This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
Best-practice technology strategy is built on the idea of having more than one way to access a resource. As IT environments have changed, so has the thinking around the right approaches to achieve this desired redundancy.
In the on-premises world, redundancy means having primary and secondary data center sites, each with its own backup power supply. That way, if one site is lost, an organization can still run its core systems in some capacity while the primary site is restored. In the cloud world, it may mean architecting applications or workloads to run across multiple availability zones or multiple regions for redundancy purposes. As the cloud continues to become increasingly central for so many businesses, questions have come up about redundancy best practices in this cloud-based environment.
During the past fortnight, we’ve seen two types of incidents that reinforce the need for a backup of some sort—and the importance of evolving approaches to redundancy.
Read on for our analysis of these events and other recent global outage trends, or use the links below to jump to the sections that most interest you.
Why Redundancy Matters (and What Makes Sense?)
Before diving into the outages, it’s worth dwelling a bit more on why redundancy matters. Redundancy is a big part of what keeps the world connected. While the number of cross-connects, interconnects, and transit routes mean there are many things that can go wrong, the flip side is that network operators have so many choices, and so many diverse paths, that problems with one can be intelligently routed around, and the performance impact may be imperceptible.
These kinds of redundancies are considered economically plausible. However, it must be acknowledged that some types of redundancy can prove impractical in certain cases. Take CDNs, for example. While CDN redundancy can be wise, it can also strain a company’s budget. Even though having a CDN on standby might be beneficial for large organizations that experience sudden issues when trying to serve content to their users, an organization’s primary CDN may not fail often enough to justify this level of backup (and if it did, it may warrant reconsideration of their choice of primary provider).
While there are always going to be exceptions to any rule, it is mostly still best practice to have backup methods and diverse paths to access resources, in case the usual mode of access fails.
Google Cloud Outage
One of the recent outages that drove home the importance of redundancy was a “water intrusion” incident at a Paris data center that caused “a shutdown of multiple zones” of Google Cloud’s europe-west9 region on April 25. The region is home to three availability zones (AZs), according to Google Cloud. The provider was able to recover services in two of the three regions after about 24 hours, but it was still having issues with services hosted out of one zone.
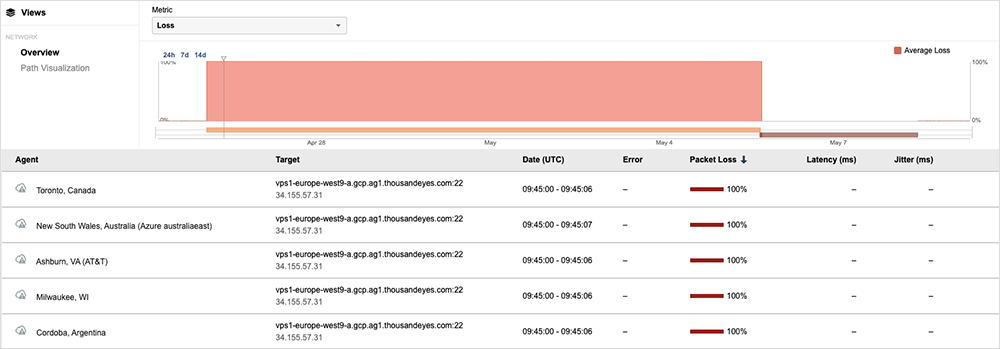
In this situation, customers with a multi-AZ setup would have needed the AZs to be in more than one country to completely avoid problems.
That seemed to catch the attention of some commentators as being somewhat odd: Certainly, in the on-prem world of the past, geographic separation or geo-redundancy was a common consideration for data center site selection. It would have once been highly unusual to have primary and secondary facilities in the same campus or site. Yet this is often the case for cloud providers today: Where more than one AZ exists for a city, chances are they’re in close proximity, either in the same building or in adjacent buildings on a large data center campus.
This practice needs to be taken into consideration when architecting applications or workloads to run in the cloud. Visibility and transparency into cloud providers’ architectures is critical in identifying where cloud services are hosted and the dependency risks of certain architectural setups. Organizations can use this insight to run their own ‘what-if’ scenario-based testing and planning to understand the risks of one architectural setup over another.
