This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
We often talk about the need to recognize issues and act to resolve them in real time. Doing so requires instrumentation and visibility into environments in order to detect and correlate the source of issues as they occur.
Underpinning all of that is data. In any real-time operation, the fresher the data, the quicker the organization is able to act.
But data is not always as fresh as one would like. In recent weeks, stale data appeared to lead to incidents at both Slack and Cloudflare: Slack began experiencing issues when, by our best guess, its app stopped trusting the freshness of the data in the cache; and separately, Cloudflare’s 1.1.1.1 DNS resolver ran into some issues related to stale root zone data.
Read on to learn more about these disruptions and other recent incidents, or use the links below to jump to the sections that most interest you.
Slack Outage: Cached Data Freshness Issues
Slack, a cloud-based messaging app for businesses, stopped loading for some users for 20 minutes in the early hours of Friday, October 6. The incident’s official cause was explained on Slack’s status page and was related to “an issue where certain backend Slack processes were pulling data from [Slack’s] database rather than their cache, which caused strain on [Slack’s] servers.”
During the incident, pages appeared to be loading; however, ThousandEyes observed the service itself to be unavailable. Upon further inspection by ThousandEyes, the pages appeared to be only partially loading. Just essential page elements—such as images and style sheets—were loading, but the rest of the page was not. Additionally, ThousandEyes observed a reduction in page size—further evidence that the pages weren’t fully loading. These conditions appear to indicate that the issue was a result of some sort of backend application service.
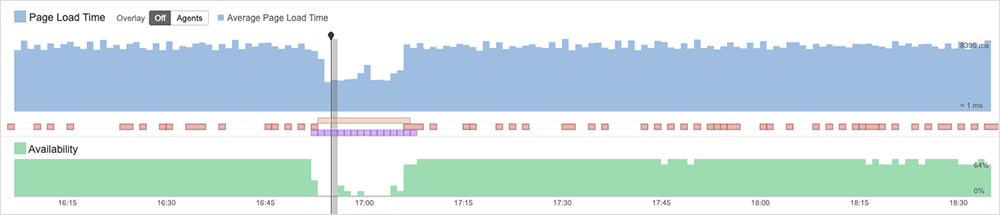
While we don’t have official details explaining why the application switched to pulling data from the database in the first place, our best guess is that (for whatever reason) the application stopped trusting the freshness of the data in the cache, and so it began passing the queries directly to the source: Slack’s backend database infrastructure. While this may have worked as designed, the cadence and volume of “freshness” checks with the data source would have been unexpected, quickly leading to capacity issues. Unable to process all the requests, the database returned 500 errors, indicating that the server encountered an unexpected condition that prevented it from fulfilling the request. This would have manifested as connection issues and incomplete page loads for users on the frontend.
Slack said it restored services by rolling out “a change to how these processes load data.” This may have taken the form of a temporary workflow that established the cached data as authoritative, bypassing the need for freshness checks. This would have allowed Slack’s engineers to resolve the root cause that made the cached data appear to be not fresh.
Cloudflare Outage: Resolvers Use Stale Root Zone
In another example of “stale” data causing disruptions, Cloudflare experienced DNS resolution issues for four hours on October 4 due to an issue with refreshing a root zone file.
The company provided a detailed explanation of the issue, which began when a new resource record (ZONEMD) was incorporated into the highest level of the DNS structure, the root zone, under a planned change.
For context, Cloudflare, like most DNS operators, retains its own copy of the root zone to ensure continuity in case the root servers can’t be reached. According to a statement from Cloudflare, “[t]he root zone is retrieved by software running in Cloudflare’s core network [and] is subsequently redistributed to Cloudflare’s data centres around the world.”
While the root zone was retrieved as normal, Cloudflare’s 1.1.1.1 DNS resolver appears to have had problems parsing the new record, and so it kept relying on a known working version that did not contain the new resource record. The outage occurred weeks later when, as Cloudflare states, “the DNSSEC signatures in the version of the root zone [that were] successfully pulled on 21 September expired … [and subsequently] there was no newer version that the Cloudflare resolver systems were able to use.”
