This is the Internet Report: Pulse Update, where we analyze outages and trends across the Internet, from the previous two weeks, through the lens of ThousandEyes Internet and Cloud Intelligence. I’ll be here every other week, sharing the latest outage numbers and highlighting a few interesting outages.
With tax season upon us in the United States and various tax-related websites likely experiencing unusually high volumes of traffic, this week we're including a special segment on Tax Day best practices for ITOps and important considerations for organizations as they navigate times of the year that bring major spikes in demand—whether that be Tax Day or Black Friday.
As always, you can read the full analysis below or tune in to the podcast for firsthand commentary.



Navigating U.S. Tax Season and Spikes in Demand
As the U.S. tax season draws to a close for most taxpayers on April 15, IT teams at tax preparation companies and other organizations in the industry will be paying special attention to make sure their systems can handle any last-minute rush of filings. The IRS website last experienced a major tax-time outage in 2018, directing last-minute filers to “come back on December 31, 9999” instead. (An extension was granted, though not for an extra 7,981 years).
Generally, scenarios that occur at critical times like this tend to lead to investments that should help ensure systems are more resilient and scalable to future encounters with anomalous performance or load. Listen to the podcast for a full discussion of the operational mindset for Tax Day performance and availability—and how ITOps teams in other industries can prepare for similar seasons of high traffic.
Internet Outages & Trends
Many tweaks to configurations and code today are done in the pursuit of performance improvements—shaving milliseconds off page load times, reducing latency, and generally allowing users to transact in the shortest amount of time possible.
Against this backdrop of constant optimization, an observed improvement or variation in the performance of one or more of these areas may indicate an enhanced customer-facing digital experience—but it may also be an early warning sign of potential issues.
For example, on April 3, operations teams may have observed reduced page load times for interactions with some Apple services including on the App Store and streaming services. In isolation, operations and admin teams might have seen this as a positive development—a sign, perhaps, that optimization work was delivering customer-facing benefits. However, in this case, the faster page loads were actually a signal of functional failures within the service—as a number of page objects failed to load. This is a familiar pattern we often see, including during a July 2023 Microsoft Teams degradation.
Sudden variances and anomalies in performance can reveal issues related to backend or dependency functions. IT teams need to be able to look across the end-to-end service delivery chain and consider all the signals in context to triangulate why that variance has occurred, and more importantly, what it means. Viewing everything on one timeline makes it easier to deduce a problem on a backend system, especially when indicators of performance for the front-end experience provide few clues that anything problematic is happening.
Read on to learn about the Apple incident and other recent outages and degradations, or use the links below to jump to the sections that most interest you.
Apple Outage: App Store, TV+, and Music
On April 3, some users of Apple services, including the App Store, Apple TV+, and Apple Music, were impacted by issues across multiple regions. From ThousandEyes test data, it appeared that affected users would have been able to access and load some content from, for example, the App Store or the streaming services. However, attempts to then action some component on that page, such as update, download, install, etc., resulted in a combination of timeouts, failures to connect, or service unavailable errors.
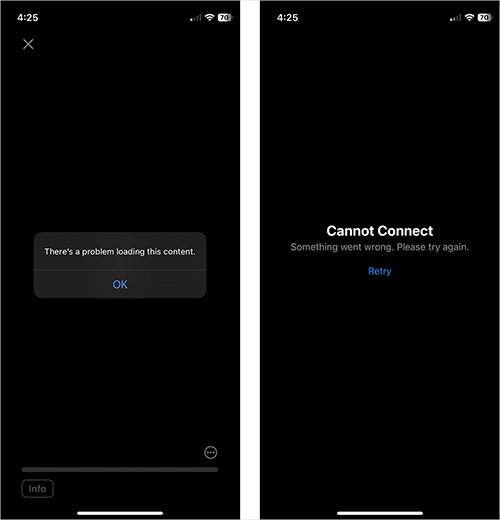
When taking actions like these, users reported receiving “failure to connect” messages. When attempting to play content on the Apple TV app, for example, one ThousandEyes team member we spoke to encountered a “problem loading” error; when trying to open the App Store app, they were greeted by a “Cannot Connect” message.
The impact was felt by subsets of Apple users around the globe. In addition, there were regional variances in the kinds of apps, content, and other functionality that didn’t load correctly or didn’t appear to work. This may be because different regions have different content licensing arrangements or offer a different set of apps for download, and users were trying to access apps or streaming content specific to their region. However, the issue causing these various difficulties appeared to be similar, regardless of region.
What was the common cause? While no official explanation has been offered, my best guess is that it’s possible Apple was making adjustments to an API or set of APIs utilized by these services. All impacted services had similar needs to call other programs or systems so the app could build searches or retrieve content.