As a side note, we’ve recently observed a shift in the backup strategies of organizations operating in the cloud. Rather than spreading their risk across multiple AZs with one provider, they’re applying a primary-secondary operational model. In this approach, a secondary, smaller cloud environment is kept at-the-ready to be substituted in should their primary cloud provider encounter catastrophic issues. The switchover is not going to be as instantaneous, or potentially seamless, as it would be with a redundant configuration with a single cloud service provider, but this alternate model may be attractive due to its cost-effectiveness. We’ll continue observing this space to see how much of a viable Disaster Recovery Plan (DRP) model it becomes.
Microsoft 365 Outage
The second incident occurred on April 20 as some users of Microsoft 365 apps were unable to access certain apps from their central Microsoft 365 login page. Some users were locked out of this main login page completely, while others could reach the applications but experienced various functional issues with the apps once there. For users who could reach the login page, the problems were intermittent and impacted customers unevenly. Parts of the apps, such as the search bar, failed to render properly.
For users locked out altogether, it quickly became apparent from forum posts that a workaround existed: The apps could be accessed directly from URLs such as outlook.office.com for Outlook and microsoft365.com/word/launch for Word, and so on. So, there was a backup of sorts, but it required users to know about this alternate way of accessing the applications, separate from the usual access method of a single sign-on through which all Microsoft 365 services could normally be accessed.
The incident has some similarities with one in March involving Okta, a single sign-on portal through which many users now access their enterprise application suites. Okta acts as a central ‘front door’ to applications. While users couldn’t authenticate to enter through that ‘front door’ during the disruption, they could still reach applications individually and log into them—if their organization’s policies allowed it. Both the Microsoft 365 and Okta incidents illustrate that while landing pages can simplify access to large numbers of apps, backup options might be needed in the event the landing pages themselves become inaccessible.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (April 24 - May 7):
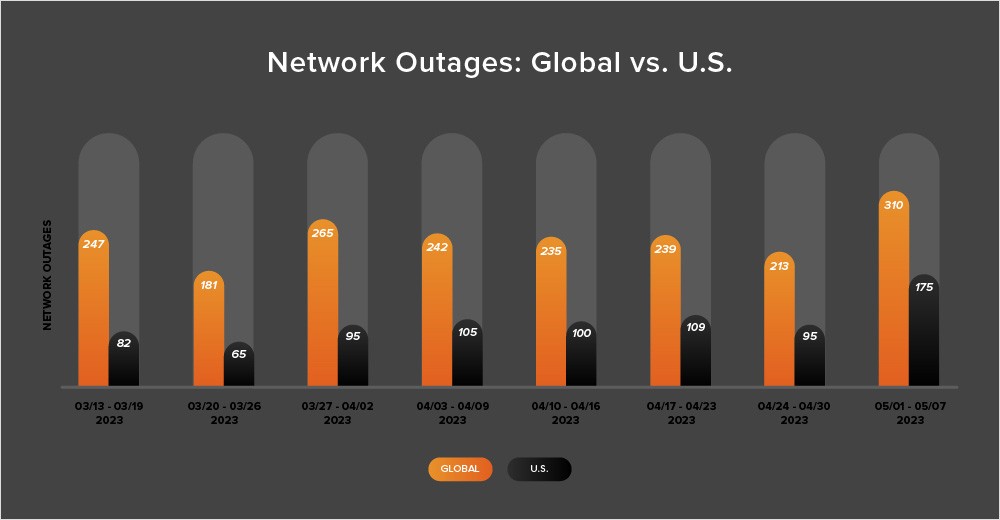
- Global outage numbers initially dipped, dropping from 239 to 213—an 11% decrease when compared to April 17-23. This was followed by a significant rise, with global outages jumping up from 213 to 310, a 46% increase compared to the previous week (see the chart below).
- This pattern was reflected in the U.S. as outages initially dropped from 109 to 95, a 13% decrease when compared to April 17-23. U.S. outage numbers then rose significantly from 95 to 109 the next week, an 84% increase.
- U.S.-centric outages accounted for 52% of all observed outages, which is larger than the percentage observed between April 10 and 23, where they accounted for 44% of observed outages. This is the second consecutive fortnight in which U.S.-centric outages have accounted for more than 40% of all observed outages—breaking the trend seen in the rest of 2023 where U.S. outages remained under 40%.
- Since this two-week period (April 24 - May 7) includes the end of April, it’s also worth taking a look at total April outage numbers, compared to March’s outage numbers. In April, total global outages dropped from 1077 to 1026, a 5% decrease when compared to March. However, U.S.-centric outages rose from 369 to 451, a 22% increase. This continues the trend observed in March, where global outages also decreased from their February levels and U.S.-centric outages increased.