This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages. As always, you can read the full analysis below or tune in to the podcast for first-hand commentary.
Internet Outages & Trends
The past couple of weeks saw fairly flat outage numbers, which is in contrast to the sharp peak we observed at the beginning of May. It now seems that this initial peak may have been related to something analogous to the practice of “spring cleaning,” which increasingly seems to extend to IT and network environments as well.
When we look back at the data collected by ThousandEyes over the last several years, there are discernible outage peaks within two to three weeks of each other during the same time of year in 2021, 2022, and now 2023.
It could be that a lot of IT shops do a final “spring clean” of their infrastructure setups at this time, seeing it as an opportune slot to schedule additional engineering and maintenance work. A rise in this type of work could lead to more unintended service degradations or outages—and this is precisely what I believe the year-on-year trends seem to indicate.
While spring cleaning at your home might be a spontaneous weekend project, IT and network-related work requires careful planning and a good understanding of how everything is connected together, because—like a Jenga puzzle—it only takes one block to be pulled from the model for everything to fall down.
Read on to learn more about recent outage trends, as well as some key outages and degradations seen in the past fortnight, or use the links below to jump to the sections that most interest you.
Twitter Spaces Outage
Twitter used its live audio conversations feature, Twitter Spaces, on May 24 to host a presidential candidate announcement by Florida Governor Ron DeSantis. The event was impacted by technical problems that impacted access and user experience with the Twitter Space at the beginning of the event.
Outside of Spaces, Twitter appeared to be functioning normally. The problems seemed to be with access to that one specific Spaces stream, hosted from Elon Musk’s profile.
To understand this incident, it’s worth dwelling a bit on how a Spaces stream operates. Spaces is launched from an individual user’s profile, but the URL for the stream allows anyone to listen in. Technically, both followers and non-followers of the host can listen. In addition, non-Twitter users can tune in from a browser, without having a Twitter account.
The high number of users trying to access the stream concurrently may explain the issues during DeSantis’ candidacy announcement. However, we consider it more likely that the bottleneck was at the entrance point to the stream, rather than the stream infrastructure itself being unable to support the number of concurrent users wanting access.
When a user initiates a Space from their profile, all their followers will be able to see that the Space is active and, in some cases, will also receive a confirmation. This process would essentially involve verifying whether any user, irrespective of their intent to join the Space, is a follower of that account in order to determine whether (or not) to notify them about the active Space. During the DeSantis event, it could be that this type of process was overwhelmed by the volume of checks it was required to perform—the event was hosted from Elon Musk’s Twitter account, and he has well over 100 million followers.
Regular readers will know that we often talk about single points of traffic aggregation, which can lead to degradation and potentially failure. These can often be identified and understood by mapping out and monitoring the different parts or components that, together, enable the end-to-end process.
However, in the case of this Twitter Spaces event, it likely would have been pretty difficult for Twitter to identify a potential bottleneck beforehand. In general, best practice architecture testing methodologies would have focused on testing front-end and back-end service capacities, but likely wouldn't have surfaced a potential bottleneck.
Max Outage
The recently launched subscription-based streaming service, Max, formerly known as HBO Max, experienced some issues during its May 23 debut with users encountering some inaccessible streams. A spokesperson initially attributed the problems to a scale issue, and this does appear to be the cause: a large number of customers all hitting the service at launch time to try it out. It may also have been related to an enhancement included in the service itself, which is 4K UHD streams. It’s possible that the streaming service simply underestimated concurrent demand for 4K content, causing requests for that content to become oversubscribed, and the service became temporarily overloaded as a result.
As mentioned in the discussion of the Twitter event above, it’s somewhat challenging (and expensive) to design a system to handle a peak load it may only ever see once. Streaming services typically use a form of statistical multiplexing to handle concurrent streams through a bandwidth-limited channel. This is designed on the assumption that not every subscriber is going to be pulling down content all of the time. In the rare times when everyone does try to use the service concurrently, load-related issues can arise.
Microsoft 365 Outages
On May 23, Microsoft reported issues with content rendering on office.com and other services that come under Microsoft 365. The services could still be reached and partially loaded, but elements of the page content would not render due to backend calls to other services that failed to complete. This manifested to users as either incomplete page loads, or as unresponsive pages and timeouts.
The incident impacted users globally; although, it would have been mostly felt in Oceania and nearby regions where it was during business hours, rather than North America where it was the middle of the night. Service disruptions appeared to occur in several “bursts” or “waves,” which might indicate that Microsoft engineers were making a series of attempts to remediate the issue, before finally finding a resolution that worked.
Just over a week later, on June 5, Microsoft experienced another outage impacting Microsoft 365 services. This outage was made up of several sustained periods of disruption spread over 27 hours.
