Cloud Outage
In our last blog, we discussed the “water intrusion” incident at a Paris data center that caused problems for Google Cloud’s europe-west9 region, which is home to three AZs: a, b, and c.
Google published a preliminary incident report, explaining the sequence of events. In short, a water leak led to a battery room fire. The leak initially was confined to europe-west9-a, but “the subsequent fire required all of europe-west9-a and a portion of europe-west9-c to be temporarily powered down.” While europe-west9-c was partially unavailable, “many” regional services were affected, but “were restored once europe-west9-c and part of europe-west9-a returned to service,” Google said. Existing instances in the europe-west9-a zone remain impacted at the time of this blog’s writing, with Google suggesting failover to other AZs or regions, if possible.
A few days before the report was released, customers in zone c also experienced a near five-hour outage of “multiple cloud products”. It’s unclear if this was related to the ongoing recovery options from the earlier incident.
Apple Authentication Issues
On May 11, Apple experienced a 43-minute outage that impacted iCloud account access and sign-in. The company briefly acknowledged the issues in a status advisory, saying that for “some users … this service may have been slow or unavailable.” Users in the UK were among those that reported being impacted.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (May 8 - 21):
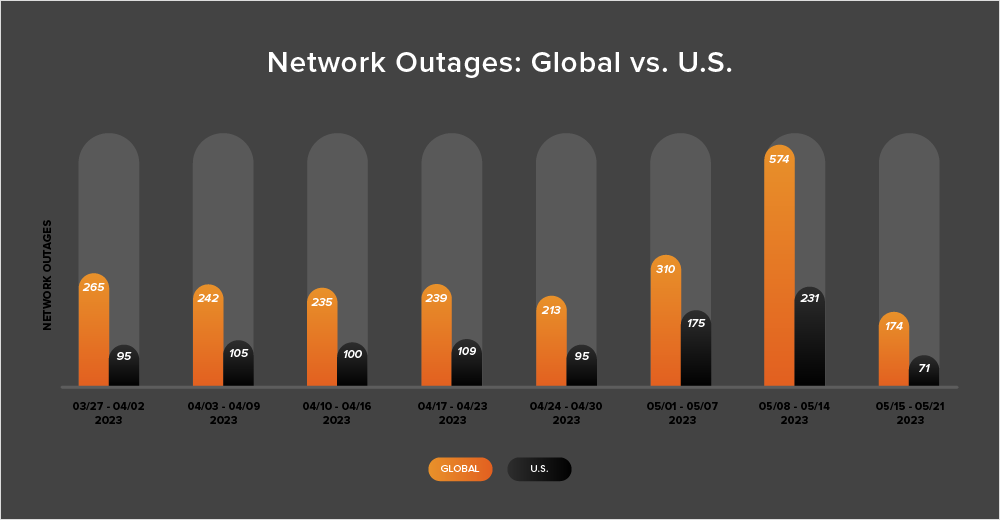
- Global outage numbers initially rose, increasing from 310 to 574—a significant 85% increase when compared to May 1-7. This was followed by an equally significant drop, with global outages dropping from 574 to 174, a 70% decrease compared to the previous week (see the chart below).
- This pattern was reflected in the U.S. as outages initially rose from 175 to 231, a 32% increase when compared to May 1-7. U.S. outage numbers then dropped significantly from 231 to 71 the next week, a 70% decrease.
- That sharp 85% increase in global outages during the week of May 8-14 is worth examining further as it represented the highest number of global outages observed in a single week this year. However, while the increase observed from the week prior was significant, an investigation into the source, distribution, and impact of the outages revealed that they appeared very localized in terms of reach, and seemed to have a low to negligible impact on the majority of the global community.
- U.S.-centric outages accounted for 40% of all observed outages from May 8 - 21, which is smaller than the percentage observed between April 24 and May 7, where they accounted for 52% of observed outages. This continues the recent trend in which U.S.-centric outages have accounted for at least 40% of all observed outages.