This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
In modern distributed web-based applications or services, everything is linked and dependent on each part functioning correctly. Within an organization, it’s also crucial for all teams to be aware of what the others are doing so they don’t accidentally break something. A single lapse or break in one place can have a flow-on impact elsewhere.
While it’s difficult to eliminate siloed operations or decision-making completely, the negative effects of silos can be reduced if each team has a view of the end-to-end service that is tailored to their specific area or domain—that is, presented to them in a context that they understand.
A recent incident at Slack illustrates how important this visibility is and how the combined impact of two separate actions can have unintended consequences.
Read on to learn more about the incident at Slack and other recent outages, or use the links below to jump to the sections that most interest you.
Slack Disruption
On August 2, from 4:01 PM UTC to 6 PM UTC, Slack experienced an issue that initially prevented users from uploading files or sharing screenshots, with images appearing blurred or greyed out. For a subset of users, this then progressed into errors or slowness with other functions of the service. Some users encountered slow page load times and general instability, with some appearing to be unable to log in.
The incident highlighted the extent to which functionality equals usability. During the outage, some users we spoke with could send text-only messages, but when they tried to send screenshots, that appeared to fail to send. The usability was degraded significantly enough for them to switch to an alternative collaboration service temporarily.
So what caused Slack’s issues?
Initial observations found an increase in HTTP 500 server unavailable errors and higher-than-normal page load times for global users trying to reach Slack.
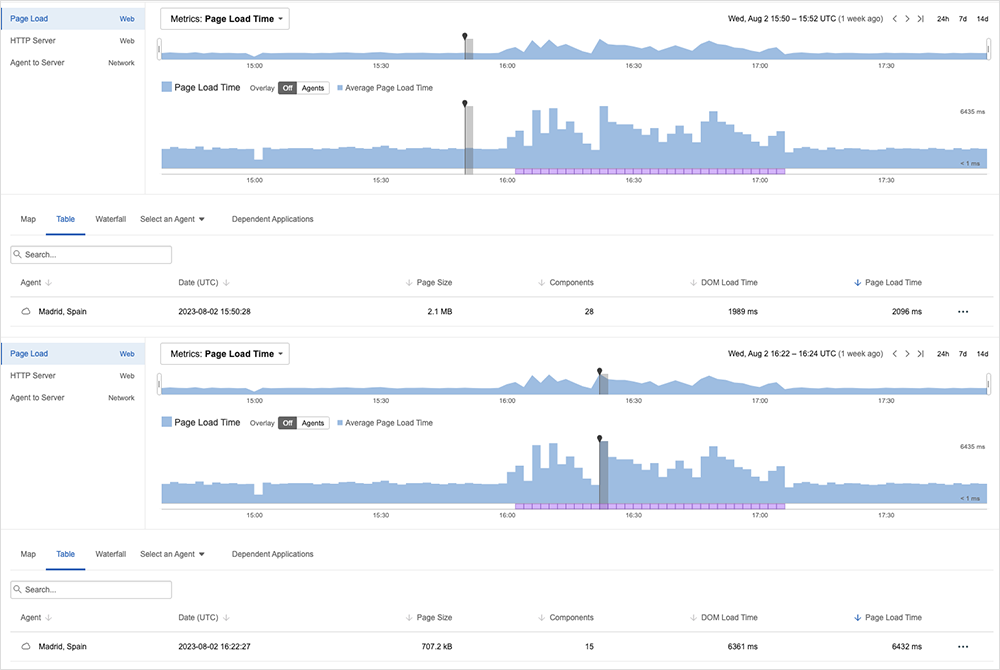
The Slack web client normally loads around 28 objects in order to function. But at the height of the incident, it appeared to be loading just 15 of these. Given this, there were signs early on that Slack’s issues likely related to problems with the application backend.
