


The U.S. work week got off to a shaky start this past week, with some key Internet-based productivity tools, as well as a popular fitness app, suffering outages of varying degrees. On February 22, Slack reported that some of its customers were experiencing issues loading the application. Around the same time, Peloton users experienced similar issues. Then, GitHub users also reportedly started to see problems.
We’ve seen this scenario before—where a series of big-name applications and services start to experience problems. Usually, there’s a common denominator at fault, like an issue at a public cloud service or CDN that affects multiple services all at once.
The “correlation effort” started almost immediately, and—just as quickly—concluded that a cloud service provider was at fault. Case closed.
Except, the cloud provider’s status page was a sea of green. OK, well, the page may have not been updating from telemetry in real time. We’ve previously discussed in this column how problems experienced by users are sometimes not reflected in official status updates, or may only be reflected after an extended period of disruption. In this case, it was not practical to rule out a cloud provider issue based on their status page alone.
Except, the cloud provider then publicly backed the accuracy of its status page. That’s quite a bit more difficult to explain away, and it led to additional confusion as to what had just happened, and why.
Let’s go through what we know about these incidents.
First, there were real, not imagined, application accessibility problems that impacted end users.
Logic and past experiences dictate that there’s probably a common cause. Once upon a time, the default culprit would have been the network. Then, the common culprit was DNS (not without good reason). Now, it seems the popular theory for an outage is that it rests with the cloud.
It was immediately apparent—to us, at least—that this wasn’t a network problem. As we noted, network paths connecting users to Slack frontend services were clear, we also observed a number of application-based errors, indicating that the service was reachable (the application was responding), and there were no obvious DNS issues either. It was also not the fault of a particular cloud provider because the applications involved don’t actually share a single cloud provider.
By examining each application—Slack, Peloton and GitHub—it became clear the impact was limited to user transactions within the application itself.
In other words, the application as a whole wasn’t failing; the problem was with a part of the application or something plugged into it. In Slack's case, the outage was later confirmed to be the result of a configuration change that inadvertently led to a sudden increase in activity on the Slack database infrastructure. The impacted databases were then unable to serve incoming requests. Once identified, Slack began to restore the services by applying rate limits to reduce the load. This meant that some users could not access the system at all, but those who were already connected could continue to work. Once the system appeared to stabilize, Slack began lifting the rate limits. Unfortunately, as the rate limits were removed, the activity load issue returned. The rate limits were reapplied and, at the same time, Slack temporarily redirected requests to replica databases, reducing the demand on the primary databases and allowing the system to fully recover.
Applications, as we’ve previously established, aren’t self-contained. They rely on a complex ecosystem of plugins and dependencies, which have their own interdependencies on other services to operate and function. It only takes one of these elements in the end-to-end application delivery chain to break to affect everything upstream and downstream of it.
A plausible explanation for these three incidents is that, perhaps, the impacted applications share a common dependency that itself may have an interdependency somewhere with public cloud. That level of complexity is likely to lead to a misdiagnosis as to who bears ultimate responsibility, as well as ongoing uncertainty.
What we just saw could have also been a coincidence—several unrelated application outages that occurred in overlapping time periods. That may have allowed some existing biases (particularly around the involvement of a common cloud provider) to bubble to the surface, where other open-source intelligence appeared to correlate this view. The danger then becomes whether sources of intelligence that we rely on in an outage scenario are beneficial or simply support a confirmation bias.
Instrumented, telemetry-based views are required when attempting to diagnose or correlate the root cause of active issues on the Internet.
ThousandEyes Internet Outages Map, for example, is powered by the same collective intelligence data set behind ThousandEyes Internet Insights™ and is based on billions of ongoing measurements across thousands of global vantage points. In this case, it correctly showed no clear correlation between the three application outages because there was no clear correlation between them.
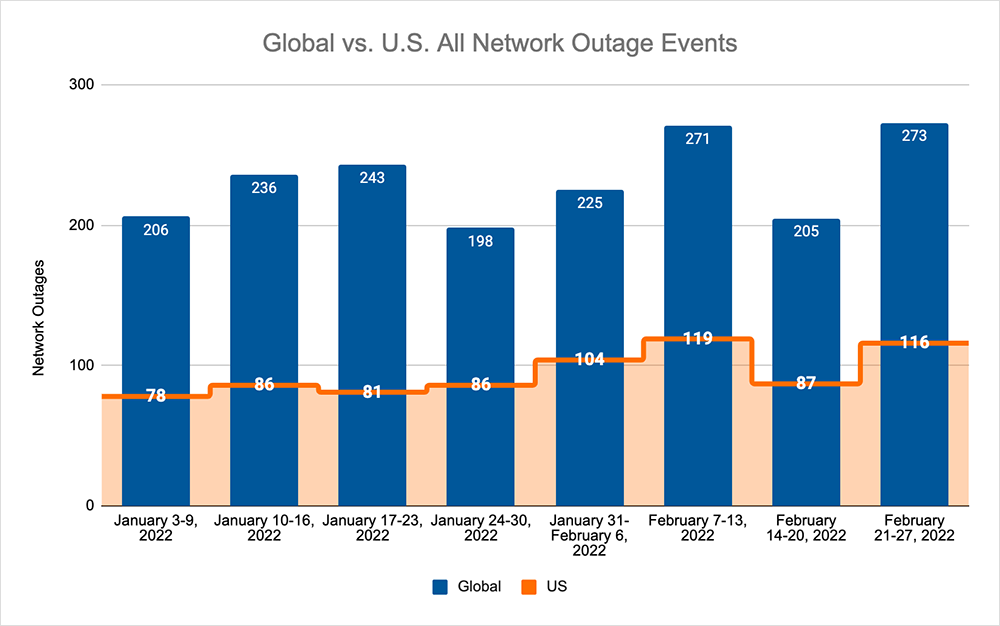
Taking a holistic look at outages, February came to close with similar levels of observed outages as the beginning of the month, which in turn means that the total of global outages increased by 33% when compared to the previous week. This increase was also reflected domestically where observed outages rose by a third, which is also a 33% increase when compared to the week prior. Despite this increase in observed outage levels, the U.S. outages only accounted for 42% of all global outages last week, which is exactly the same percentage as the previous week.
The lesson this week is that the Internet and application landscape is so complex that it’s possible to have two or three completely unrelated outages occur near simultaneously, without there being a common denominator (or, where the denominator is so heavily masked by layers of interdependency and complexity that simplistic correlation is not immediately possible).
We’ve become so accustomed to the way these outages manifest that when something doesn't fit the description, we still default to a point of view about what the root cause might be. It’s more important than ever to have instrumented transparency across the complete end-to-end application delivery chain, so as to have the best possible picture of what the root cause of a user-facing issue might be.









