


This week, reports emerged on the Internet of issues with accessing microservices, APIs and web applications across multiple cloud providers and environments. Similar to what we saw in late February, users tried to deduce a common link between all the impacted services, but the link just wasn’t apparent. Moreover, some of the “impacted” service providers reported seeing no signs of an outage within their own infrastructure.
These providers suggested the problem (if indeed there was one) was somewhere upstream of them, and that they otherwise couldn’t replicate the issues.
At this point, it started to look like a “phantom outage”; that is, until some major apps like Spotify and Discord started to report failures, which were quickly linked to an issue within Google’s cloud.
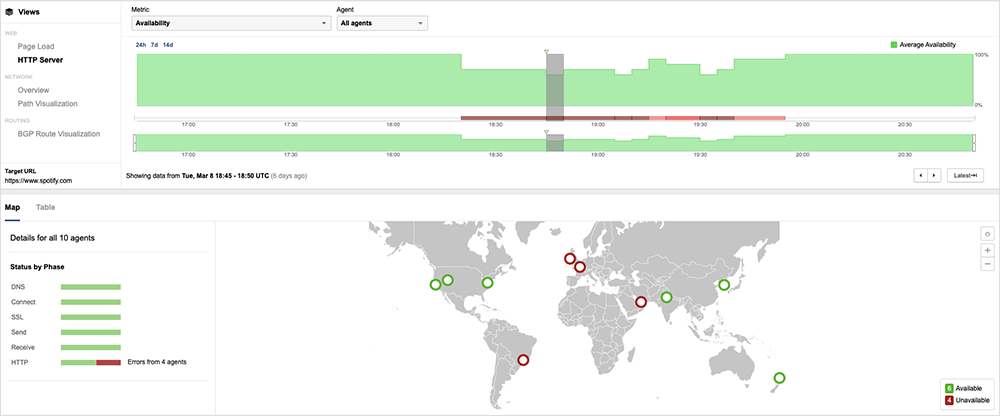
It then became apparent that Google was an “upstream provider” for the other impacted services, as well as other cloud providers. According to the official incident report, the issue was related to a Google's Traffic Director service used to load balance across clusters of containers or VMs that are split between regions of a single cloud or across different clouds. The same Google service can also be used to configure and run sophisticated traffic control policies.
There are good reasons to have this setup, particularly for web apps with global audiences. For instance, it makes it possible for some components to be served out of a central location while other more dynamic aspects of the experience, such as localized advertisement insertion, can be hosted in the country where the user is located. These pieces all need to be orchestrated so that the app works seamlessly, and software and service suites exist to do that.
If the software handling the orchestration starts to fail, this experience can be less seamless and impact users. This appears to be the case with the Google Traffic Director issue, which was introduced during a configuration update that then had to be rolled back.
The issue effectively deprogrammed customers’ Traffic Director-managed clients. “The effect of the deprogramming for users behind GCLB [Google Cloud Load Balancing] would have been visible as 500 errors,” Google stated in a brief post-incident report. “Some affected customers were able to mitigate the issue for themselves through the workaround of moving to backends that were not Traffic Director-managed.”
It’s worth highlighting a couple of things about this incident.
First, it can be challenging to pinpoint where an issue actually is without holistic visibility. The way this issue manifested itself led many users to look in all the wrong places. The root cause was relatively obscure, and being able to correctly identify it was dependent on how well customers understood where all their containers and services were being served from. This was real “network within a network” type complexity.
Second, this wasn’t strictly a widespread global outage, even though it had the potential to be one.
Some of that had to do with the timing, but also part of it was likely the result of the smart setups that cloud providers (and many of their customers) now employ. The sky didn’t fall for many companies, and users in many regions barely noticed there were problems, if at all, despite speculation of widespread issues.
For companies that did take longer to recognize and mitigate against the fault this time, one would expect them to perform much better if the situation was ever to repeat. Such is the life of a cloud engineer or SRE. Continuous improvement and delivery are baked into the ethos and core of the cloud operating model.
Large-scale web application providers use—and will continue to use—services like Traffic Director because they offer a way to give the best experience to users. They’re part of a smart architectural approach for web- and cloud-based businesses.
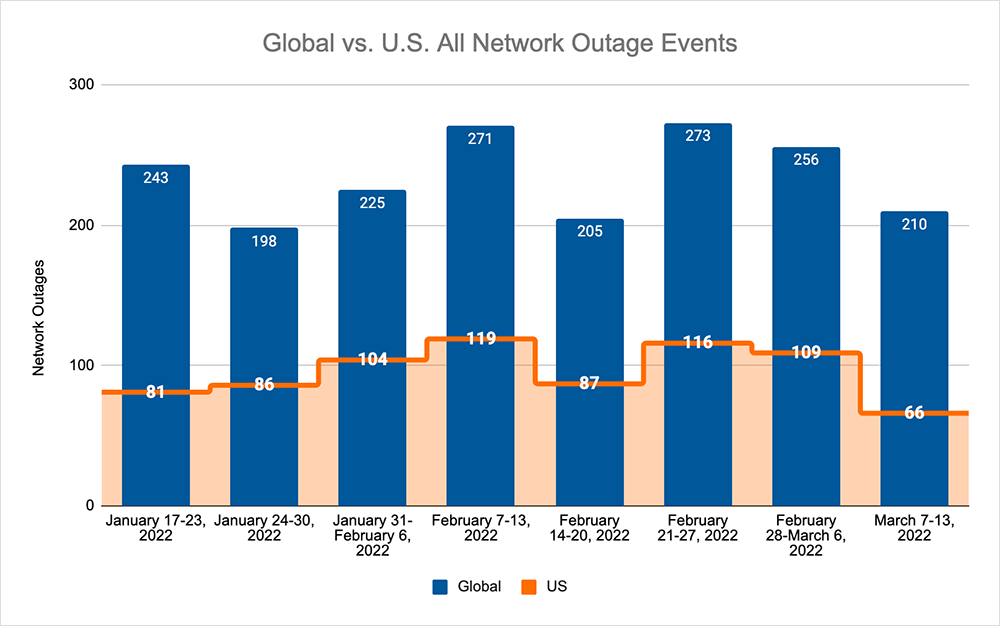
Over the past week, the downward trend in total global outage numbers observed previously continued for a third consecutive week, with levels dropping from 256 to 210—an 18% decrease compared to the previous week. This decrease was reflected domestically, with observed outages dropping from 109 to 66—a 39% decrease compared to the previous week. As U.S. outages had a larger drop compared to total global outages observed over the previous week means that U.S. outages contributed 12% less to the total global outage number compared to the previous week—domestic observed outages contributed only 31% of global outages last week.
The takeaway this week? Outages are endemic on the Internet, but the mere existence of outages doesn’t discourage large organizations from using the cloud to host and run mission-critical workloads. They’re confident in being able to engineer their setup to recognize degradation, mitigate against it, or recover from any degradation or outage situation. The cloud providers know they also have a role to play in this, and they are making efforts to reduce outages—or at least the potential blast radius of them.
In saying that, every outage experienced creates learnings and leads to improved architectural resiliency, and we’d expect no less in this instance.