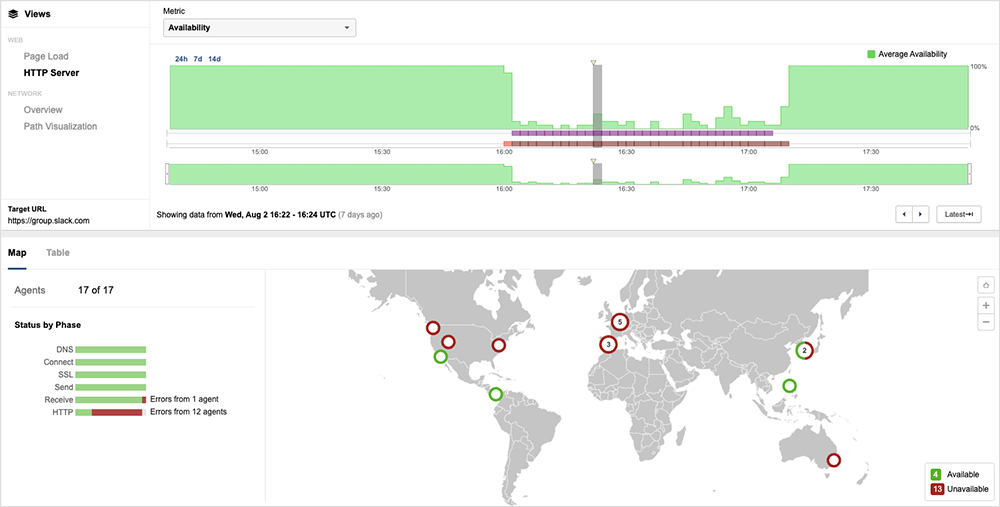
There also didn’t appear to be any known problems with the aggregating technology that forms part of Slack’s infrastructure—further suggesting application backend issues. For example, the Slack service frontend servers are hosted in AWS, but other applications hosted on the same AWS environment weren’t showing any issues. In addition, the network paths to its servers did not appear to be impacted by traffic loss, latency, or jitter.
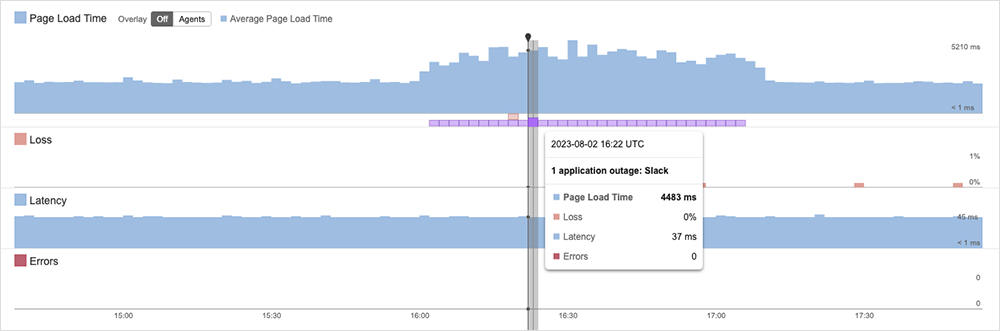
The incident had a couple of interesting features.
The first is that the disruption started exactly on the hour. Timing like that normally points to the root cause being some form of maintenance work that had unanticipated consequences. But that’s not what the data shows this time. Instead, the incident was comprised of a series of peaks and troughs, suggesting that impact was intermittent and unevenly felt across the user base.
The second interesting point comes directly from the post-incident report: The root cause was work on one part of the service—a “routine database cluster migration”—that accidentally reduced database capacity to the point that it could not support a regularly scheduled job running.
The job, which Slack said “commonly occurs at the top of each hour,” checks and renews the custom status indicators, which denotes their availability to chat or engage. Perhaps unsurprisingly, this requires a lot of database requests or calls.
Whether through good planning or good fortune, it appears the scheduled job hadn’t ever run at the same time as a database cluster migration. Slack’s description of the migration activity as “routine” suggests it occurs frequently enough not to be considered as posing a potential concern or problem.
This time, however, was different: The scheduled job, combined with the normal operational needs of users, saw database requests gradually build up to the point at which they choked the queue. As Slack notes, “the number of incoming requests exceeded the unintentionally reduced capacity of the database cluster, leading to errors and sluggishness for some actions in Slack. As these requests piled up, other Slack services began to experience issues as well, including a small number of users being unable to connect.”
Slack mitigated the issue by initially pausing the scheduled custom status job in order to mitigate the load on the affected database cluster. This appeared to resolve some of the errors affecting Slack services. Once Slack established they had sufficient capacity to handle the scheduled job, they resumed processing the custom status requests, fully restoring normal service for all affected users. They then “deployed a fix to correct the issue with the database cluster migration, bringing capacity back to the expected level.”
It’s possible that the Slack teams responsible for different parts of the service could have been unaware of what each was doing, or the potential impact of their activities combined. Run in isolation, there was nothing wrong with the cluster migration or scheduled status checking jobs; it was only when they ran in parallel that a problem manifested.
While Slack probably wouldn’t have found this issue in pre-testing, the migration team should in theory have been aware of scheduled activity that generates a certain amount of database load once an hour, and timed their own work as such. Of course, it’s possible they were aware, but had simply forgotten to factor it in.