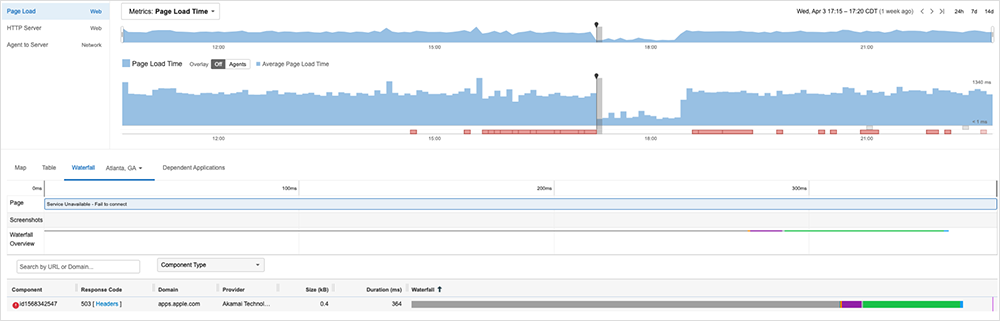
Looking at the App Store page for a popular fast food restaurant’s app, ThousandEyes’ tests loaded static information associated with that page (as well as information cached in CDNs), which would have allowed the page to render content and subsequently give the impression to the user that service was functioning normally. However, additional ThousandEyes data reveals a different story. When the page made a series of backend requests to bring in other pieces of information, such as developer notes and new versions, these API calls repeatedly failed to find what they were looking for in Apple’s backend.
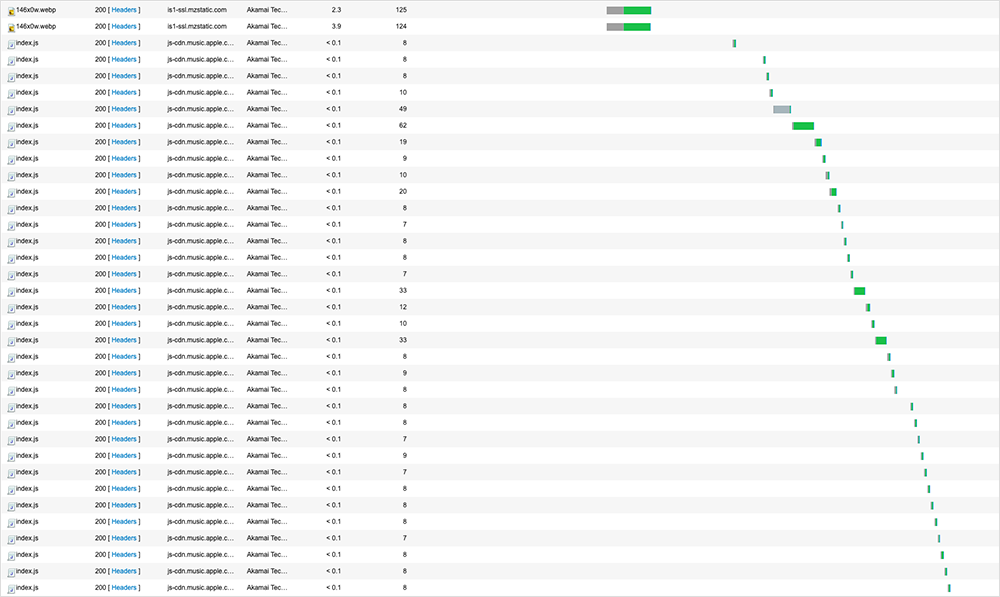
ThousandEyes tests show a clear “step pattern” in which the page appeared to repeatedly seek to identify the backend service and associated content, but it was unable to and ultimately timed out.
WhatsApp, Other Meta Services Disrupted
Also on April 3, some Meta services—notably WhatsApp, and to a lesser extent other services such as Messenger—experienced global service disruptions. Users were able to reach WhatsApp’s front page and even send messages; however, the send ultimately failed.
ThousandEyes observations indicated that the service disruptions weren’t due to network issues connecting to Meta’s frontend web servers. Network paths to WhatsApp services appeared clear during the incident, suggesting that the issue was on the application backend. Meta later confirmed this, noting the outage related to APIs for connecting to WhatsApp, Messenger, and Instagram.
This outage represents the second significant Meta outage in the last two months, with a March 5 disruption also preventing some users from accessing Meta services including Facebook and Instagram.
Square Outage
On April 1, starting at 2:36 PM (UTC), Square experienced a service disruption that impacted payments running on Android and Square hardware. The root cause, according to Square’s official write-up, was “a new feature configuration that could not be properly interpreted by Android mobile applications.”
