


This week on the Internet, we saw a pair of application outages as well as a broader question being raised: after a public cloud service outage impacts your business, what’s an appropriate and proportionate response to take?
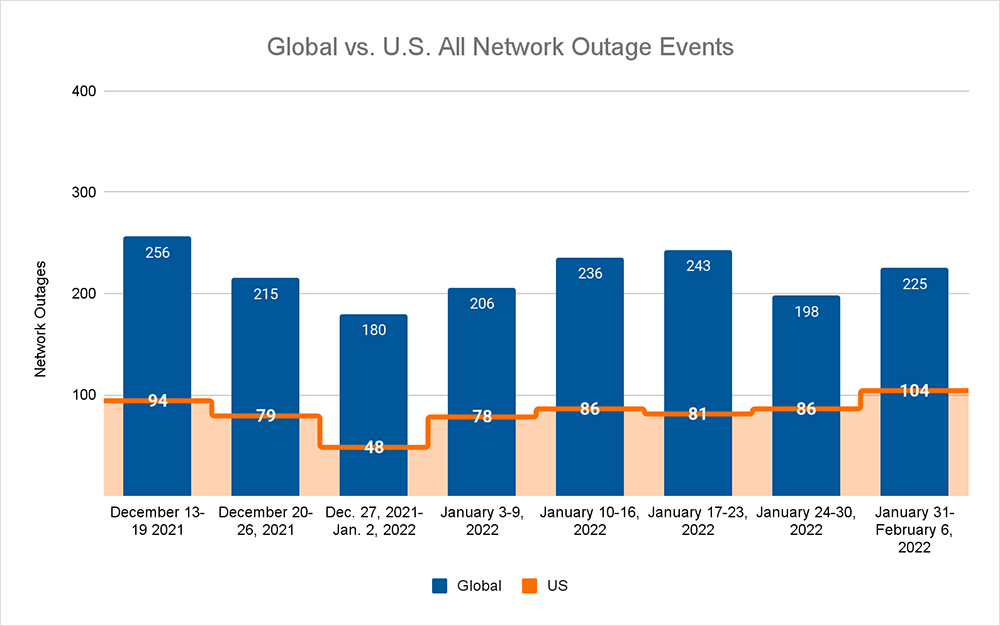
But, before we dive into that, let’s take a look at this week’s outage numbers. Following two weeks with numbers trending down, last week saw global outage numbers increase by 14%. This downward trend hadn’t been the same for the U.S. over the previous weeks, and this week the upward trend continued with domestic outage numbers observed increasing by 21%. Last week saw U.S. outages accounting for 46% of outages observed, which is a 9% increase compared to the beginning of the year and a return to 2021 average numbers.
And now, back to the application outages I mentioned earlier.
Fortnite’s game servers went offline for about two hours in the afternoon of February 1st, U.S. West Coast time. The outage occurred about nine hours after a scheduled maintenance window to apply a software update.
A bit later on the same day, email marketing automation service Mailchimp had an issue that lasted around an hour.
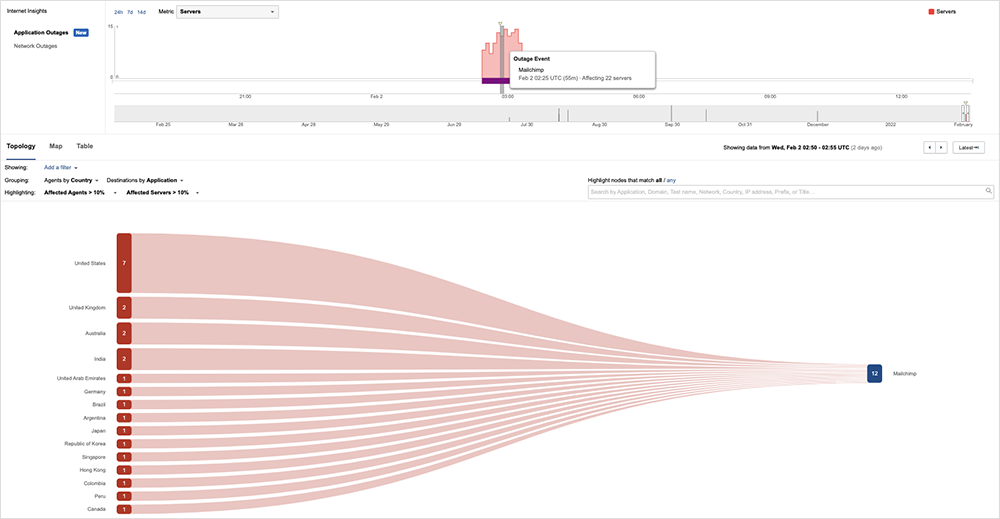
There were fewer public complaints about Mailchimp, in no small part because it wasn’t immediately apparent that there was even an issue. According to reports on Mailchimp Twitter feed, customers could still schedule and “send” campaigns, but the campaigns didn’t execute as they had expected. This may have led to a delayed reaction among customers, as it took some time to realize that no one had received campaign emails.