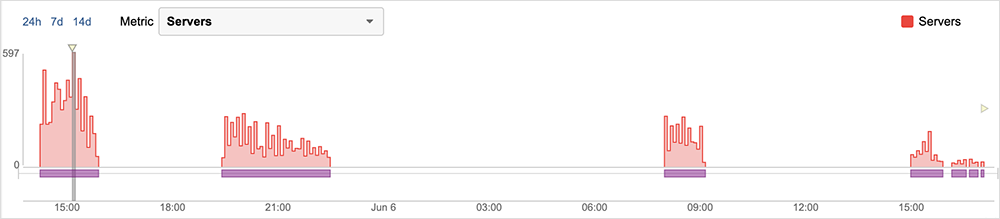
It was first observed around 14:16 UTC, manifested by a series of HTTP 503 errors that resulted in decreased application availability across some Microsoft 365 services for global users trying to access these services. As mentioned previously, the prevalence of HTTP 503 and timeout errors is indicative of reachability issues with back-end systems, as opposed to any network reachability issues connecting to the services. Microsoft announced that they had halted some recent service updates and subsequently rolled the changes back to restore the services. Services started becoming available again around 30 minutes after the rollback announcement, with the servers responding to HTTP requests normally.
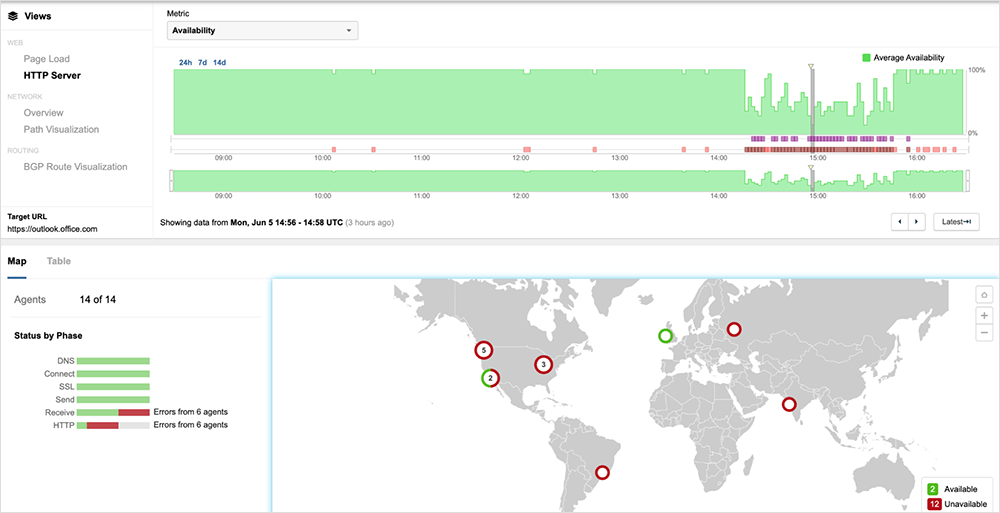
Around 3 hours and 30 minutes after appearing to clear, the outage reappeared, exhibiting the same symptoms as the previous outage, with most locations receiving connection timeouts for global users trying to access these services. This second occurrence lasted around 3 hours and 3 minutes. Services appeared to return with access completely restored around 22:30 UTC. However, 8.5 hours later, the issue appeared to return again with Microsoft announcing soon after that they were experiencing a recurrence of the issue and a drop in service availability, and were going to apply mitigations to provide relief for the affected users. This third occurrence lasted 68 minutes and appeared to clear around 9:10 UTC—before re-occurring at 15:00 UTC for 52 minutes and again for a fourth time around 16:10 UTC for 24 minutes.
Slack Outage
Slack users encountered error messages when trying to connect to the service for a 30-minute period during the mid-morning (PDT) on May 17. The company acknowledged the load problems in a status advisory and attributed them to an operational change made in error that caused its databases “to become inaccessible.”
Users trying to access Slack at the time may have encountered long waits, then timeouts as the app constantly sought to pull content from backend systems, but couldn’t locate them, or simply received HTTP 503 error service unavailable responses.
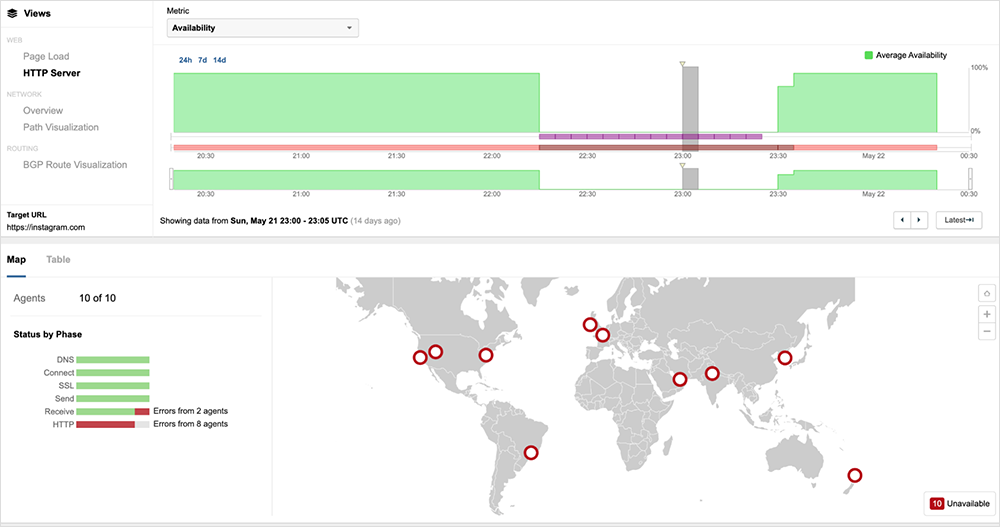
Instagram Outage
A “technical issue” left users globally unable to access Meta’s Instagram on May 21. Users attempting to open the app were greeted with an error message that read “Couldn’t load feed.” Refreshing the homepage and profiles did not appear to work. The impact of the outage was global, with services appearing to return around 1 hour and 15 minutes after first being observed.
