


This week on the Internet, some Internal Revenue Service (IRS) websites experienced degraded performance, theoretically coinciding with the U.S. federal tax deadline; Instagram experienced a brief outage; and Atlassian offers an official explanation of the incident we covered in last week’s blog.
In recent years, traffic to IRS web properties has multiplied. Approaching the final filing day of the tax year, it’s likely that a considerable amount of pre-planning went into ensuring system availability. Still, some last-minute filers reportedly experienced issues, such as pages timing out, or pages with error messages when trying to complete certain aspects of the process.
According to the source, the reported explanation was of some “short delays or wait times to access some features” due to high demands on its digital services. This is very much in line with what we observed: The front end of IRS’ digital properties remained reachable and accessible throughout, but some processes that were called upon and ran in the background started to time out.
Consistent with the macro trends in modern application development, government systems generally aren’t monolithic these days and rely on the cloud and other dependencies like CDNs, backend services and authentication systems to enable the end-to-end process delivery.
Conventional wisdom states that more moving parts means more maintenance and a higher likelihood of breakage. Just one of those backend dependencies not scaling could mean a degraded experience for some users.
In the case of the IRS, we also observed a geographically uneven distribution of the degradation, with some cities or states more impacted than others. It’s difficult to determine why this is, but perhaps some locations see higher proportions of filing at or near the deadline than others. Additionally, it’s possible these locations might not be the same each year, which could complicate capacity management planning efforts from year to year.
It is imperative to point out that while users experience degraded performance, this was not an outage. However, it must be said that users often don’t distinguish between the two. It’s important to the organization because the thresholds for degradation and outages are likely to be very different, and outage duration is tightly managed in highly regulated environments. But to users, “outage” and “degradation” can mean the same thing: a painful experience that is best avoided.
Also, on the Internet this week, we saw Atlassian restore services to all users impacted by an incident where a faulty script “improperly deleted” the active cloud instances of 400 customers. The post-incident report confirmed much of what we had seen; an incident with a focused rather than a widespread blast radius.
One of the unusual challenges with this incident is that Atlassian appears to have had limited visibility into which customer instances were deleted, and it seemed to rely predominantly on customers self presenting to their support teams. The challenge was that the outage manifested as a bit of a Schrödinger's cat experiment: Was a customer really deleted if Atlassian support teams didn't know they were deleted? Impacted users would have been presented with few clues as to why their services were suddenly inaccessible, and it would have taken some time to diagnose. Additional visibility on the vendor side may have assisted in understanding what had disappeared, allowing rectification work to start quicker, and potentially without direct customer input.
Finally this week, on April 19th, Instagram suffered a brief outage, although impact was fairly limited, likely due in part to the time of day it occurred.
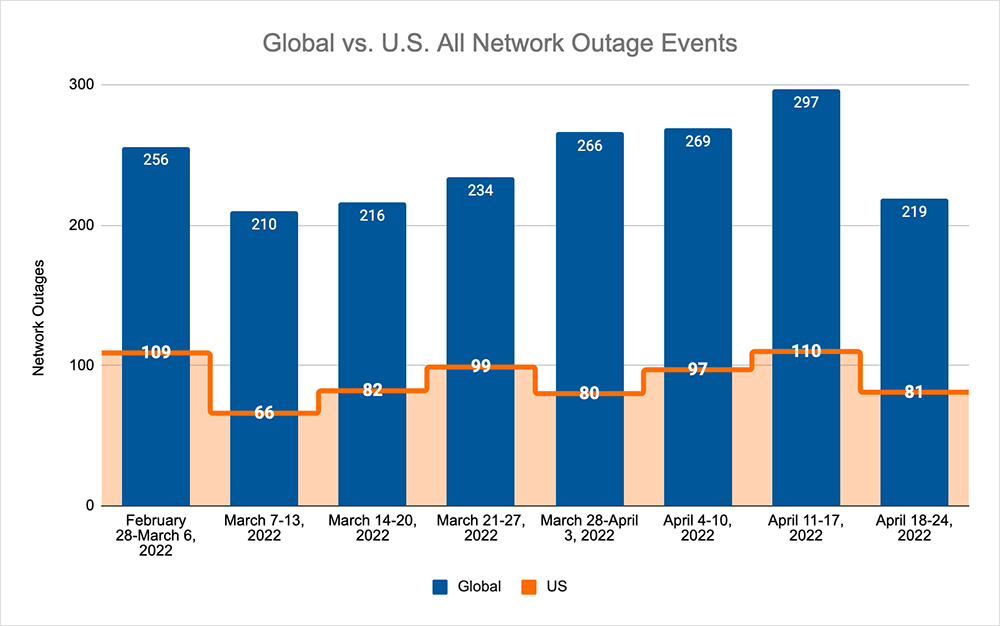
Before we take a look at the year's outage trends, let's delve into this week's outage numbers. The total number of observed global outage numbers decreased this week, following a three-week upward trend, dropping from 297 to 219, which is a 26% decrease compared to the previous week. This was reflected domestically where numbers dropped from 110 to 81, which was also a 26% decrease when compared to the previous week. In total, U.S. outages again accounted for 37% of all global outages this past week.
2022 Early Trends
We’re now far enough into 2022 to take a deeper look at ThousandEyes’ data to explore some of the emerging outage patterns.
One pattern is that the typical day for an outage to occur is aligned to Tuesday globally. The major change is to U.S. outages, which have trended to Tuesdays instead of Fridays, which is when they occurred during the early part of the year.
We have also seen a dramatic reduction in U.S. outages as a percentage of global outages. Where last year, outages in the U.S. represented around 44% of all outages globally—and sometimes more than 50% of all outages in a given month—the U.S. is now responsible for 39% of all outages globally, on average.
As this trend continues, we’re beginning to see an even split regionally between Asia Pacific, North America and Europe, each responsible for about one-third. This is likely indicative of the spread of cloud infrastructure outside of North America, such that infrastructure is more distributed and less likely to be drawn back to U.S. servers or connectivity infrastructure at some point.
There are also trends emerging in the overall numbers: outages experienced by cloud service providers have increased in number, frequency and impact, while the trend for ISPs is the reverse. We’ll have more to say about these trends in future blog posts as 2022 progresses.