“The introduction of new feature configuration resulted in malformed JSON sent to Square’s mobile applications,” Square said. “Each platform handled that network response differently. iOS properly identified the issue and rejected the latest response content. Applications running on Android or Square Hardware's Android-based operating system emitted a crash report and closed the application. Square hardware immediately relaunched the application. Android devices waited for users to relaunch the application.”
“The frequent relaunches from the affected platforms caused significant traffic increases, compared to normal patterns, on specific APIs,” Square reported, noting that this led to a functional failure in being able to accept or process transactions.
The configuration was rolled back at 3:25 PM (UTC), which led to technical resolution. Square recommended that retailers impacted by the issue temporarily switch to using an “offline mode to accept payments,” reminiscent of the workaround seen recently when McDonald’s had issues with its own payment systems.
Panera Bread Outage
U.S. restaurant chain Panera Bread recently experienced a week-long outage that started on March 22 and, according to reports, impacted its “internal IT systems, phones, point of sales system, website, and mobile apps.” Sources familiar with the matter have identified a cyber attack as the cause, though nothing has been officially confirmed.
The duration of the system unavailability is consistent with past patterns associated with cyber attacks, where systems and servers are taken offline to allow them to be checked, cleansed, or re-imaged, so that regular operation can be safely restored.
Performance as a Cyber Indicator: XZ Utils Vulnerability
A maintainer for PostgreSQL uncovered a backdoor in XZ Utils, a compression tool “used in nearly every Linux distribution” after trying to pinpoint the source of a 600ms performance lag—and high CPU utilization—associated with Secure Shell Protocol (SSH).
While most of the attention has focused on the potential attack that was thwarted, the way it was uncovered highlights the value of observability: being able to benchmark the performance of an app tool or service, recognize a minor variance in its behavior, and then pinpoint why that behavior has changed.
By the Numbers
In addition to the outages highlighted above, let’s close by taking a look at some of the global trends ThousandEyes observed across ISPs, cloud service provider networks, collaboration app networks, and edge networks over the past two weeks (March 25 - April 7):
-
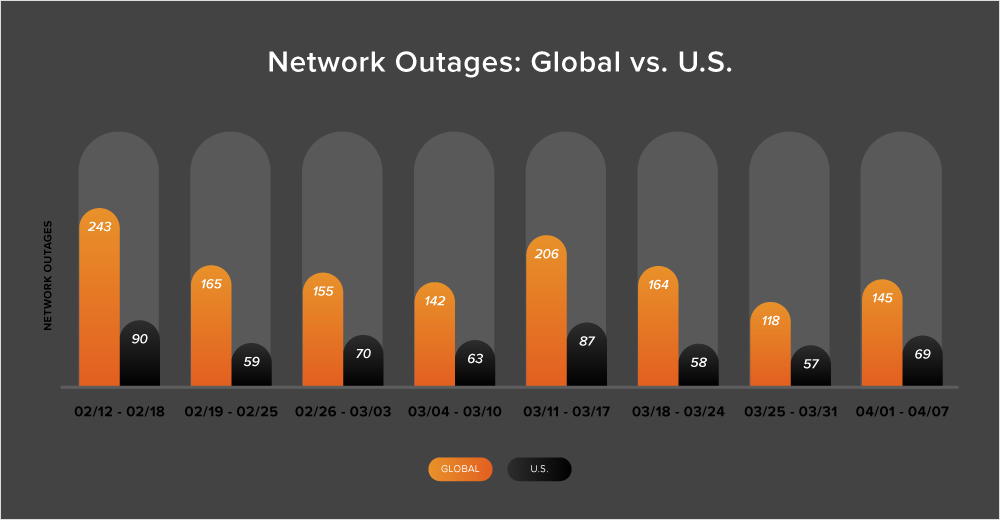
Global outages have been decreasing steadily since early March, and this trend continued into the last week of March. The number of outages fell from 164 to 118, a 28% drop. However, in the subsequent week (April 1-7), the number of outages increased by 23%.
-
During March’s final week, the United States experienced a slight 2% decrease in outages from 58 to 57, followed by a 21% increase in the following week (April 1-7).
-
Between March 25 and April 7, 48% of all recorded outages were observed in the United States. This represents a return to the longstanding trend of at least 40% of all outages being U.S. centric.
-
Looking at the full month of March, there were 678 outages observed globally, which was a 32% decrease compared to the 1,001 outages reported in the previous month. Similarly, the United States experienced a decline in outages from 314 to 289, an 8% drop. This decrease in the number of outages between February and March is consistent with the observations made during the same period in previous years.