We observed 5xx errors, indicative of backend issues and services being unavailable. However, 560 and 564 errors were particularly prevalent. These are less-common error codes to encounter because 560 and 564 errors have specific proprietary meanings, based on the suite or platform they appear in. At a broad level, any HTTP error code from the 5xx group means the problem was caused by the server, and, as such, they point to server-side errors and issues such as instability in the server, potentially following multiple resets and/or potential authentication mismatches.
Apple’s iMessage Issues
On May 23, Apple confirmed “some users” were “unable to send or download attachments in iMessage.” The problems did not appear to impact all users globally, only certain subsets of Apple’s infrastructure.
Additionally, the issues didn’t appear to generate a significant number of outage reports. One of the reasons for this could be that iMessage has an automatic backup mechanism that kicks in when iMessages can’t be delivered over the Internet, allowing users to send the messages via SMS instead. People can tell when this backup option was used as their sent messages will have a green bubble, instead of the regular blue. Users who did report experiencing issues during the May 23 iMessage disruption may have noticed this backup kicking in, prompting them to report that messages were sending via SMS instead of iMessage as normal. However, other users may have had the SMS feature turned off and, therefore, reported that messages failed to send at all.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends we observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (May 22 - June 4):
-
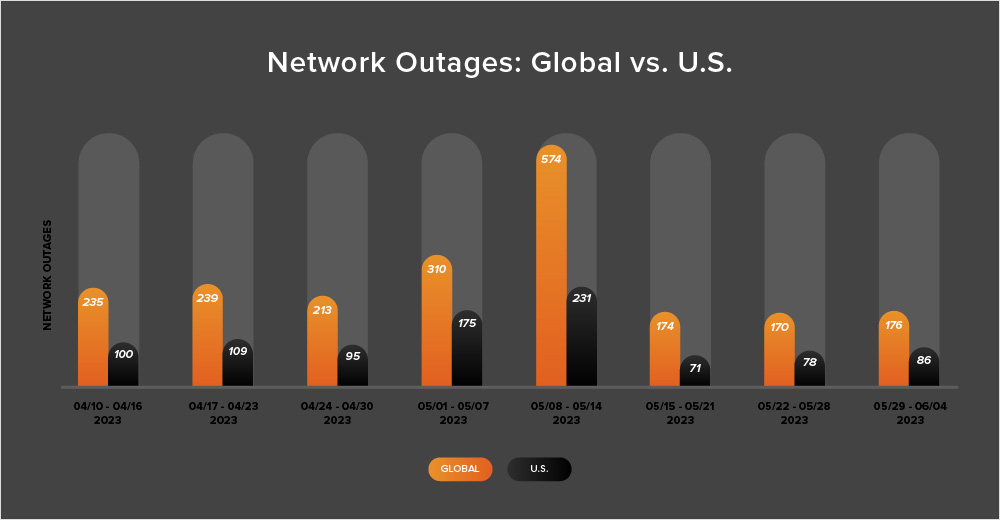
Following the sharp spike seen at the start of May, global outage numbers were reasonably stable during this two-week period, initially dipping slightly from 174 to 170—a 2% decrease when compared to May 15-21. This was followed by a slight rise, with global outages increasing from 170 to 176, a 4% increase compared to the previous week (see the chart below).
-
This pattern was not reflected in the U.S. as outages consistently increased across the period, initially rising from 71 to 78, a 10% increase when compared to May 15-21. U.S. outage numbers also increased by 10% the next week, rising from 78 to 86.
-
U.S.-centric outages accounted for 47% of all observed outages from May 22 to June 4, which is larger than the percentage observed between May 8-21, where they accounted for 40% of observed outages. This continues the recent trend seen over the last several weeks in which U.S.-centric outages have accounted for at least 40% of all observed outages.
-
Since this two-week period (May 22 - June 4) includes the end of May, it’s also worth taking a look at total May outage numbers, compared to April’s outage numbers. In May, total global outages rose from 1026 to 1305, a 27% increase when compared to April. This pattern was reflected in the U.S., with outages there rising from 451 to 597, a 32% increase. This ends the trend observed in both March and April, where global outages decreased each month while U.S.-centric outages increased.