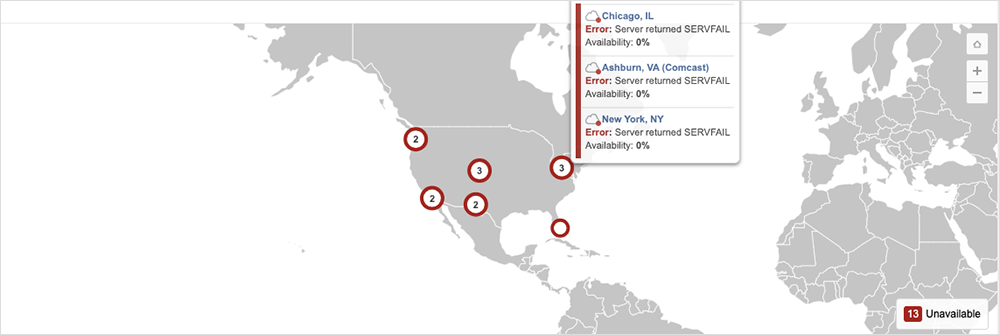
The company is set to make changes following the incident, including adding monitoring and visibility.
“It should not have been the case that serving a stale root zone file went unnoticed for as long as it did. If we had been monitoring this better, with the caching that exists, there would have been no impact. It is our goal to protect our customers and their users from upstream changes,” the company wrote.
Google Search Indexing Delays
In other outage news, on October 5, Google experienced a Search indexing issue that affected the indexing of “newly published content” during a nearly six-hour period. As of the publication of this post, Google hasn’t released an official explanation for the incident.
Google Calendar Inaccessible
Google also experienced another disruption about two week’s prior, this time impacting Google Calendar. On September 21, some Google Calendar web and mobile users experienced “500 Internal” errors “when trying to access Calendar on the web main page and while interacting with events.”
According to a company statement, the root cause was a software update that “triggered an unintended bug,” which was then “compounded by an increase in invalid internet Calendar Scheduling (ICS) from Gmail to Calendar.” The issues were subsequently mitigated by scaling up Calendar resources, filtering traffic to Calendar backends, and rolling back the ICS file processing change. The incident occurred over a three hour and 15 minute period, according to Google.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (September 25 - October 8):
-
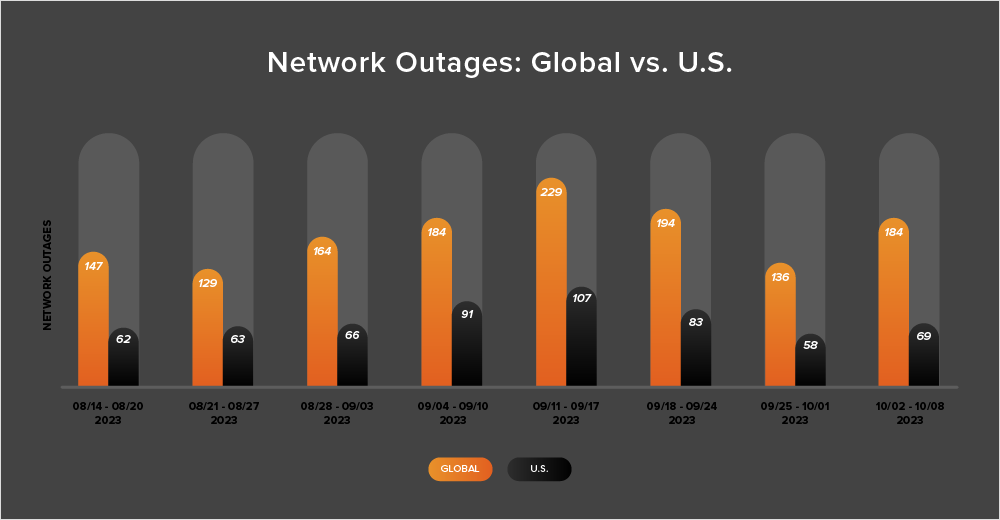
During the two-week period from September 25 to October 8, global outages decreased from 194 to 136, which is a 30% decrease compared to the previous week (September 18-24). However, the following week, observed outages increased 35%, rising from 136 to 184, as shown in the chart below.
-
U.S.-centric outages reflected the same pattern, initially dropping from 83 to 58—a 30% decrease when compared to September 18-24. Outages then rose from 58 to 69 the next week, a 19% increase.
-
U.S.-centric outages accounted for 38% of all observed outages from September 25 to October 8. This marks only the second time since April that U.S.-centric outages did not account for at least 40% of all observed outages in a given two-week period.
-
Looking at the month-over-month trends, in September, the total number of global outages observed increased from 727 to 770, which is a 6% rise when compared to August. Outages also rose in the U.S. but at a much steeper rate, increasing from 288 to 352, a 22% surge. This increase reflects similar patterns observed previously for this time of the year, as the fall season begins in the Northern Hemisphere.