Another thing to note is that email campaigns are less time-sensitive than online gaming workloads. Gamers are in the moment and want to play. Not being able to access the game is a problem. Not receiving an email campaign right away, perhaps less so. If an email campaign fails to send correctly, it can be re-sent, with little to no harm done.
So, we had two outages of applications with very different usage requirements and characteristics.
This leads us into the second part of this week’s blog.
The nature of writing a weekly column on application and network outages means we often wind up with a discussion on detection and incident response. But what happens in the weeks and months after an outage is also interesting.
Irrespective of the cause or the responsible part of any impacted service provider, there’s likely to be a post-incident report and key learnings that, in blameless engineering cultures, will lead to system improvements.
Depending on the public-facing impact, customers may also do a bit of soul searching. The customer might initiate an architectural review to identify and work around dependencies on services or interdependencies between systems. They might also plan out new business continuity options to keep critical or core systems online in future when another unplanned outage inevitably occurs
What a customer probably won’t do is try to jump ship. It’s simply not a pragmatic or practical response to an outage, and realistically never has been.
In the on-premises world, a data center move was an absolute last resort, attempted only after catastrophic circumstances; where staying on past an outage event would be untenable or unthinkable. Even then, the transition took weeks or months of planning and sleepless nights.
Things are slightly easier in the cloud world, assuming your code is packaged for portability and you’re running on basic, generic infrastructure-as-a-service compute, but probably still inadvisable for a few reasons I’ll outline.
The first problem with trying to switch clouds (or ecosystem allegiances) on-the-fly during or following an outage is there’s no guarantee that the next host will be any more resilient. IT infrastructures aren’t perfect, and while most providers strive for—and often hit—very high availability targets, there will be instances where something they do or that they rely on upstream or downstream breaks. Better the host you know, than the one you know less about.
The second problem is that in the event of a cloud outage, your company isn’t going to be the only one impacted. As we frequently see, a cloud service outage can make large portions of the Internet appear inaccessible. End users understand these outages happen. They understand even more if the root cause is common across services they want to use, and that attribution is made clear.
In that way, companies hit by a cloud outage experience a kind of “herd immunity” to criticism: they’ve collectively made a call on the best place to host their application, they’ve architected it to best practice, and there’s little more they can do in the circumstances but sit it out, like everyone around them.
Yet, this idea that companies should position themselves to be able to shift the hosting of an application, or of some of its core components, in the event of a cloud outage still persists.
It just isn’t a practical nor pragmatic response in most instances. It also ignores what we know about cloud hosting and the importance of matching that to an application’s characteristics.
Each cloud service and provider has different services, characteristics and optimizations that may make the service better suited to host certain application types. This likely factored into the decision to host there in the first place.
A multi-cloud strategy—with portability between clouds—may not be best for the application or workload as it may introduce unnecessary latency into the user's experience. Instead, it may work better to architect for multi-region redundancy within a single cloud ecosystem. The choice should be guided by the application requirements, characteristics and users needs.
I’m likely to be speaking to the converted already, but in case it needs to be spelled out: your application requirements are more significant than any single outage to the underlying infrastructure. An outage is likely to trigger a review and key learnings, but it would be an extreme scenario to warrant a cloud ecosystem switch.