Though we don’t know exactly what happened at Slack or all the systems they had in place, the incident is an important reminder that working on complex, distributed web-based applications or services will likely involve multiple groups—and sometimes multiple organizations—that will typically only be focused on processes and performance in their area of responsibility.
Good communication and coordination between teams can help guard against this, as well as contextual visibility into the end-to-end service delivery chain.
Spotify Outage
On August 5, Spotify experienced a functional failure where searches yielded no results and non-downloaded content failed to render.
While the application itself was functioning and existing downloaded playlists worked as normal, the backend search API, or the API that instigated the search, appeared to fail. The way the problems manifested suggests that a change to the search API was made and rolled back. There’s no official explanation from Spotify, however.
The lack of information during the outage meant users took a range of actions to fix the issues, from rebooting their systems to deleting and reinstalling the Spotify app.
West Africa Cable Cuts
The West Africa Cable System (WACS) and the South Atlantic 3 (SAT-3/WASC) cables have suffered new breakages in early August. The same cables have experienced cuts in the past due to weather events.
In this instance, however, newer cable capacity in the region meant that traffic could be mostly diverted around the cuts. We frequently now see this kind of route diversity worldwide, with fewer single routes in and out of countries, or between countries or continents. This has significantly aided the Internet’s resilience and ability to deal with ambient or anomalous operating conditions.
Wells Fargo Outage
On August 5, for the second time this year, Wells Fargo experienced an issue with its banking apps where deposits did not show up in customers’ accounts. The nature of the outage hasn’t been officially explained, but—on the surface—it has some similarities to recent issues at Australia’s Commonwealth Bank, where users faced excessive wait times when trying to call information from the backend systems sitting behind the banking app UI.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (July 31-August 13):
-
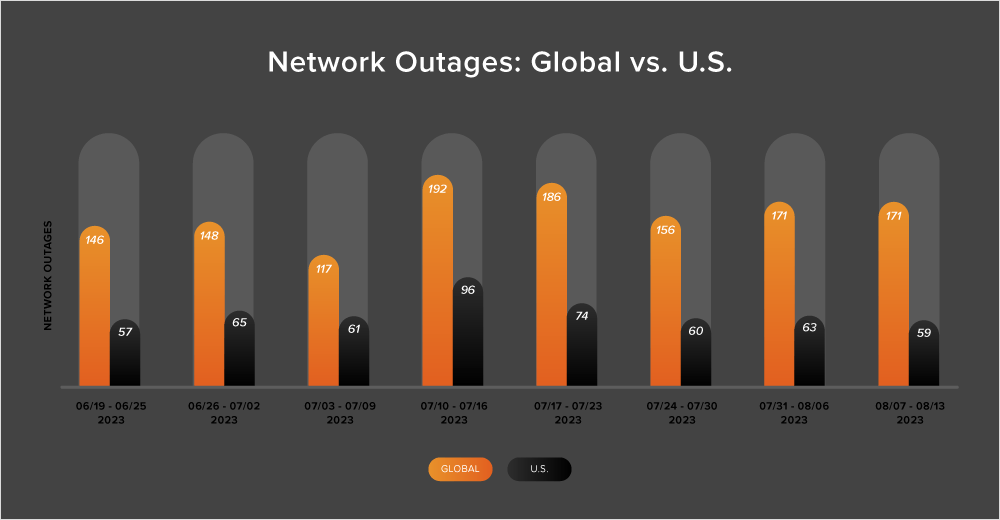
Global outages exhibited a slight upward trend over this two-week period, initially rising from 156 to 171, a 10% increase when compared to July 24-30. This was followed by a rare week where the total outages observed remained constant (see the chart below).
-
This pattern was not reflected in the U.S. While U.S.-centric outages initially rose from 60 to 63—a 5% increase when compared to July 24-30, they then dropped from 63 to 59 the next week, a 6% decrease.
-
U.S.-centric outages accounted for 36% of all observed outages from July 31 - August 13, which is somewhat smaller than the percentage observed between July 17-30, where they accounted for 42% of observed outages. This is the first time since April that U.S.-centric outages have accounted for less than 40% of all observed outages.
-
Looking at total outages in the month of July, global outages dropped from 710 to 691, a 3% decrease when compared to June. This pattern was reflected in the U.S., with outages dropping from 310 to 308, a 1% decrease. This downward trend reflects patterns observed in previous years across the Northern Hemisphere summer.